PREWHERE 最適化はどのように動作しますか?
PREWHERE 句 は、ClickHouse におけるクエリ実行の最適化機構です。不要なデータの読み取りを回避し、フィルタ条件に含まれない列をディスクから読み込む前に関係のないデータを除外することで、I/O を削減しクエリ速度を向上させます。
このガイドでは、PREWHERE の仕組み、その効果の測定方法、そして最適なパフォーマンスを得るためのチューニング手法について説明します。
PREWHERE 最適化なしの場合のクエリ処理
まず、uk_price_paid_simple テーブルに対するクエリが PREWHERE を使わずにどのように処理されるかを示します。

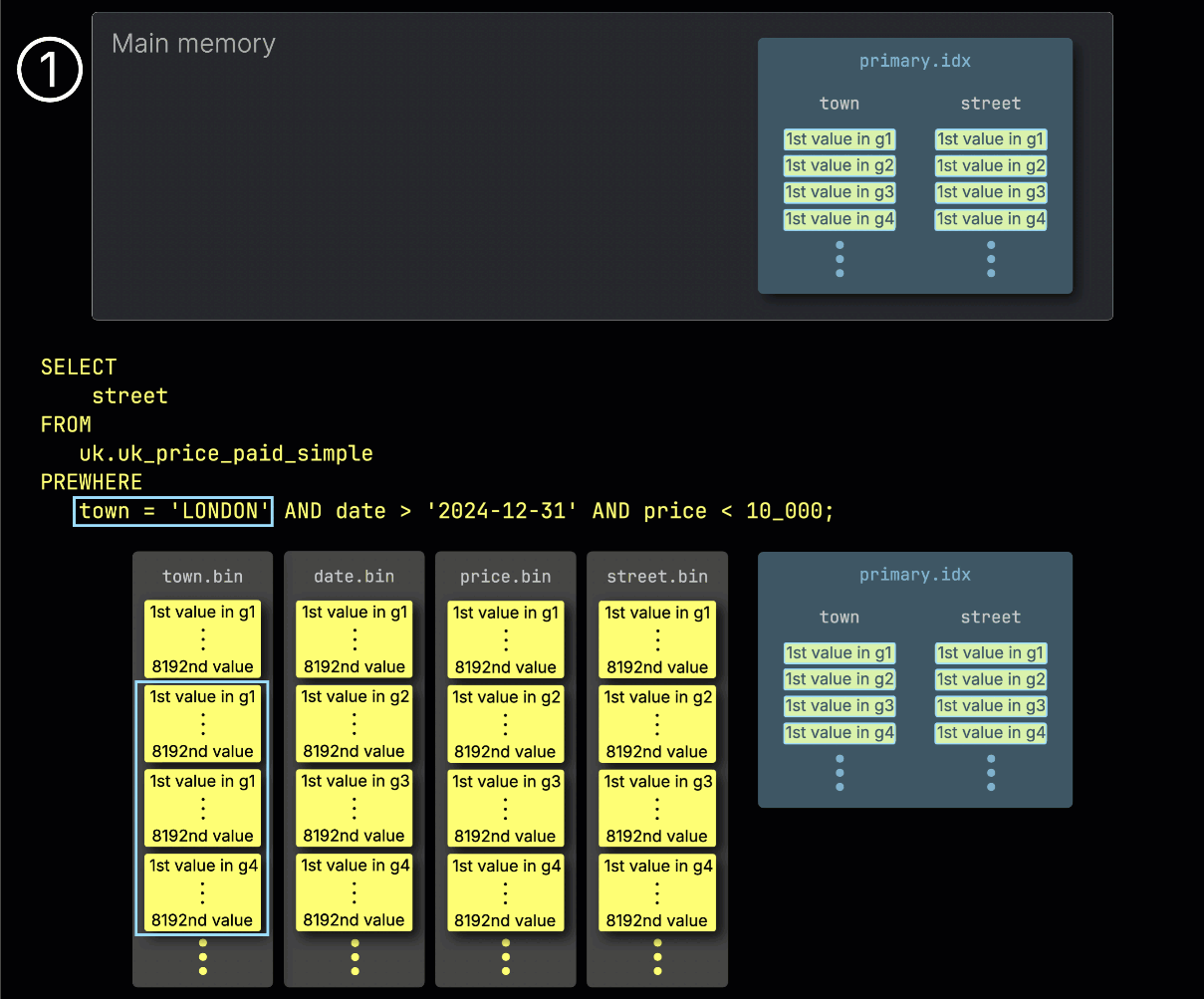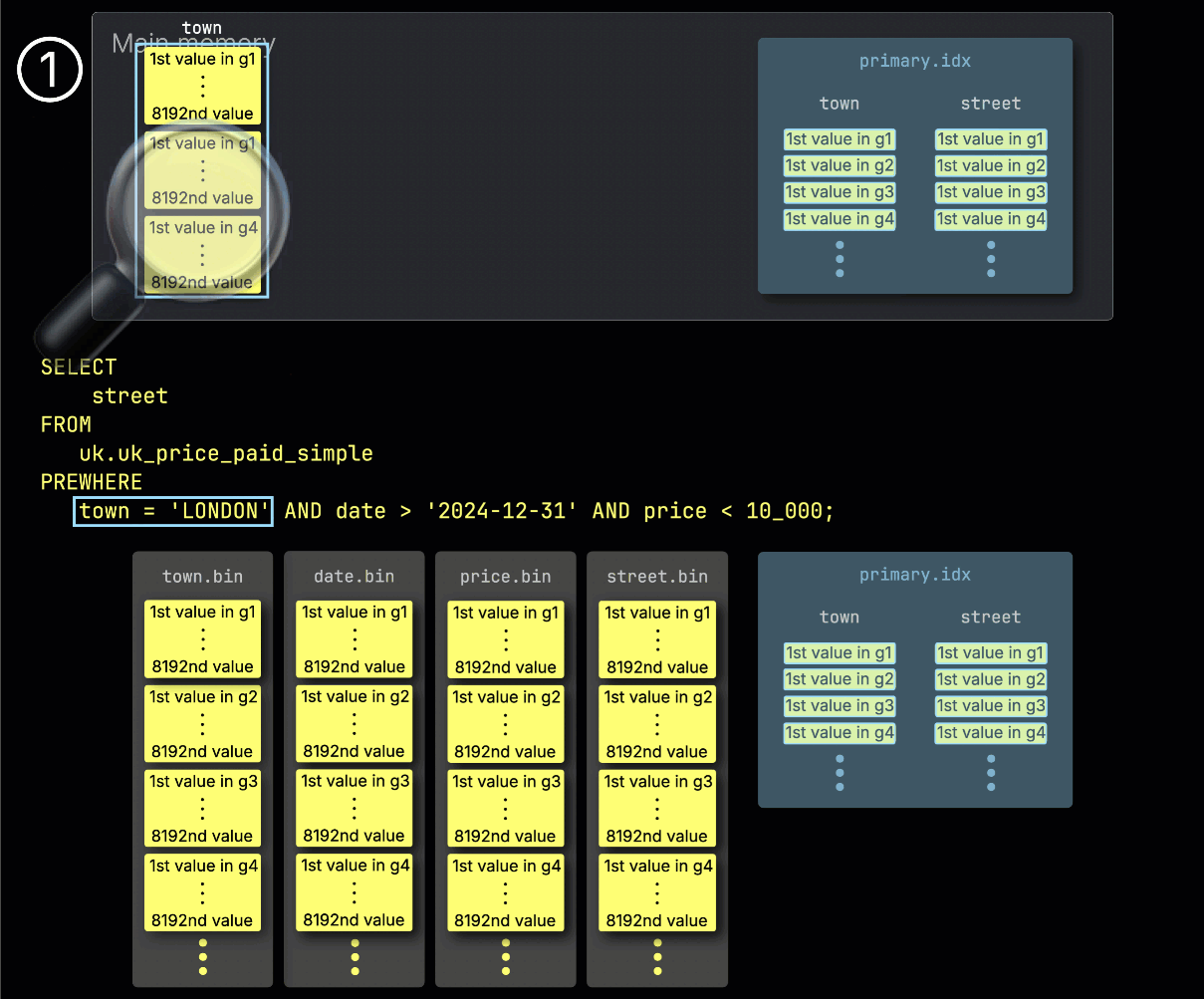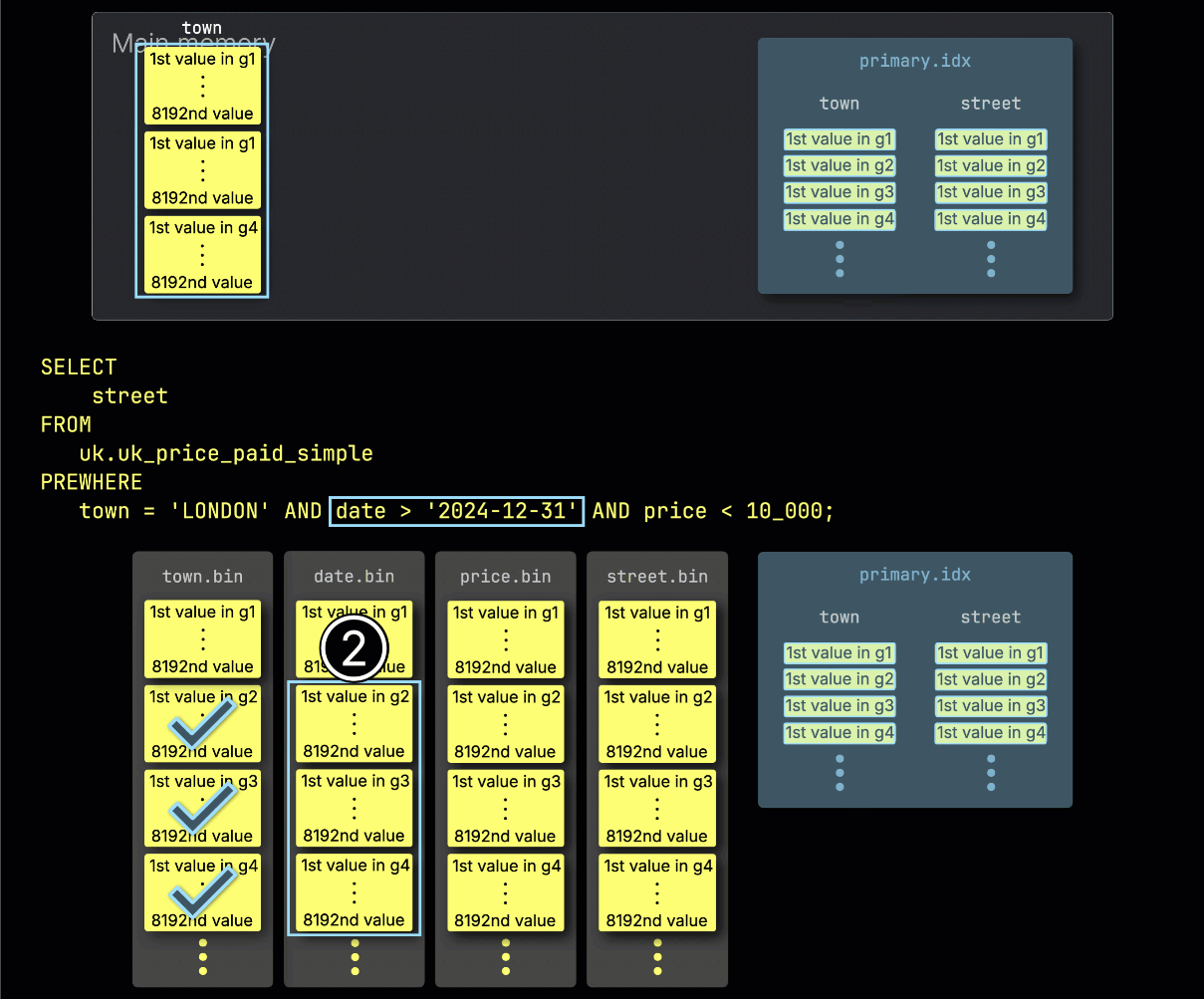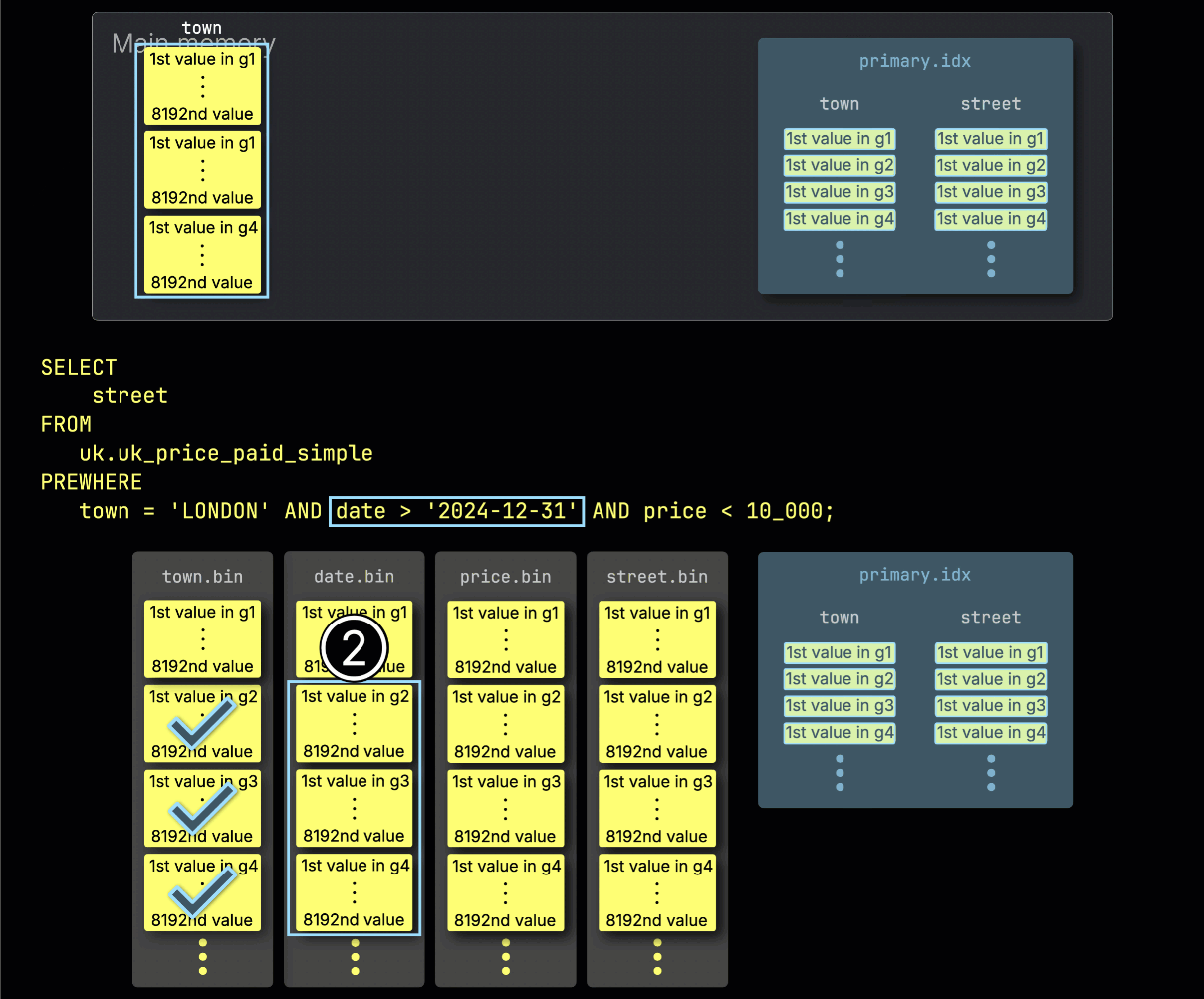
