ClickHouse のデータスキッピングインデックスを理解する
はじめに
ClickHouse のクエリパフォーマンスには多くの要因が影響します。ほとんどのシナリオにおいて重要となる要素は、クエリの WHERE 句条件を評価する際に、ClickHouse がプライマリキーを使用できるかどうかです。したがって、最も一般的なクエリパターンに適用できるプライマリキーを選択することは、効果的なテーブル設計において不可欠です。
しかし、プライマリキーをどれだけ慎重に調整したとしても、それを効率的に利用できないクエリのユースケースは必ず発生します。ユーザーは通常、時系列タイプのデータのために ClickHouse を利用しますが、その同じデータを顧客 ID、Web サイト URL、製品番号など、他のビジネス上のディメンションに基づいて分析したいと考えることがよくあります。そのような場合、WHERE 句条件を適用するために各カラム値の全スキャンが必要になる可能性があり、クエリパフォーマンスはかなり悪化します。そうした状況でも ClickHouse は比較的高速ではありますが、数百万から数十億の個々の値を評価する必要があるため、インデックスを利用しないクエリは、プライマリキーに基づくクエリと比べて実行が大幅に遅くなります。
従来のリレーショナルデータベースでは、この問題に対する 1 つのアプローチとして、テーブルに 1 つ以上の「セカンダリ」インデックスを作成する方法があります。これは b-tree 構造であり、行数を n としたとき、テーブルスキャンに相当する O(n) 時間ではなく O(log(n)) 時間で、ディスク上のすべての一致する行を見つけることを可能にします。しかし、この種のセカンダリインデックスは、ディスク上にインデックスへ追加すべき個々の行が存在しないため、ClickHouse(や他のカラム指向データベース)では機能しません。
その代わりに、ClickHouse は特定の状況下でクエリ速度を大幅に向上させることができる、異なる種類のインデックスを提供します。これらの構造は「スキップインデックス」と呼ばれ、一致する値が存在しないことが保証されているデータの大きなチャンクの読み取りを、ClickHouse がスキップできるようにします。
基本的な動作
ユーザーが Data Skipping Indexes を使用できるのは、MergeTree ファミリーのテーブルのみです。各データスキップインデックスには、主に次の 4 つの引数があります。
- インデックス名。インデックス名は、各パーティション内でインデックスファイルを作成するために使用されます。また、インデックスを削除したりマテリアライズしたりする際のパラメータとしても必要です。
- インデックス式。インデックス式は、インデックスに格納される値の集合を計算するために使用されます。これは、列、単純な演算子、および(インデックスタイプによって決定される)関数のサブセットの組み合わせにすることができます。
- TYPE。インデックスタイプは、各インデックスブロックの読み取りおよび評価をスキップできるかどうかを判断するための計算方法を制御します。
