ClickHouseがクエリを並列実行する方法
ClickHouseは速度のために構築されています。利用可能なすべてのCPUコアを使用し、処理レーン全体にデータを分散し、しばしばハードウェアを限界近くまで押し上げることで、高度に並列な方法でクエリを実行します。
このガイドでは、ClickHouseでクエリの並列処理がどのように機能するか、そして大規模なワークロードでパフォーマンスを向上させるためにそれをどのように調整または監視できるかを説明します。
ここでは、主要な概念を説明するために、uk_price_paid_simpleデータセットに対する集約クエリを使用します。
ステップバイステップ:ClickHouseが集計クエリを並列化する方法
ClickHouseが①テーブルのプライマリキーにフィルターを持つ集計クエリを実行する際、②プライマリインデックスをメモリにロードして、③どのグラニュールを処理する必要があり、どれを安全にスキップできるかを識別します:
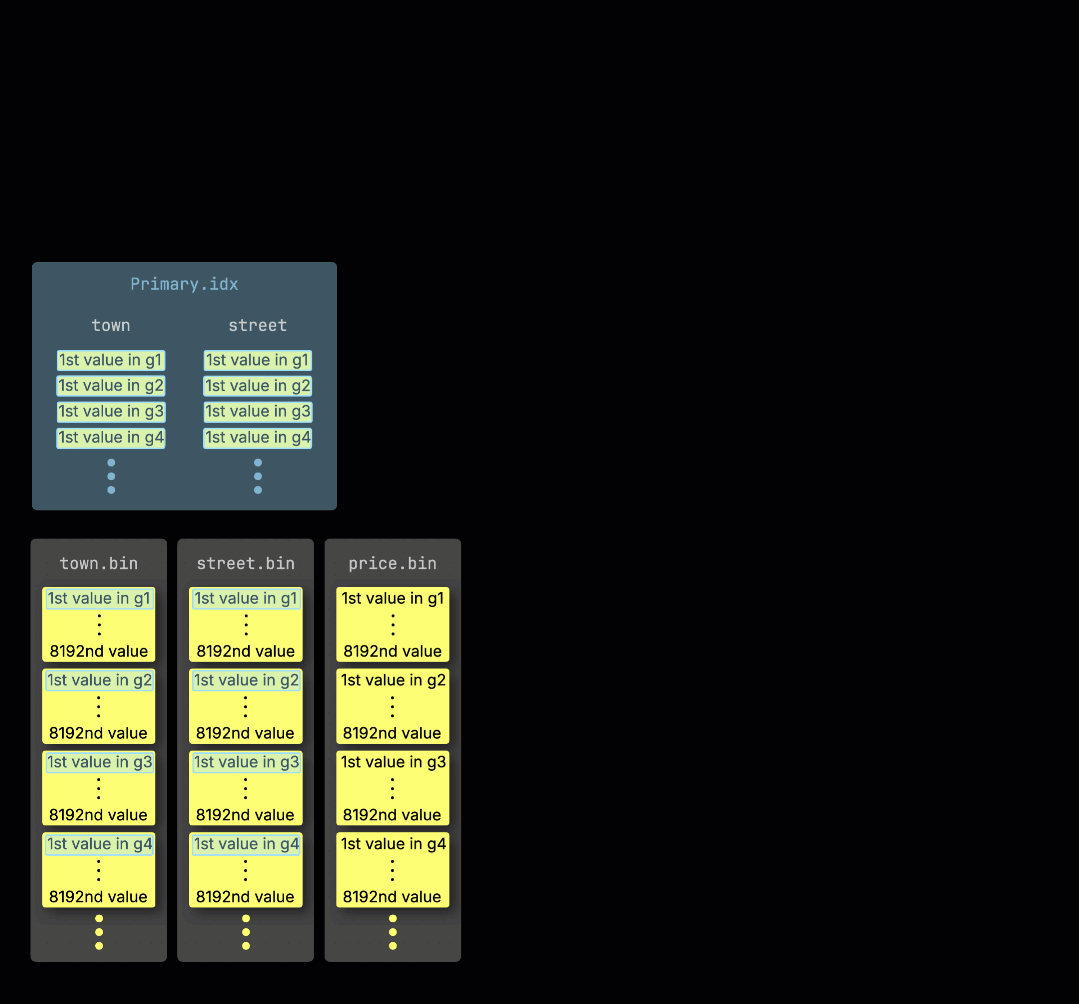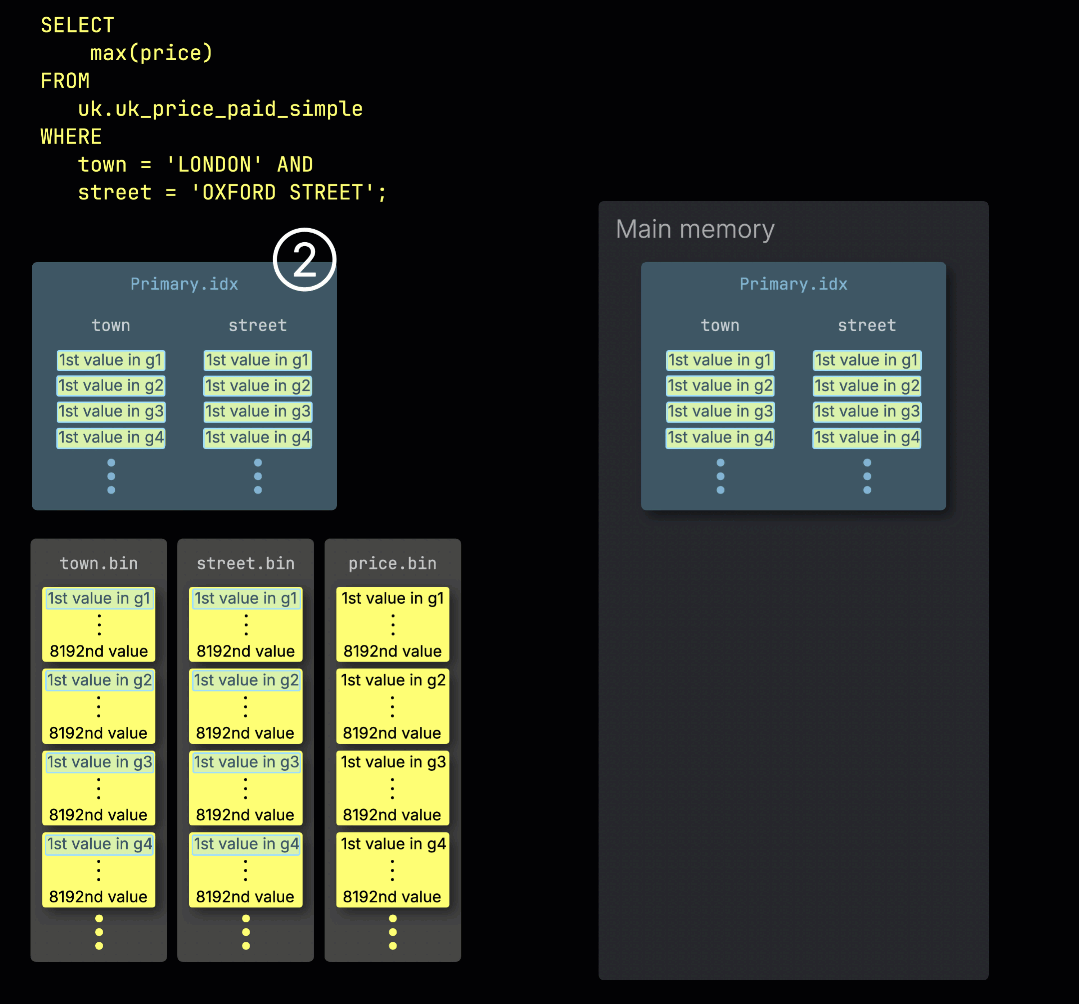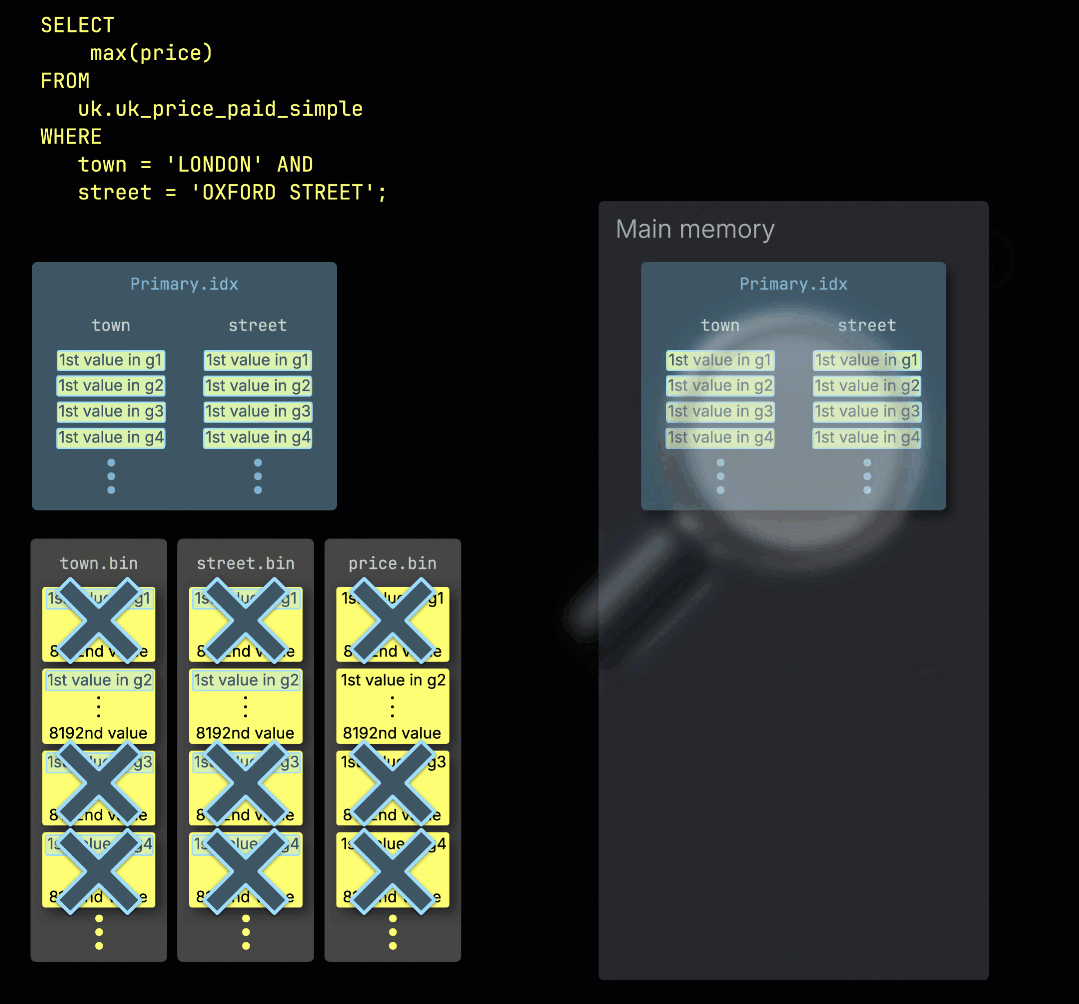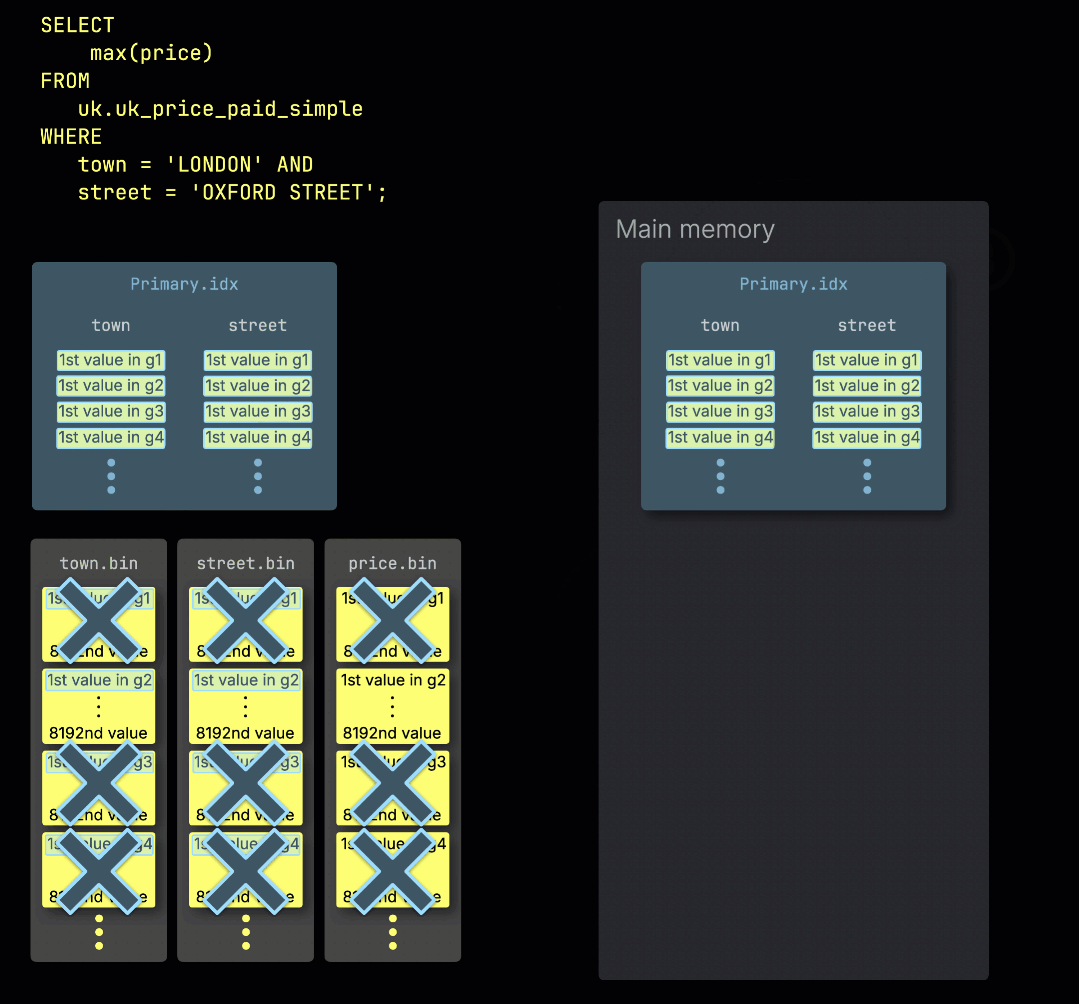