① クエリには town 列に対するフィルタが含まれています。town 列はテーブルのプライマリキーの一部であり、そのためプライマリインデックスの一部でもあります。
② クエリを高速化するために、ClickHouse はテーブルのプライマリインデックスをメモリにロードします。
③ インデックスのエントリを走査して、town 列のどのグラニュールに述語に一致する行が含まれている可能性があるかを特定します。
④ これらの関連する可能性があるグラニュールをメモリにロードし、あわせてクエリに必要な他の列についても位置が揃ったグラニュールをロードします。
⑤ 残りのフィルタは、その後のクエリ実行時に適用されます。
ご覧のとおり、PREWHERE を使わない場合は、実際には少数の行しか一致しなくても、フィルタリングの前に候補となるすべての列がロードされます。
PREWHERE はどのようにクエリ効率を改善するか
以下のアニメーションは、上記のクエリに対して、すべてのクエリ述語に PREWHERE 句を適用した場合の処理方法を示しています。
最初の 3 つの処理ステップは前と同じです:

① クエリには town カラムに対するフィルタが含まれており、これはテーブルの主キーの一部であり、したがってプライマリインデックスの一部でもあります。
② PREWHERE 句なしの実行時と同様に、クエリを高速化するため、ClickHouse はプライマリインデックスをメモリに読み込みます。
③ その後、インデックスエントリを走査し、town カラムのどのグラニュールに述語と一致する行が含まれている可能性があるかを特定します。
ここからは PREWHERE 句のおかげで次のステップが変わります。すべての関連カラムを最初に読み込む代わりに、ClickHouse はカラム単位でデータをフィルタし、本当に必要なものだけを読み込みます。これにより、特にワイドテーブルでの I/O が大幅に削減されます。
各ステップで、前のフィルタを「通過した」、つまり一致した行を少なくとも 1 行含むグラニュールだけが読み込まれます。その結果、各フィルタに対して読み込み・評価すべきグラニュールの数は単調に減少していきます。
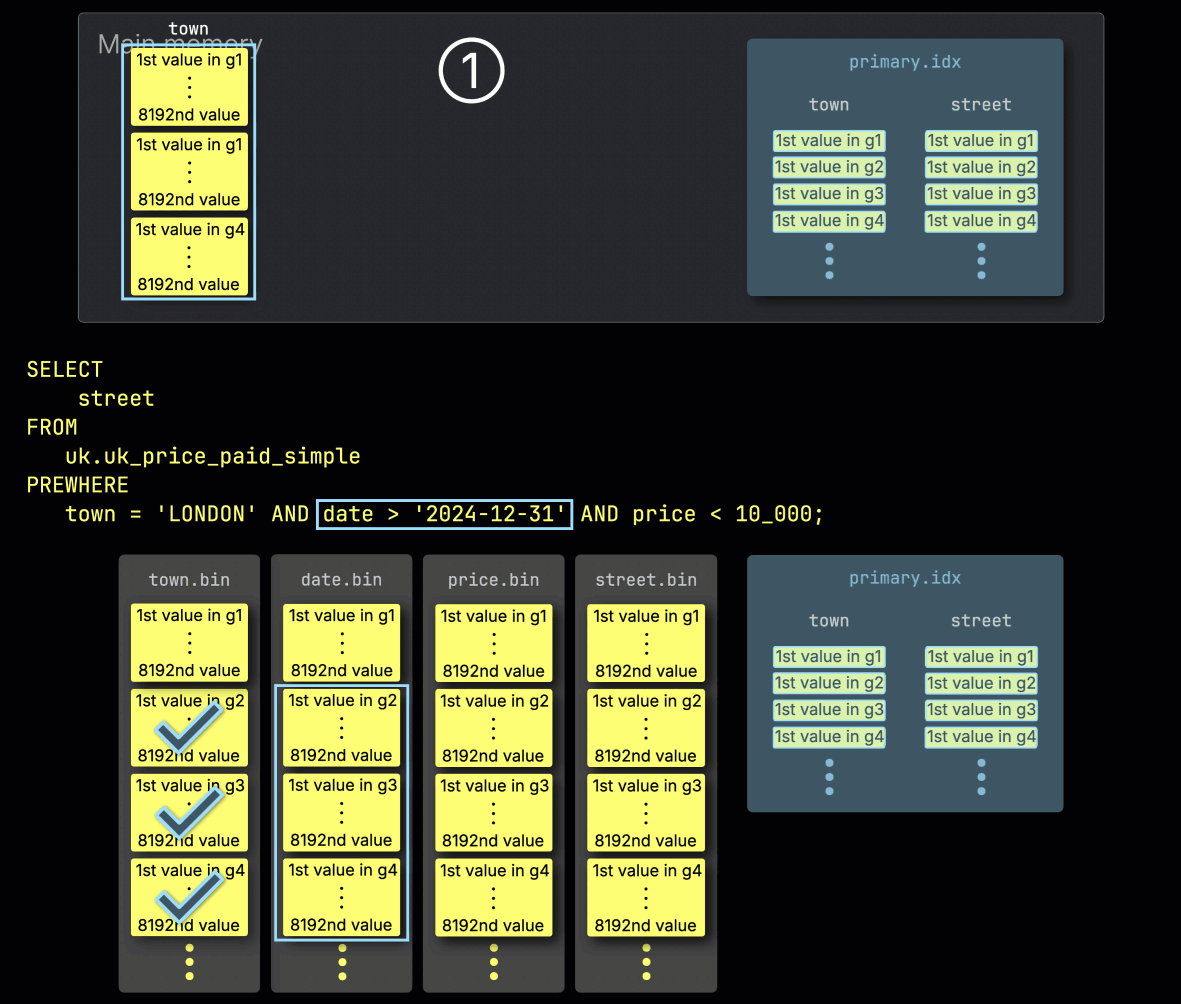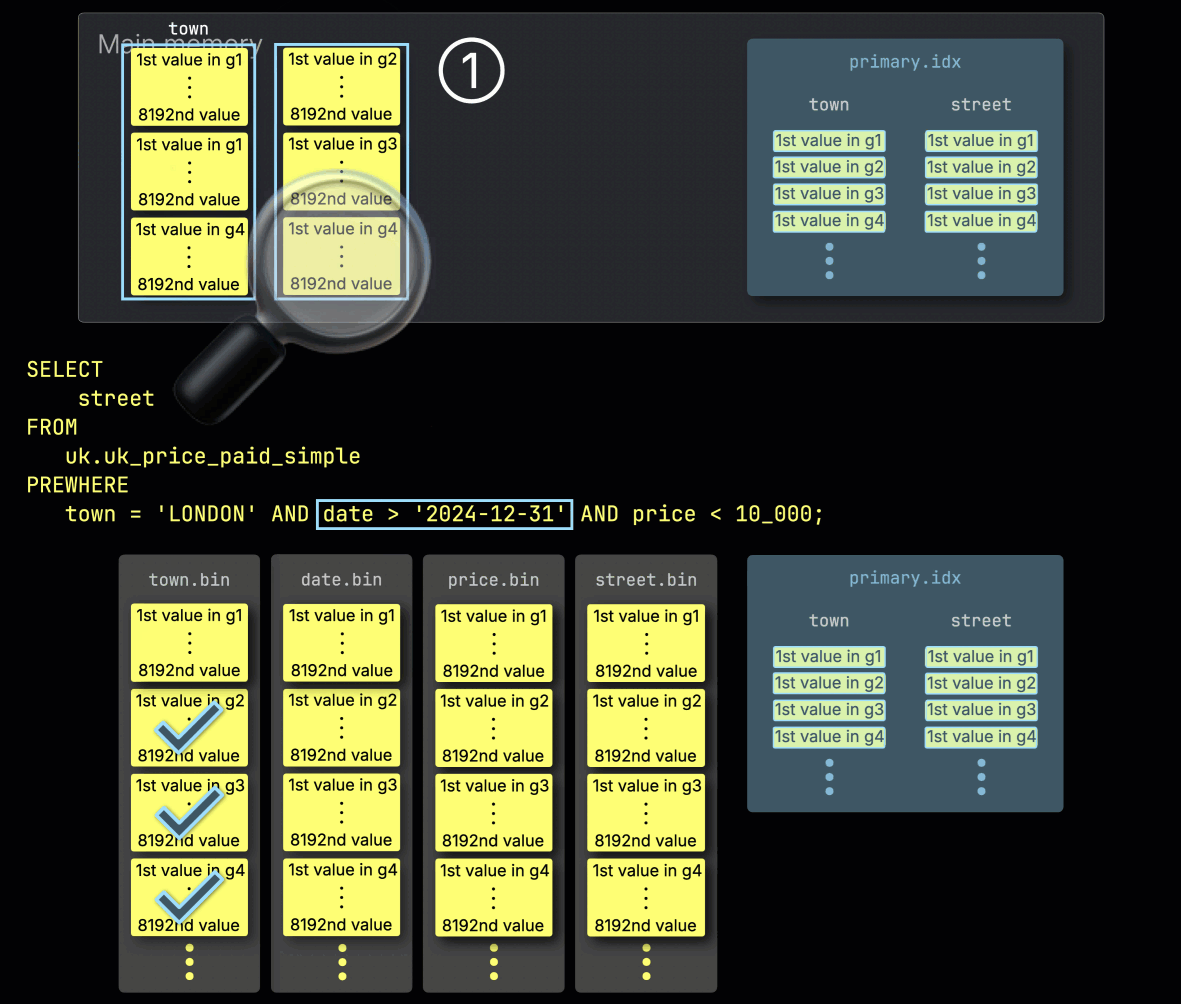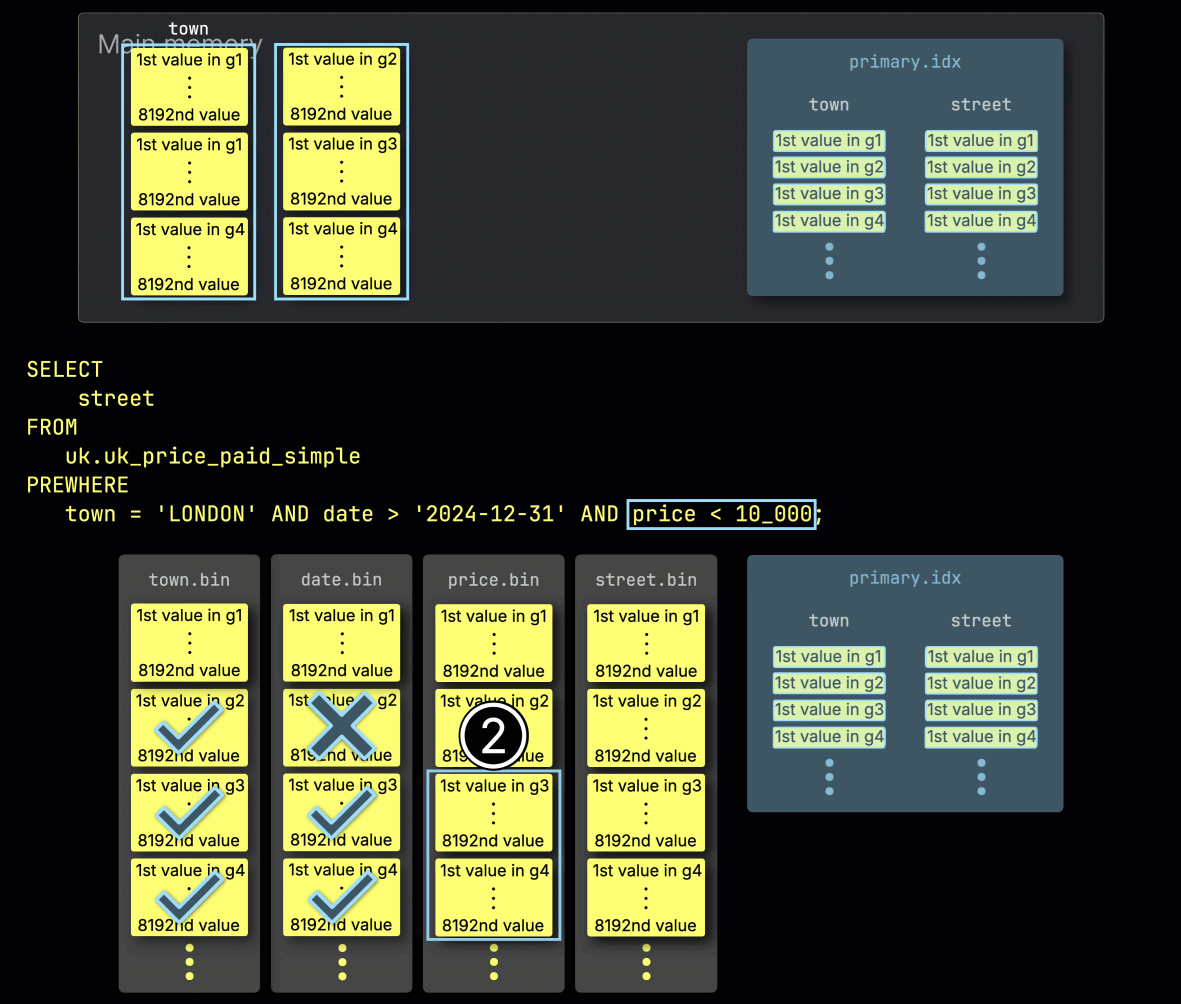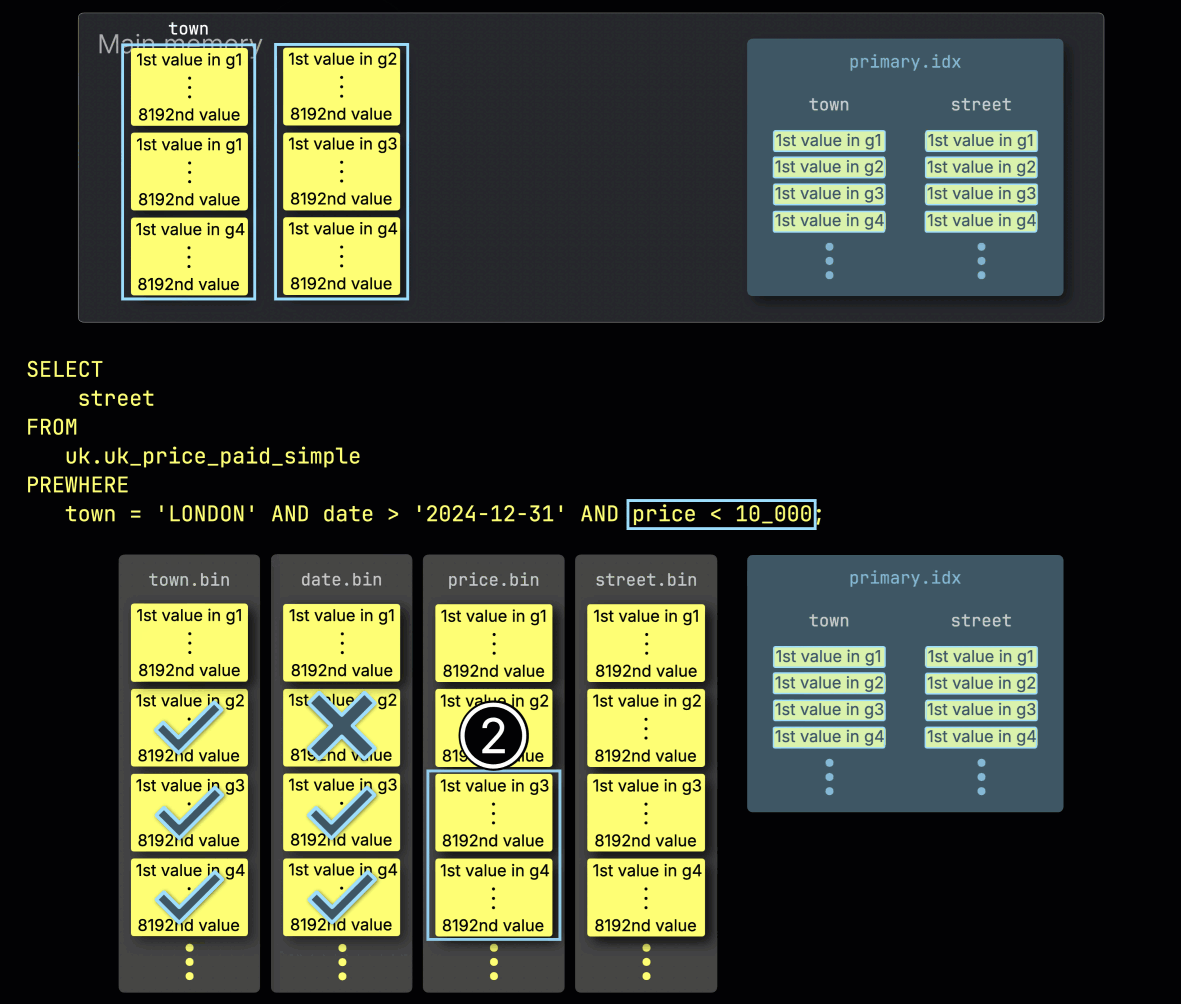