- GRANULARITY。各インデックス付きブロックは、GRANULARITY 個のグラニュールで構成されます。たとえば、主キーインデックスの粒度が 8192 行で、インデックスの粒度が 4 の場合、各インデックス付き「ブロック」は 32768 行になります。
ユーザーがデータスキップインデックスを作成すると、そのテーブルの各データパートディレクトリに 2 つの追加ファイルが作成されます。
skp_idx_{index_name}.idx— 順序付けされた式の値を格納しますskp_idx_{index_name}.mrk2— 対応するデータ列ファイル内のオフセットを格納します。
クエリを実行して関連する列ファイルを読み込む際に、WHERE 句のフィルタ条件の一部がスキップインデックス式と一致する場合、ClickHouse はインデックスファイルのデータを使用して、各関連データブロックを処理すべきか、あるいは(主キーの適用によってすでに除外されていないと仮定して)スキップできるかどうかを判定します。非常に単純化した例として、予測可能なデータが読み込まれた次のテーブルを考えます。
主キーを使わない単純なクエリを実行すると、my_value
カラムの 1 億件すべてのエントリがスキャンされます。
ここで、ごく基本的なスキップインデックスを追加します:
通常、スキップインデックスは新しく挿入されたデータにのみ適用されるため、インデックスを追加するだけでは上記のクエリには影響しません。
既存のデータにインデックスを付けるには、次のステートメントを使用します。
新しく作成したインデックスを用いてクエリを再実行します。
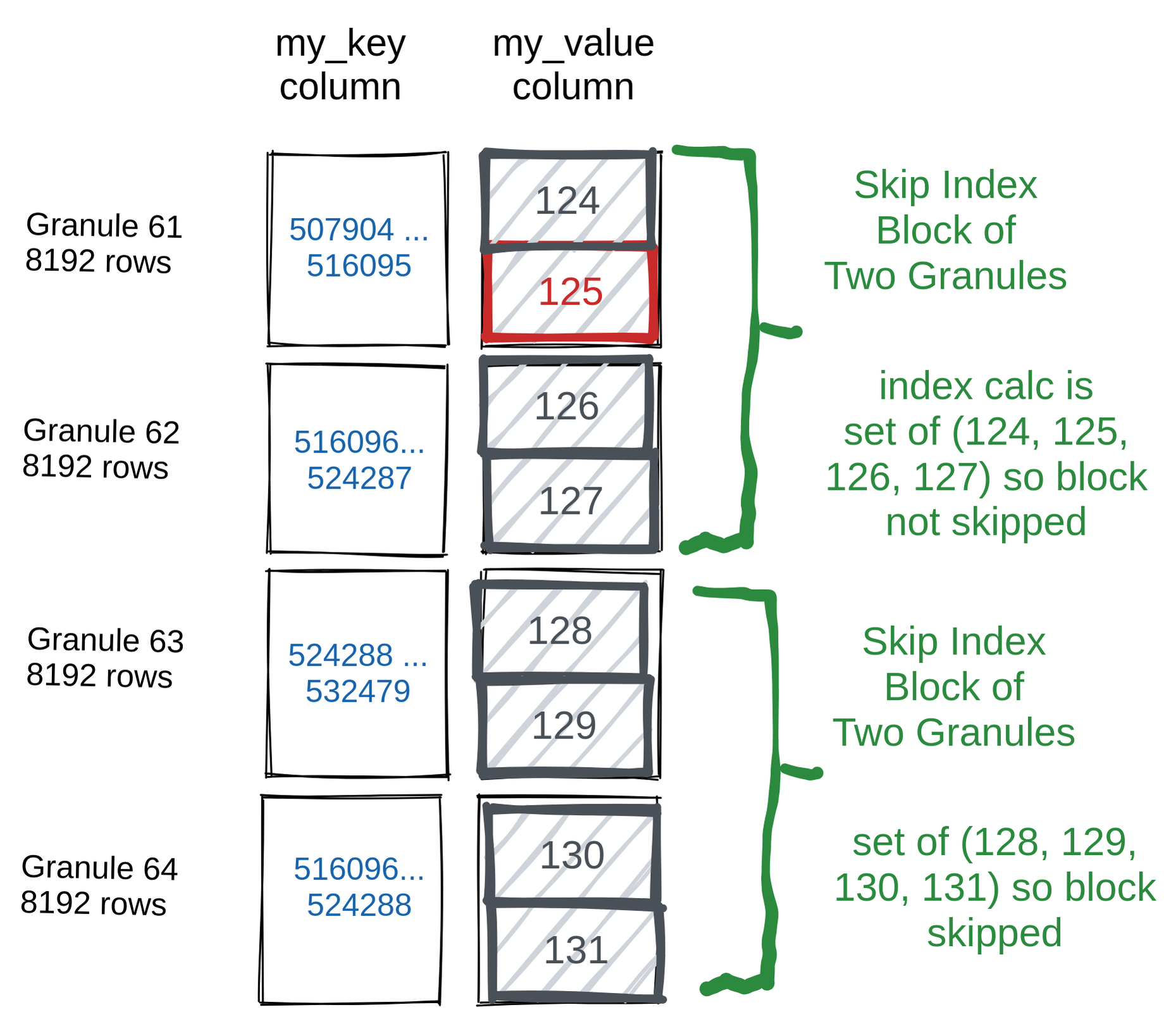
800メガバイトの1億行を処理する代わりに、ClickHouse は360キロバイトの32,768行だけを読み取り・解析しました -- 8,192行ずつのグラニュール4つ分です。
より視覚的に示すと、my_value が125の4,096行がどのように読み取られて選択され、その後続の行が
ディスクから読み出すことなくどのようにスキップされたかは、次の図のとおりです:
クエリ実行時にトレースを有効にすると、スキップインデックスの使用状況に関する詳細な情報を確認できます。
clickhouse-client では、send_logs_level を設定します:
これは、SQL クエリやテーブルインデックスのチューニングを行う際に有益なデバッグ情報を提供します。上記の例では、デバッグログから、スキップインデックスによって 2 つのグラニュールを除くすべてがスキップされたことが分かります。
スキップインデックスのタイプ
minmax
この軽量なインデックス型はパラメータを必要としません。インデックス式の最小値と最大値を各ブロックごとに保存します(式がタプルの場合は、タプルの各要素ごとに値を個別に保存します)。この型は、おおよそ値でソートされた状態になっている列に最適です。このインデックスタイプは、クエリ処理中に適用するコストが通常もっとも低くなります。
この種のインデックスが正しく動作するのはスカラー式またはタプル式のみであり、配列型やマップ型を返す式にはインデックスは決して適用されません。