処理レーン全体への作業の分散
選択されたデータは、n個の並列処理レーン全体に動的に分散され、データをブロックごとにストリーミングしながら処理して最終結果を生成します:
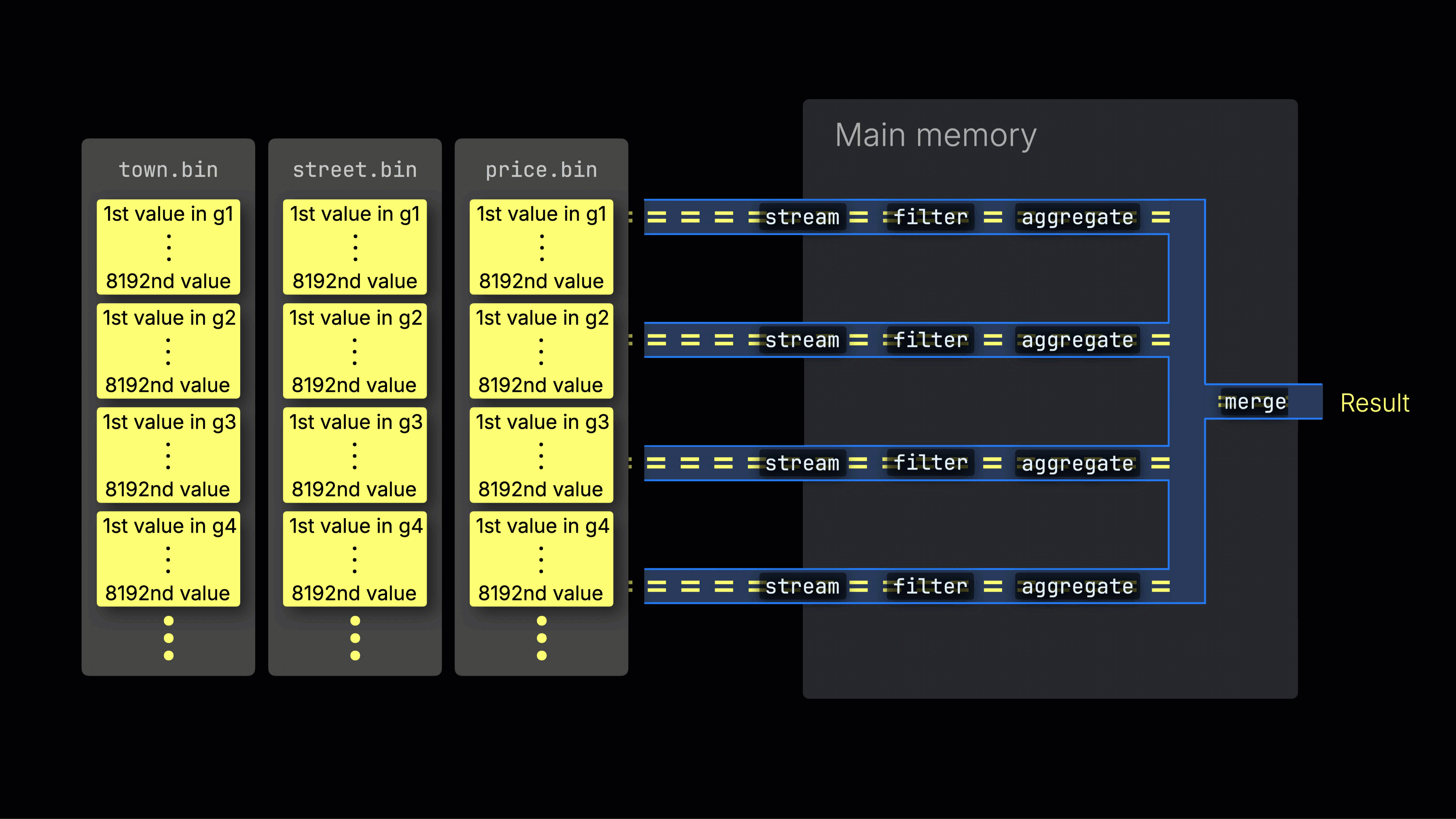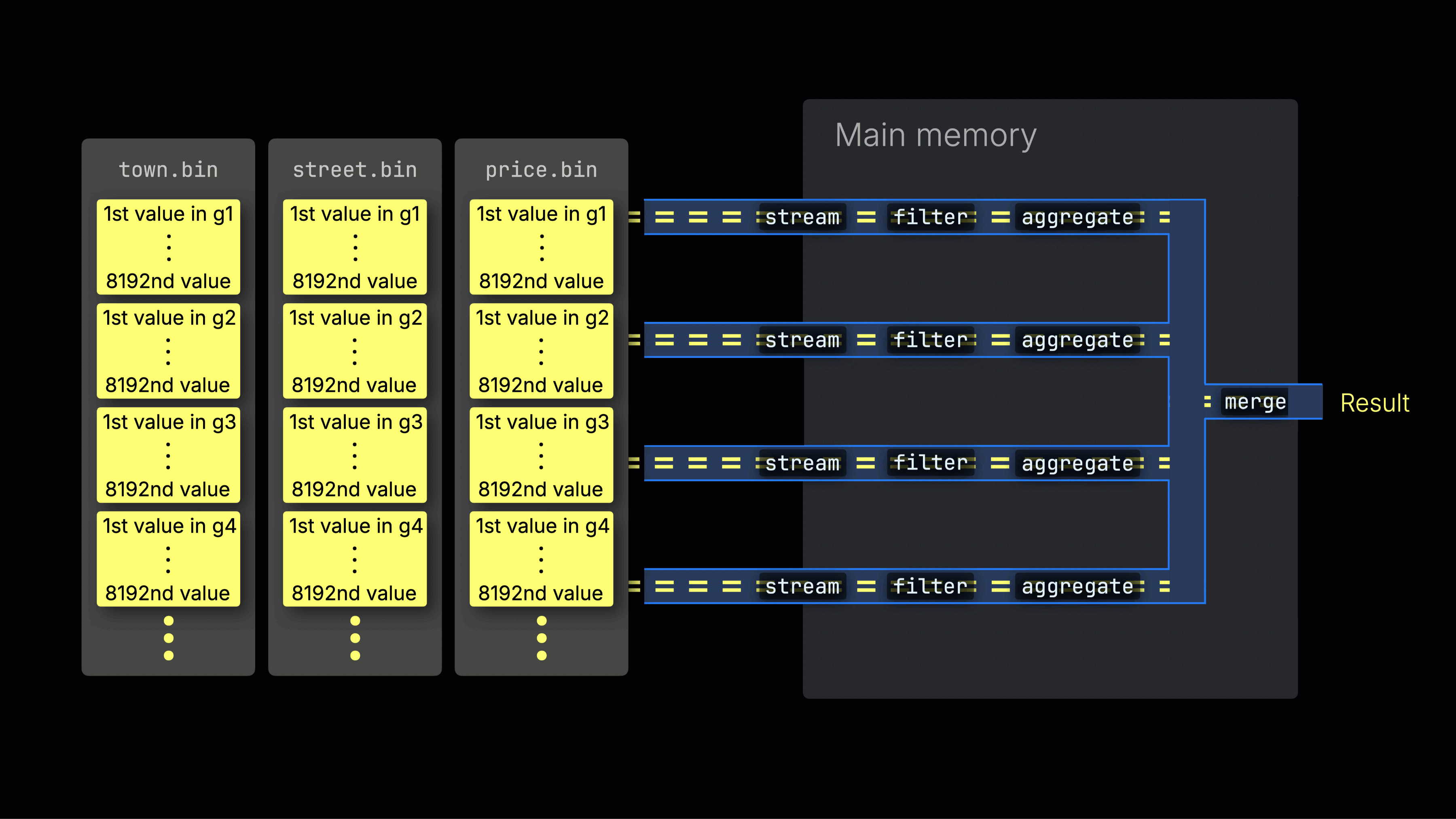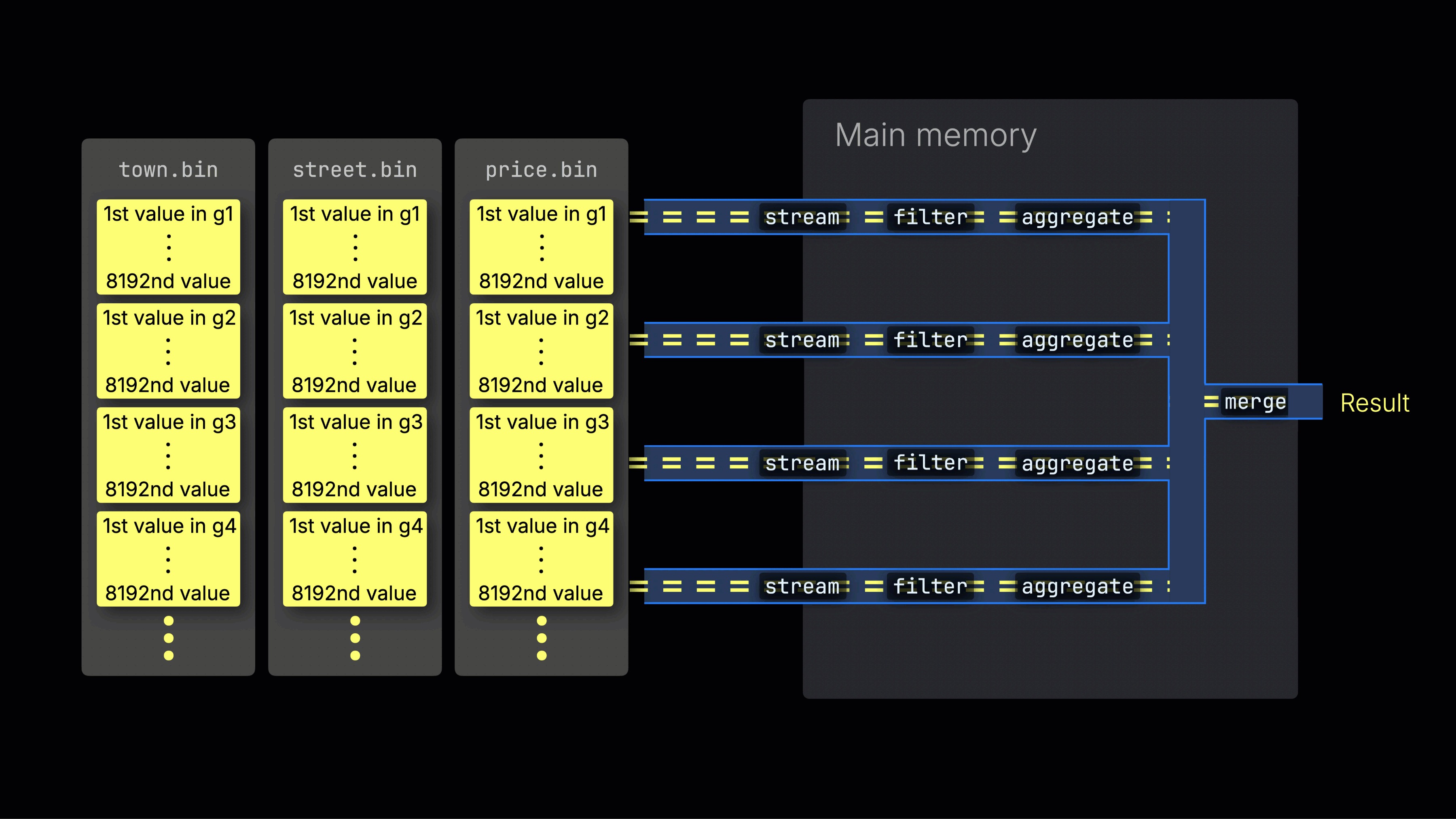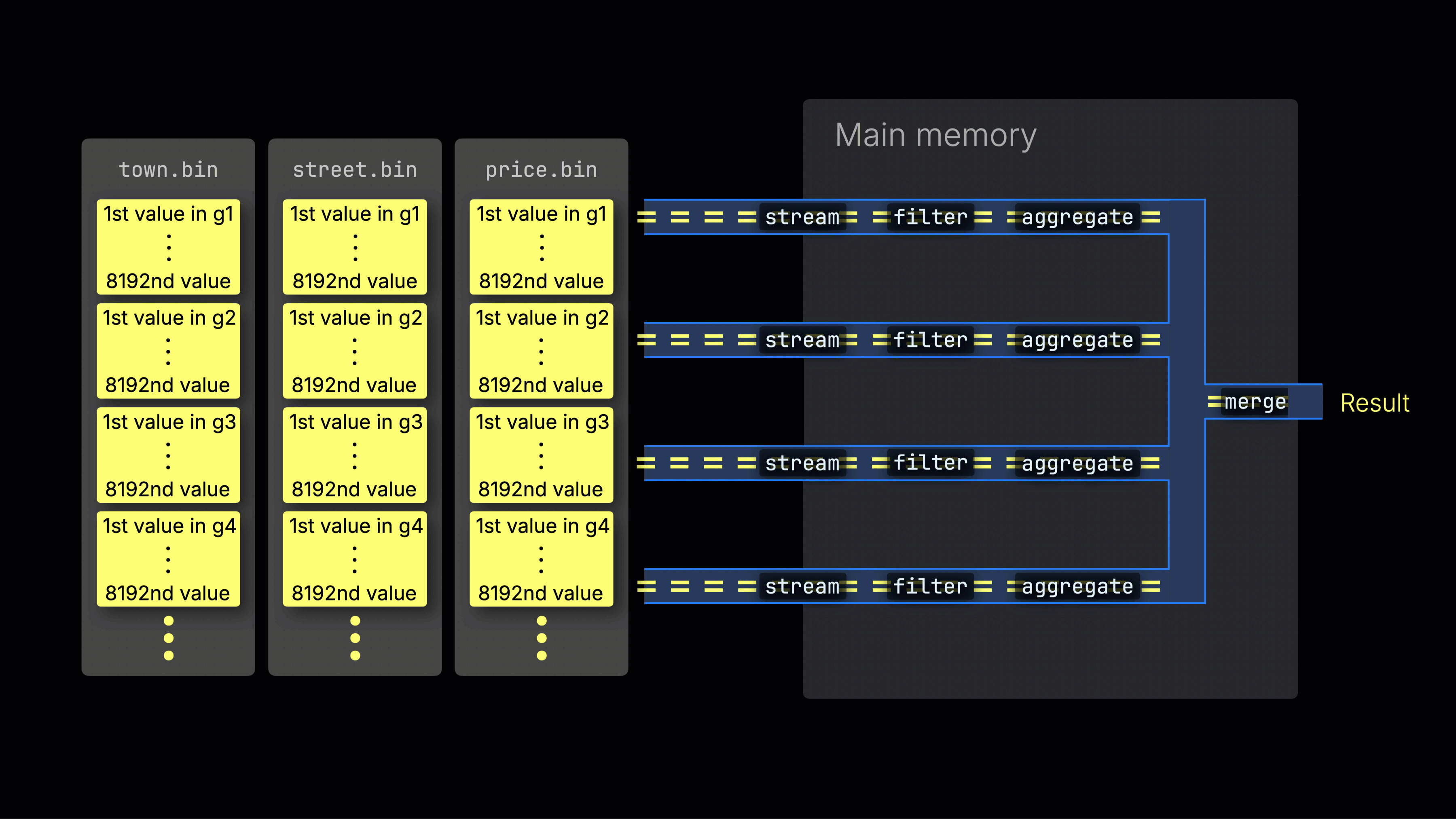
n個の並列処理レーンの数はmax_threads設定によって制御され、デフォルトではサーバー上のClickHouseで利用可能な単一のCPUのコア(スレッド)数と一致します。上記の例では、4コアを想定しています。
8コアを持つマシンでは、より多くのレーンが並列にデータを処理するため、クエリ処理のスループットはほぼ2倍になります(ただし、メモリ使用量もそれに応じて増加します):
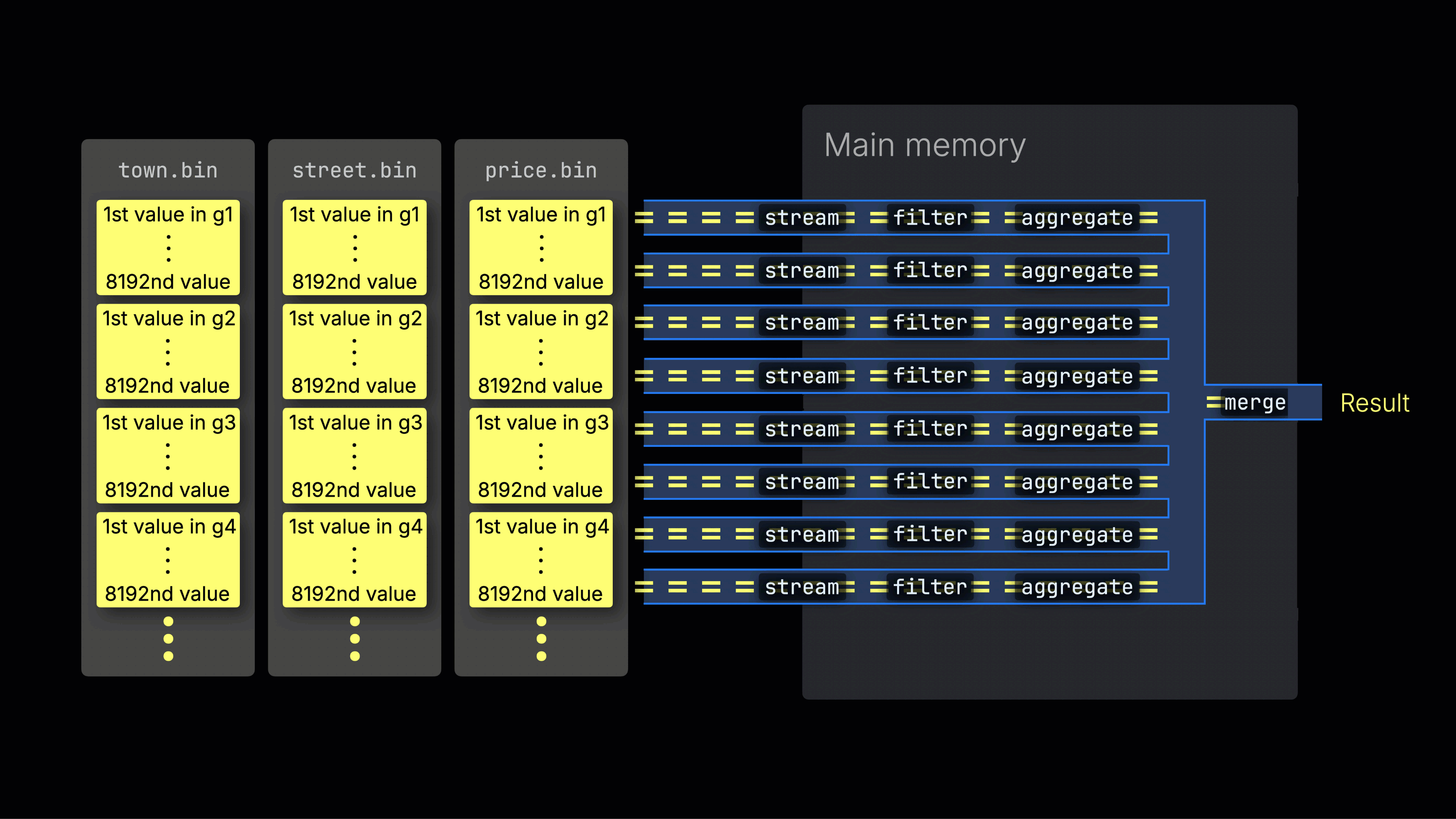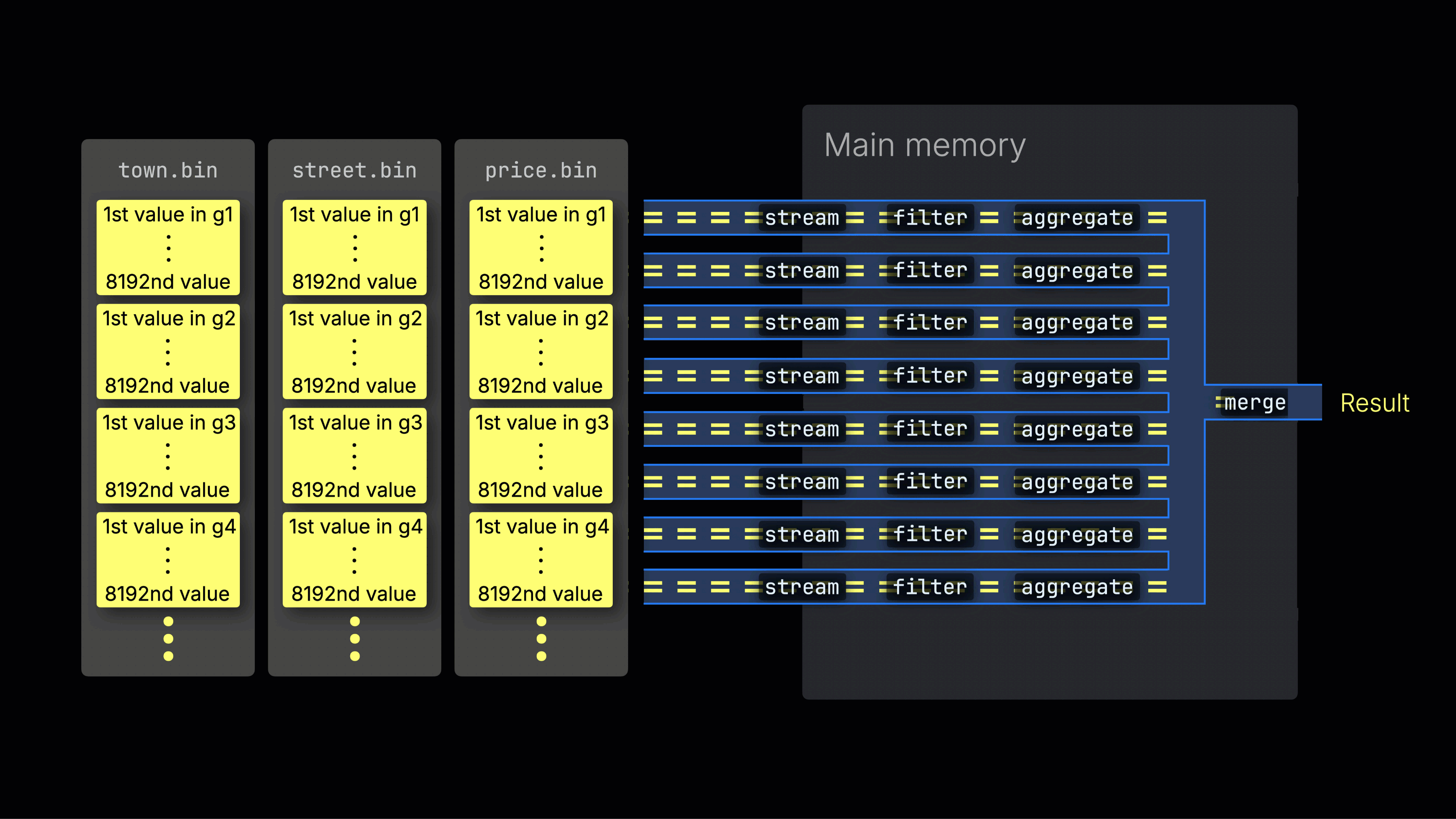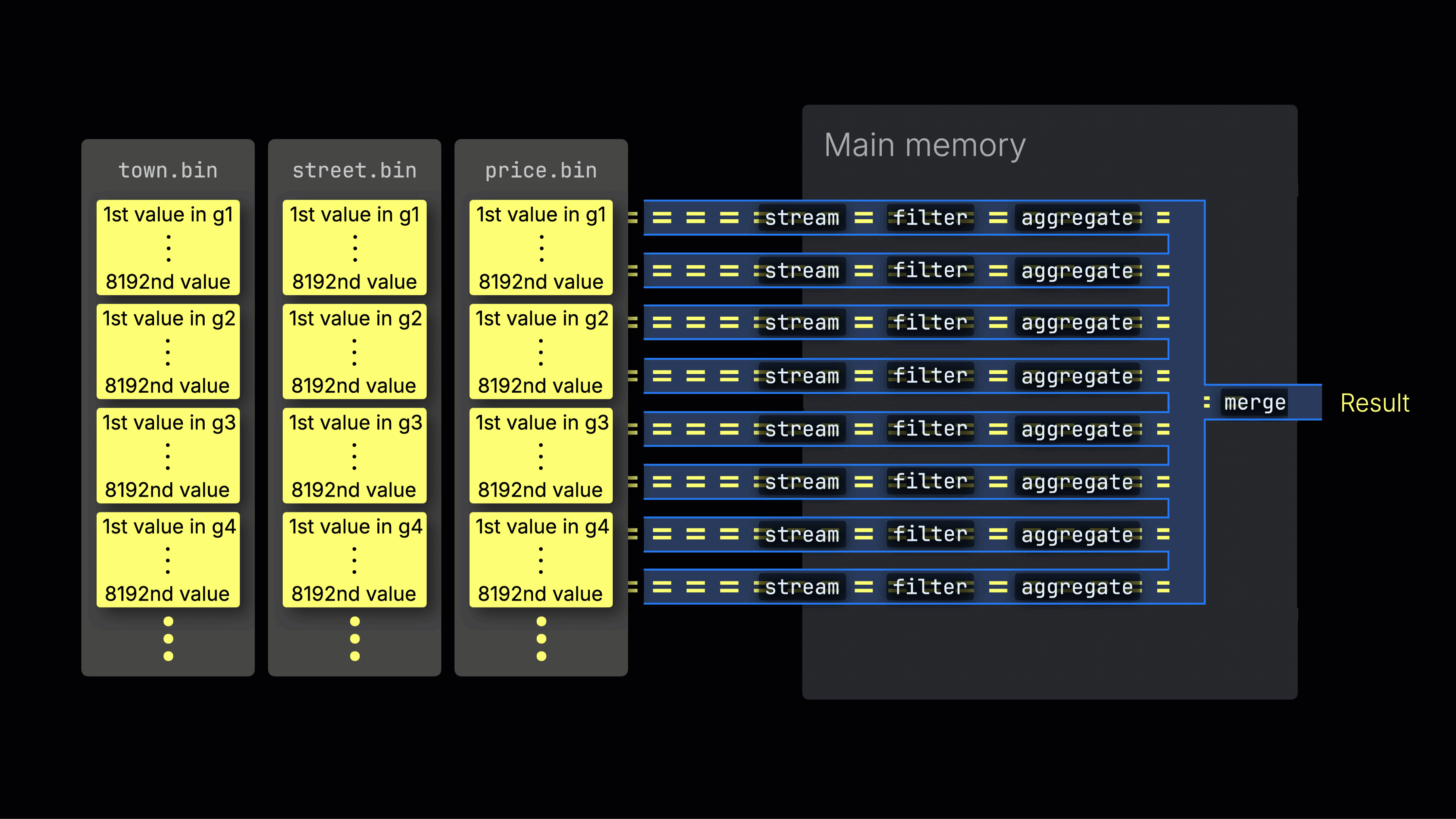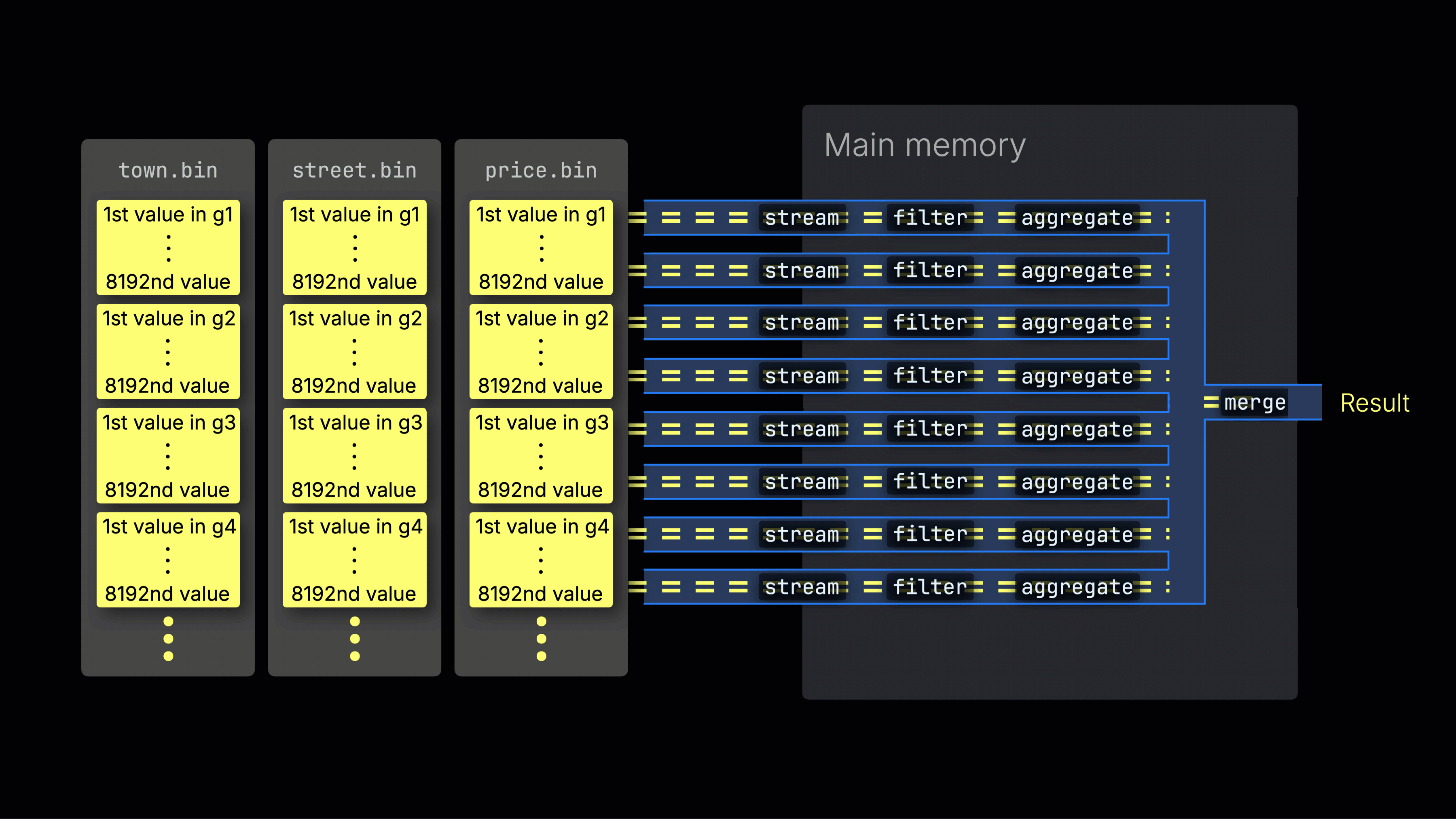