ステップ 1: town でフィルタ
ClickHouse は、① town カラムから選択されたグラニュールを読み込み、どれが実際に London に一致する行を含んでいるかを確認することから PREWHERE 処理を開始します。
この例では選択されたすべてのグラニュールが一致するため、② 次のフィルタ対象カラムである date の、位置的に対応するグラニュールが処理対象として選択されます:
ステップ 2: date でフィルタ
次に、ClickHouse は ① 選択された date カラムのグラニュールを読み込み、フィルタ date > '2024-12-31' を評価します。
この場合、3 つのグラニュールのうち 2 つに一致する行が含まれているため、② その 2 つに位置的に対応する、次のフィルタ対象カラム price のグラニュールだけが、さらに処理対象として選択されます:
ステップ 3: price でフィルタ
最後に、ClickHouse は ① price カラムから選択された 2 つのグラニュールを読み込み、最後のフィルタ price > 10_000 を評価します。
2 つのグラニュールのうち一致する行を含むのは 1 つだけなので、② そのグラニュールに位置的に対応する SELECT 対象カラム street のグラニュールだけを、さらに処理のために読み込めば十分です:

最終ステップまでに、マッチする行を含む最小限のカラムグラニュールだけが読み込まれます。これにより、メモリ使用量とディスク I/O が削減され、クエリ実行が高速化されます。
PREWHERE あり・なしの両方のクエリで、ClickHouse が処理する行数は同じである点に注意してください。ただし、PREWHERE 最適化が適用されている場合、処理するすべての行について、すべてのカラム値を読み込む必要はありません。
PREWHERE 最適化は自動的に適用されます
PREWHERE 句は、上記の例のように手動で追加できます。ただし、PREWHERE を明示的に記述する必要はありません。設定 optimize_move_to_prewhere が有効な場合(デフォルトで true)、ClickHouse は WHERE から PREWHERE へフィルタ条件を自動的に移動し、読み取り量の削減効果が最も大きいものを優先します。