set
この軽量なインデックスタイプは、ブロックごとの値集合の max_size(最大サイズ)を表す 1 つのパラメータを受け取ります(0 を指定すると、個別値の数は無制限になります)。この集合には、そのブロック内のすべての値が含まれます(値の数が max_size を超えた場合は空集合になります)。このインデックスタイプは、各グラニュール集合内のカーディナリティは低い(本質的に「固まっている」)が、全体としてはカーディナリティが高い列に対して有効に機能します。
このインデックスのコスト、性能、および有効性は、ブロック内のカーディナリティに依存します。各ブロックに多数のユニークな値が含まれる場合、大きなインデックス集合に対してクエリ条件を評価するのが非常に高コストになるか、あるいは max_size を超えた結果としてインデックスが空になり、インデックスが適用されない可能性があります。
text
自然言語や自由形式のテキスト検索(例: 大きなテキストカラム内で単語やフレーズを検索するようなワークロード)のために、ClickHouse は テキストインデックス(実際の転置インデックス)を提供します。
テキストインデックスは、高効率な全文検索のセマンティクスとトークン化された検索をサポートします。hasAnyToken や hasAllTokens といった検索関数に対して決定的なトークンのインデックス化と高いパフォーマンスを提供し、さらに一般的なテキスト検索関数もすべて最適化するため、全文検索クエリに対して推奨される選択肢です。
詳細はテキストインデックスのドキュメントを参照してください。こちら。
Bloom フィルター型
Bloom フィルターは、わずかな偽陽性を許容する代わりに、集合への所属 (メンバーシップ) を空間効率良くテストできるデータ構造です。スキップインデックスの場合、偽陽性は大きな問題にはなりません。唯一の不利益は、不要なブロックをいくつか読み込むことだけだからです。しかし、偽陽性が起こり得るということは、インデックス化された式が真になることが期待されるケースで使うべきであり、そうでないと有効なデータがスキップされる可能性があることを意味します。
Bloom フィルターは多数の離散値に対するテストをより効率的に処理できるため、テスト対象の値が多くなる条件式に適しています。特に、Bloom フィルターインデックスは配列に適用でき、配列のすべての値がテストされます。また、mapKeys や mapValues 関数を使ってキーまたは値を配列に変換することで、Map に対しても適用できます。
Bloom フィルターに基づくデータスキッピングインデックスの型は 3 種類あります:
-
基本的な bloom_filter。0〜1 の範囲で許容される「偽陽性」率を表す 1 つのオプションパラメータを取ります (指定されない場合は .025 が使用されます) 。
-