効率的なレーン分散は、CPU使用率を最大化し、総クエリ時間を短縮するために重要です。
シャーディングされたテーブルでのクエリ処理
テーブルデータがシャードとして複数のサーバーに分散されている場合、各サーバーは並列にそのシャードを処理します。各サーバー内では、上記で説明したように、並列処理レーンを使用してローカルデータが処理されます:
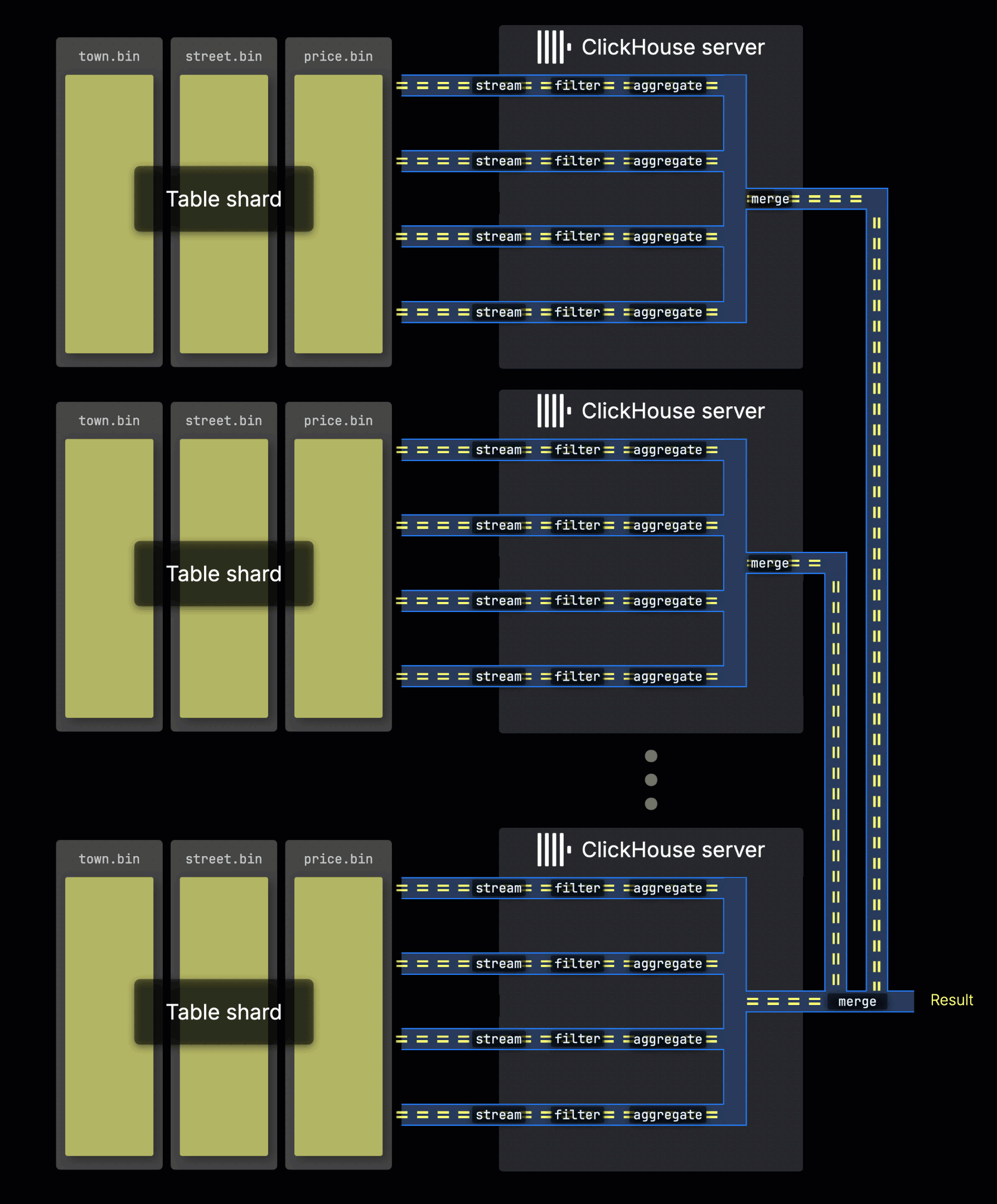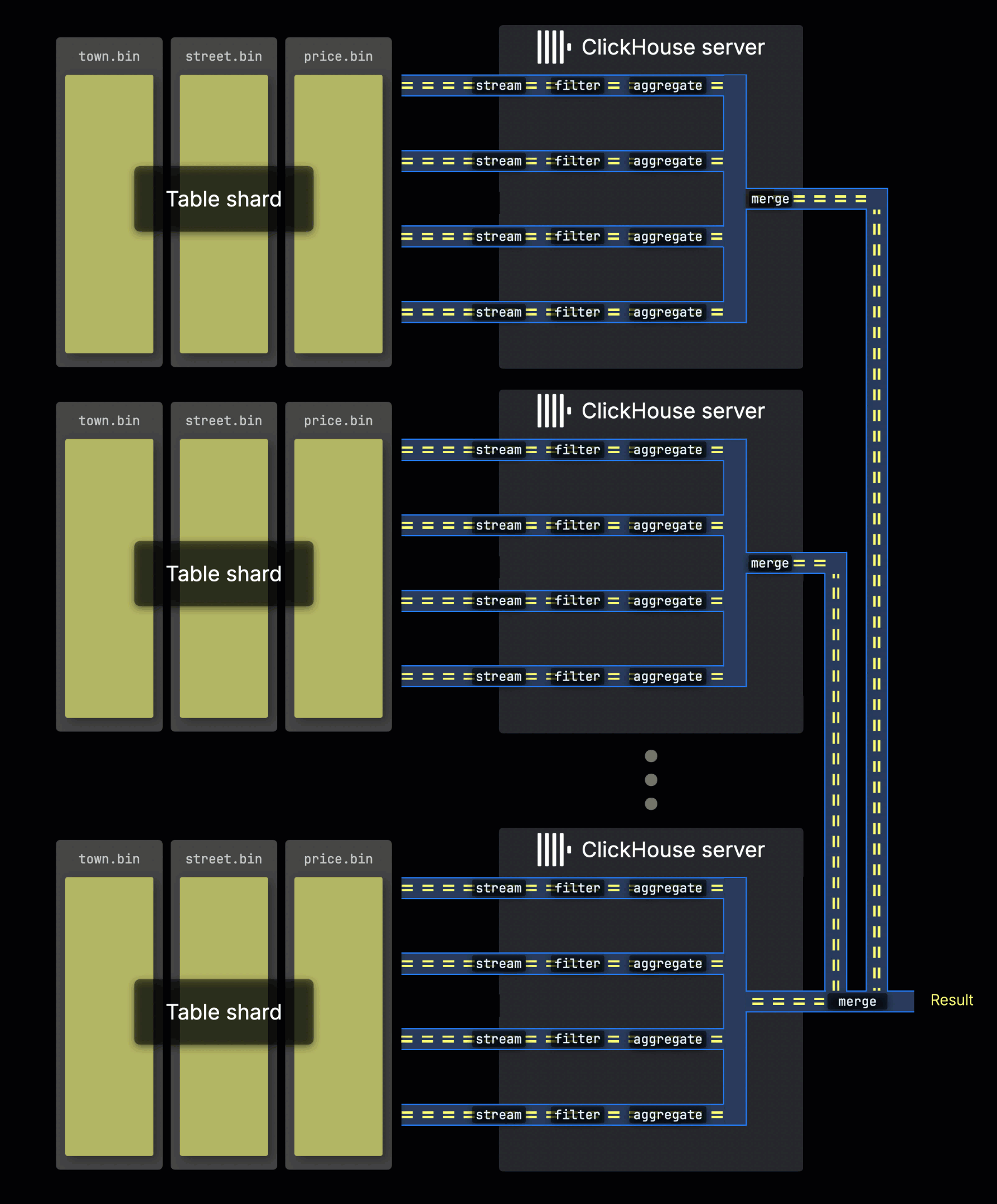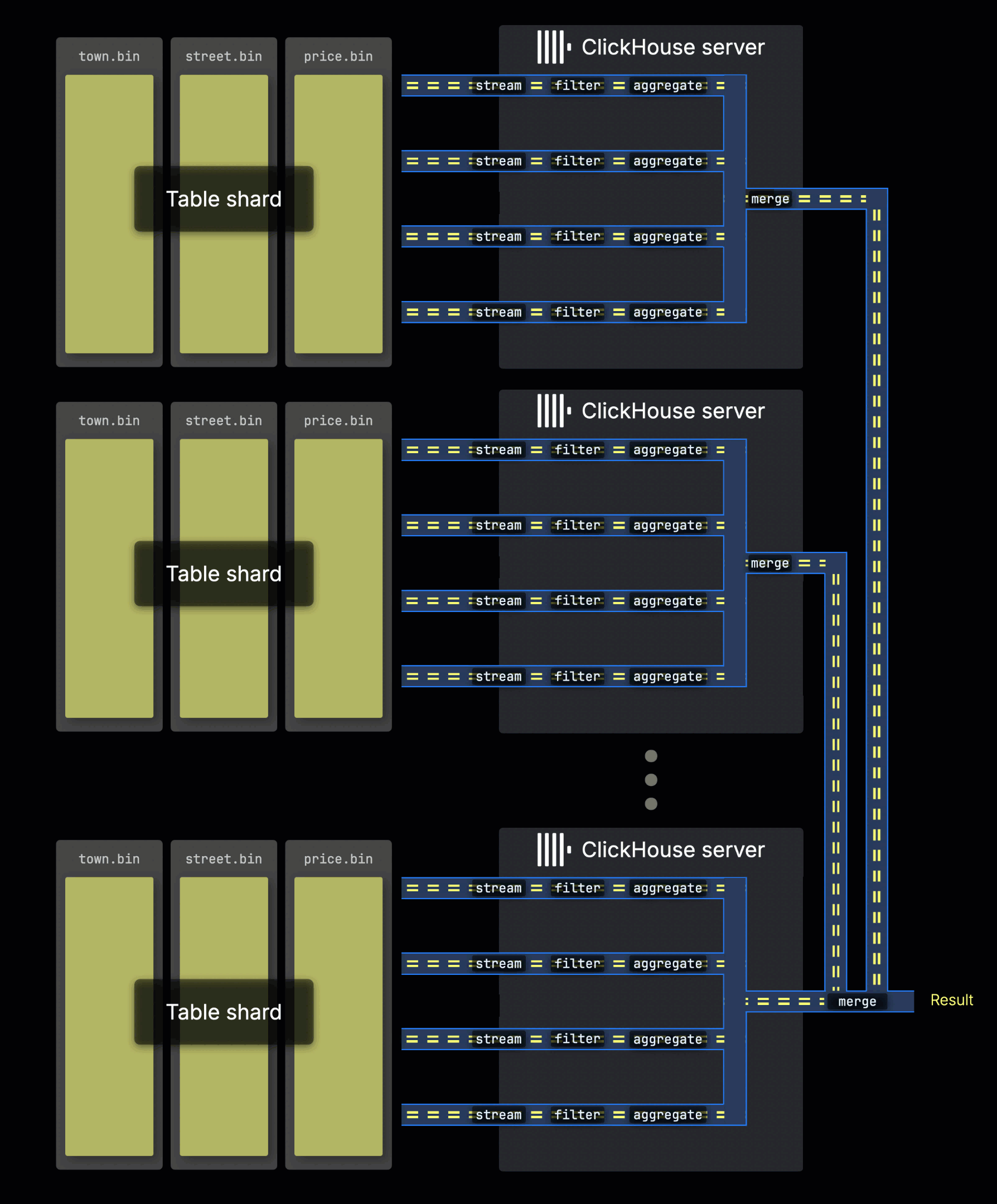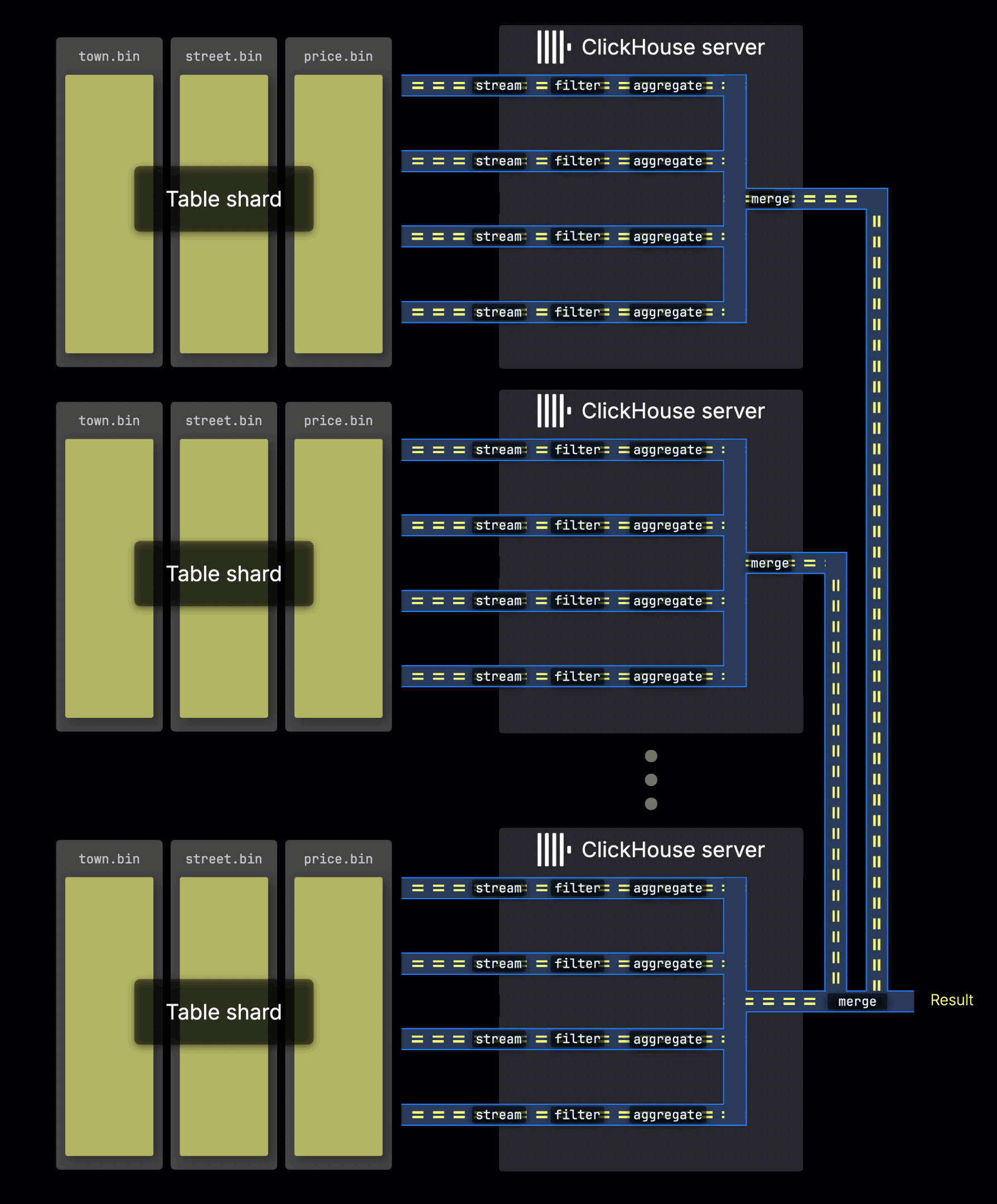
最初にクエリを受信したサーバーは、シャードからのすべてのサブ結果を収集し、それらを最終的なグローバル結果に結合します。
シャード全体にクエリ負荷を分散することで、特に高スループット環境での並列処理の水平スケーリングが可能になります。
ClickHouse Cloudでは、この同じ並列処理が並列レプリカを通じて実現されます。これは、シェアードナッシングクラスターのシャードと同様に機能します。各ClickHouse Cloudレプリカ(ステートレスコンピュートノード)は、データの一部を並列に処理し、独立したシャードと同じように最終結果に貢献します。