基本的な考え方は、「小さいカラムほどスキャンが速く、大きいカラムが処理される頃には、ほとんどの granule がすでにフィルタされている」というものです。すべてのカラムは同じ行数を持つため、カラムのサイズは主にデータ型によって決まり、たとえば UInt8 カラムは一般的に String カラムよりもはるかに小さくなります。
ClickHouse はバージョン 23.2 以降、デフォルトでこの戦略に従い、PREWHERE フィルタ対象のカラムを非圧縮サイズの昇順で並べ替え、マルチステップ処理を行います。
バージョン 23.11 以降では、任意でカラム統計情報を利用できるようになり、単なるカラムサイズではなく実際のデータ選択性に基づいてフィルタ処理の順序を決定することで、この最適化をさらに強化できます。
PREWHERE の効果を測定する方法
PREWHERE がクエリに効果を発揮しているか検証するには、optimize_move_to_prewhere setting を有効にした場合と無効にした場合でクエリのパフォーマンスを比較します。
まずは、optimize_move_to_prewhere 設定を無効にしてクエリを実行します。
このクエリの実行では、ClickHouse は 23.36 MB のカラムデータを読み取り、231 万行を処理しました。
次に、optimize_move_to_prewhere 設定を有効にしてクエリを実行します(この設定はデフォルトで有効なため、省略可能です):
処理された行数は同じ(231万行)ですが、PREWHERE のおかげで ClickHouse が読み取る列データ量は 23.36 MB からわずか 6.74 MB へと 3 倍以上削減され、その結果、総実行時間も 3 分の 1 に短縮されました。
ClickHouse が内部で PREWHERE をどのように適用しているかをより詳しく理解するには、EXPLAIN とトレースログを使用します。
EXPLAIN 句を使って、クエリの論理プランを調べます:
ここでは、出力が非常に冗長になるため、プランの結果の大部分は省略しています。要点としては、3 つすべてのカラム述語が自動的に PREWHERE に移動されていることが分かります。
実際に再現してみると、クエリプランから、これらの述語の順序がカラムのデータ型サイズに基づいていることも確認できます。カラム統計を有効化していない場合、ClickHouse は PREWHERE の処理順序を決める際の代替指標としてサイズを利用します。
さらに内部動作を詳しく確認したい場合は、クエリ実行中のすべての test レベルのログエントリを返すよう ClickHouse に指示することで、各 PREWHERE 処理ステップを個別に観察できます。
重要なポイント
- PREWHERE は、後でフィルタ条件で除外される列データの読み取りを回避し、I/O とメモリを節約します。
optimize_move_to_prewhereが有効になっていれば(デフォルト)、自動的に動作します。- フィルタの適用順序が重要です。サイズが小さく、かつ選択度の高い列を先に指定してください。
- PREWHERE が適用されていることを確認し、その効果を把握するために
EXPLAINとログを使用してください。 - PREWHERE は、幅の広いテーブルや、選択的なフィルタを伴う大規模スキャンに対して最も効果的です。