特化型の tokenbf_v1 (非推奨))。これは 3 つのパラメータを取り、いずれも使用される Bloom フィルターのチューニングに関係します。(1) フィルターのサイズ (バイト単位。大きいフィルターほど偽陽性が少なくなりますが、ストレージコストが増加します) 、(2) 適用されるハッシュ関数の数 (同様に、ハッシュ関数を増やすと偽陽性が減少します) 、(3) Bloom フィルターハッシュ関数のシード値です。これらのパラメータが Bloom フィルターの挙動にどのように影響するかの詳細は、こちら の計算機を参照してください。 このインデックスは String、FixedString、および Map のデータ型でのみ動作します。入力式は、英数字以外の文字で区切られた文字シーケンスに分割されます。たとえば、列の値
This is a candidate for a "full text" searchは、トークンThisisacandidateforfulltextsearchを含みます。これは、LIKE、EQUALS、IN、hasToken()などを用いた、長い文字列内の単語やその他の値を対象とする検索での利用を想定しています。例えば、自由形式のアプリケーションログ行を格納した列に対して、少数のクラス名や行番号を検索するといった用途が考えられます。 -
特化型の ngrambf_v1 (非推奨)。このインデックスは token インデックスと同様に動作します。Bloom フィルター設定の前に 1 つ追加のパラメータを取り、インデックス化する ngram のサイズを指定します。ngram とは任意の文字からなる長さ
nの文字列です。そのため、文字列A short stringに対して ngram サイズ 4 を指定した場合、次のようにインデックス化されます:
このインデックスもテキスト検索に有用であり、特に中国語のように単語の区切りがない言語に適しています。
全文検索ワークロードでは、非推奨の tokenbf_v1 または ngrambf_v1 インデックスではなく、専用の text index (全文検索用 Text index を参照) を推奨します。 text index は真の転置インデックスを提供し、トークンベースの Bloom フィルターインデックスと比べて、検索パフォーマンスが高く、動作の予測可能性が高く、柔軟性と性能にも優れています。
スキップインデックス関数
データスキップインデックスの主な目的は、頻繁に実行されるクエリで分析されるデータ量を制限することです。ClickHouse のデータは分析用途であるため、多くの場合これらのクエリのパターンには関数を用いた式が含まれます。したがって、スキップインデックスが効率的に動作するためには、一般的な関数と正しく連携する必要があります。これは次のいずれかの場合に起こります。
- データを挿入する際に、インデックスが関数式として定義されている場合(式の結果がインデックスファイルに格納される)、または
- クエリの処理時に、保存されたインデックス値に対して式が適用され、ブロックを除外するかどうかが判断される場合。
各種スキップインデックスは、それぞれのインデックス実装に適した、利用可能な ClickHouse 関数のサブセット上で動作します。対応する関数の一覧は こちら にあります。一般に、セットインデックスおよび Bloom フィルタベースのインデックス(別種のセットインデックス)は順序を持たないため、値の範囲とは相性が良くありません。対照的に、minmax インデックスは値の範囲との相性が特に良く、範囲同士が交差するかどうかの判定は非常に高速です。部分一致を行う関数である LIKE、startsWith、endsWith、hasToken の有効性は、使用されるインデックスタイプ、インデックス式、およびデータの特性によって異なります。
スキップインデックスの設定
スキップインデックスに適用できる設定は 2 つあります。
- use_skip_indexes(0 または 1、デフォルト 1)。すべてのクエリがスキップインデックスを効率的に利用できるわけではありません。特定のフィルタ条件によってほとんどのグラニュールが対象になってしまう場合、データスキップインデックスを適用すると不要な、場合によってはかなり大きなコストが発生します。どのスキップインデックスを使ってもメリットが見込めないクエリについては、この値を 0 に設定します。
- force_data_skipping_indices(インデックス名のカンマ区切りリスト)。この設定は、ある種の非効率なクエリを防ぐために使用できます。スキップインデックスを使用しない限りテーブルへのクエリが高コストになりすぎる状況では、この設定に 1 つ以上のインデックス名を指定することで、指定されたインデックスを使用していないクエリに対して例外を返すことができます。これにより、不適切なクエリがサーバーリソースを消費することを防げます。
スキップインデックスのベストプラクティス
スキップインデックスは必ずしも直感的ではなく、特に RDBMS の行ベースのセカンダリインデックスやドキュメントストアの転置インデックスに慣れたユーザーにはわかりにくいものです。効果を得るには、ClickHouse のデータスキップインデックスを適用することで、インデックスを計算するコストを上回るだけの十分なグラニュールの読み取りを回避する必要があります。重要なのは、インデックス化されたブロック内にある値が 1 回でも出現すると、そのブロック全体をメモリに読み込んで評価しなければならず、その場合インデックスのコストが無駄に発生してしまうという点です。
次のようなデータ分布を考えてみます:
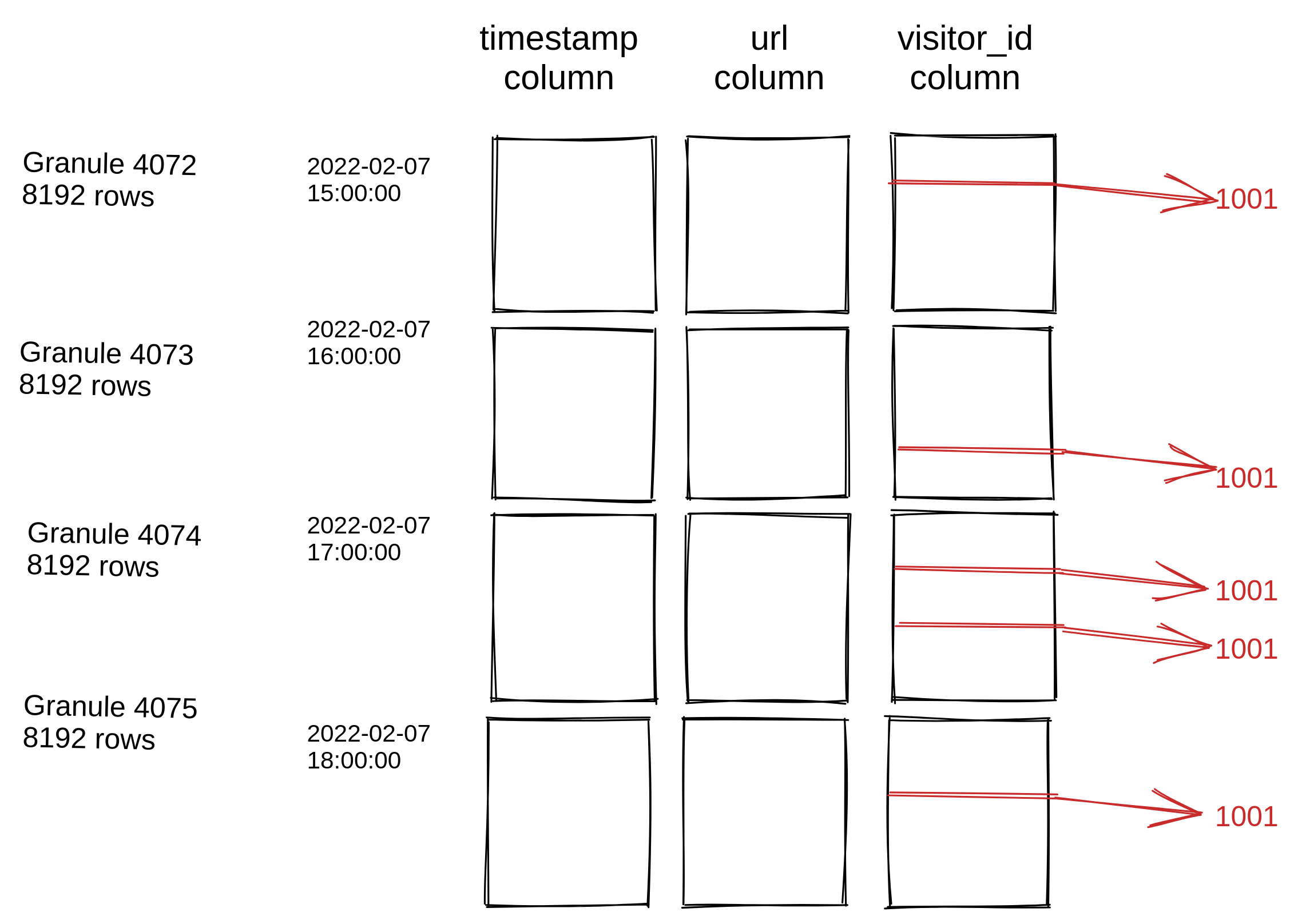
timestamp が primary/ORDER BY キーであり、visitor_id にインデックスがあるとします。次のクエリを考えてみます:
このようなデータ分布では、従来型のセカンダリインデックスは非常に有利に働きます。要求された visitor_id を持つ 5 行を見つけるために
32768 行すべてを読み取る代わりに、セカンダリインデックスには 5 行分の位置だけが格納され、それら 5 行だけがディスクから
読み込まれます。ClickHouse のデータスキップインデックスでは、状況はまったく逆になります。visitor_id 列の 32768 個すべての値が、
スキップインデックスの種類に関係なく評価されます。
したがって、キー列に単純にインデックスを追加して ClickHouse のクエリを高速化しようとする自然な発想は、多くの場合誤りです。 この高度な機能は、他の代替手段 (プライマリキーの変更 (「How to Pick a Primary Key」を参照)、projection の利用、マテリアライズドビューの利用など) を検討した後にのみ使用すべきです。データスキップインデックスが適切な場合であっても、インデックスとテーブルの両方について 注意深いチューニングが必要になることが多いです。
ほとんどの場合、有用なスキップインデックスには、プライマリキーと対象となる非プライマリ列/式との間に強い相関関係が必要です。
相関がない場合 (上の図のようなケース) には、数千件の値を含むブロック内の少なくとも 1 行がフィルタ条件を満たす可能性が高くなり、
スキップされるブロックはほとんどありません。対照的に、プライマリキー (時刻など) のある値の範囲が、潜在的なインデックス列
(テレビ視聴者の年齢など) の値と強く関連している場合、minmax タイプのインデックスは有用である可能性が高くなります。
データを挿入する際、ソートキー/ORDER BY キーに追加の列を含める、あるいはプライマリキーに関連する値が挿入時にまとまるように
バッチ挿入を行うことで、この相関関係を高められる可能性があることに注意してください。たとえば、特定の site_id に対するすべてのイベントを、
プライマリキーが多数のサイトからのイベントを含むタイムスタンプである場合でも、取り込み処理によってまとめてグループ化して
挿入できます。これにより、少数の site id しか含まない granule が多数作成されるため、特定の site_id 値で検索する際に
多くのブロックをスキップできるようになります。
スキップインデックスのもう 1 つの有力な候補は、高カーディナリティな式であり、どの個々の値もデータ中では比較的まばらにしか 出現しないようなケースです。例としては、API リクエスト内のエラーコードを追跡するオブザーバビリティプラットフォームが挙げられます。 データ中ではまれであっても、検索において特に重要となるエラーコードが存在するかもしれません。error_code 列に set スキップインデックスを 設定すれば、エラーを含まないブロックの大部分をバイパスできるため、エラーに特化したクエリの性能を大幅に向上させることができます。
最後に、最重要のベストプラクティスは、とにかくテストを繰り返すことです。b-tree セカンダリインデックスやドキュメント検索向けの 転置インデックスとは異なり、データスキップインデックスの挙動は簡単には予測できません。テーブルに追加すると、データを取り込む際と、 何らかの理由でインデックスの恩恵を受けないクエリの両方で、無視できないコストが発生します。常に実運用に近い種類のデータでテストを行い、 型、granularity サイズ、その他のパラメータのバリエーションも含めて検証する必要があります。テストによって、 単なる思考実験だけでは明らかにならないパターンや落とし穴が明らかになることが多いでしょう。