クエリの並列処理の監視
これらのツールを使用して、クエリが利用可能なCPUリソースを完全に活用していることを確認し、そうでない場合に診断します。
これは59個のCPUコアを持つテストサーバーで実行しており、ClickHouseがクエリの並列処理を完全に示すことができます。
例のクエリがどのように実行されるかを観察するために、集計クエリ中にすべてのトレースレベルのログエントリを返すようにClickHouseサーバーに指示できます。このデモンストレーションでは、クエリの述語を削除しました。そうでなければ、3つのグラニュールしか処理されず、ClickHouseが複数の並列処理レーンを使用するのに十分なデータではありません:
以下のことがわかります:
- ① ClickHouseは3つのデータ範囲にわたって3,609個のグラニュール(トレースログでマークとして示される)を読み取る必要があります。
- ② 59個のCPUコアで、この作業を59個の並列処理ストリーム(レーンごとに1つ)に分散します。
あるいは、EXPLAIN句を使用して、集計クエリの物理演算子プラン(「クエリパイプライン」とも呼ばれる)を検査できます:
注:上記の演算子プランを下から上に読んでください。各行は物理実行プランのステージを表し、下部のストレージからのデータ読み取りから始まり、上部の最終処理ステップで終わります。× 59でマークされた演算子は、59個の並列処理レーン全体で重複しないデータ領域で同時に実行されます。これはmax_threadsの値を反映しており、クエリの各ステージがCPUコア全体でどのように並列化されているかを示しています。
ClickHouseの埋め込みWeb UI(/playエンドポイントで利用可能)は、上記の物理プランをグラフィカル視覚化としてレンダリングできます。この例では、max_threadsを4に設定して視覚化をコンパクトに保ち、4つの並列処理レーンのみを表示しています:

注:視覚化を左から右に読んでください。各行は、フィルタリング、集計、最終処理ステージなどの変換を適用しながら、データをブロックごとにストリーミングする並列処理レーンを表します。この例では、max_threads = 4設定に対応する4つの並列レーンを確認できます。
処理レーン全体の負荷分散
上記の物理プランのResize演算子は、処理レーン全体でデータブロックストリームを再パーティション化して再分散し、均等に活用されるようにすることに注意してください。この再バランシングは、データ範囲がクエリ述語に一致する行数が異なる場合に特に重要です。そうでなければ、一部のレーンが過負荷になり、他のレーンがアイドル状態になる可能性があります。作業を再分散することで、高速なレーンが効果的に低速なレーンを支援し、全体的なクエリランタイムを最適化します。
max_threadsが常に尊重されない理由
上記で述べたように、n個の並列処理レーンの数はmax_threads設定によって制御され、デフォルトではサーバー上のClickHouseが利用可能なCPUコアの数と同じ値になります:
ただし、max_threads の値は、処理対象として選択されたデータ量に応じて無視される場合があります:
上記の演算子プラン抽出に示されているように、max_threadsが59に設定されていても、ClickHouseはデータをスキャンするために30個の同時ストリームのみを使用します。
次にクエリを実行してみましょう:
上記の出力に示されているように、クエリは231万行を処理し、13.66MBのデータを読み取りました。これは、インデックス分析フェーズ中に、ClickHouseが処理用に282個のグラニュールを選択したためです。各グラニュールには8,192行が含まれており、合計で約231万行になります:
設定されたmax_threads値に関係なく、ClickHouseは、それらを正当化するのに十分なデータがある場合にのみ、追加の並列処理レーンを割り当てます。max_threadsの「max」は上限を指し、使用されるスレッドの保証された数ではありません。
「十分なデータ」が何を意味するかは、主に2つの設定によって決定されます。これらは、各処理レーンが処理すべき最小行数(デフォルトで163,840)と最小バイト数(デフォルトで2,097,152)を定義します:
シェアードナッシングクラスターの場合:
共有ストレージを持つクラスター(例:ClickHouse Cloud)の場合:
- merge_tree_min_rows_for_concurrent_read_for_remote_filesystem
- merge_tree_min_bytes_for_concurrent_read_for_remote_filesystem
さらに、読み取りタスクサイズの厳格な下限があり、次によって制御されます:
本番環境でこれらの設定を変更することは推奨しません。ここでは、max_threadsが常に実際の並列度を決定するわけではない理由を説明するための例としてのみ示しています。
デモンストレーション目的で、最大同時実行性を強制するためにこれらの設定をオーバーライドした物理プランを検査してみましょう:
現在、ClickHouseはデータをスキャンするために59個の同時ストリームを使用し、設定されたmax_threadsを完全に尊重しています。
これは、小さなデータセットでのクエリに対して、ClickHouseが意図的に同時実行性を制限することを示しています。設定のオーバーライドは、テスト専用に使用してください。本番環境では使用しないでください。非効率的な実行やリソース競合につながる可能性があります。
重要なポイント
- ClickHouseは
max_threadsに結び付けられた処理レーンを使用してクエリを並列化します。 - 実際のレーン数は、処理用に選択されたデータのサイズに依存します。
EXPLAIN PIPELINEとトレースログを使用して、レーン使用を分析します。
詳細情報の入手先
ClickHouseがクエリを並列に実行する方法と、大規模でどのように高いパフォーマンスを実現するかについてさらに深く掘り下げたい場合は、次のリソースを探索してください:
-
クエリ処理レイヤー – VLDB 2024論文(Web版) - スケジューリング、パイプライニング、演算子設計を含む、ClickHouseの内部実行モデルの詳細な分解。
-
部分集計状態の説明 - 部分集計状態が処理レーン全体で効率的な並列実行を可能にする方法についての技術的な詳細。
-
すべてのClickHouseクエリ処理ステップを詳細に説明するビデオチュートリアル:
