データの管理
オブザーバビリティ向けの ClickHouse の導入では、必然的に大規模なデータセットを扱うことになり、その管理が必要になります。ClickHouse には、データ管理を支援するためのさまざまな機能が用意されています。
パーティション
ClickHouse におけるパーティションは、特定のカラムや SQL 式に従ってデータをディスク上で論理的に分割する仕組みです。データを論理的に分割することで、それぞれのパーティションを独立して操作(例: 削除)できます。これにより、パーティション、ひいてはその部分集合を、時間に応じてストレージ階層間で効率的に移動したり、データの有効期限を設定したり/クラスターから効率的に削除したりできます。
パーティションは、テーブルを初期定義する際に PARTITION BY 句によって指定します。この句には任意のカラムに対する SQL 式を含めることができ、その結果によって各行がどのパーティションに送られるかが決定されます。
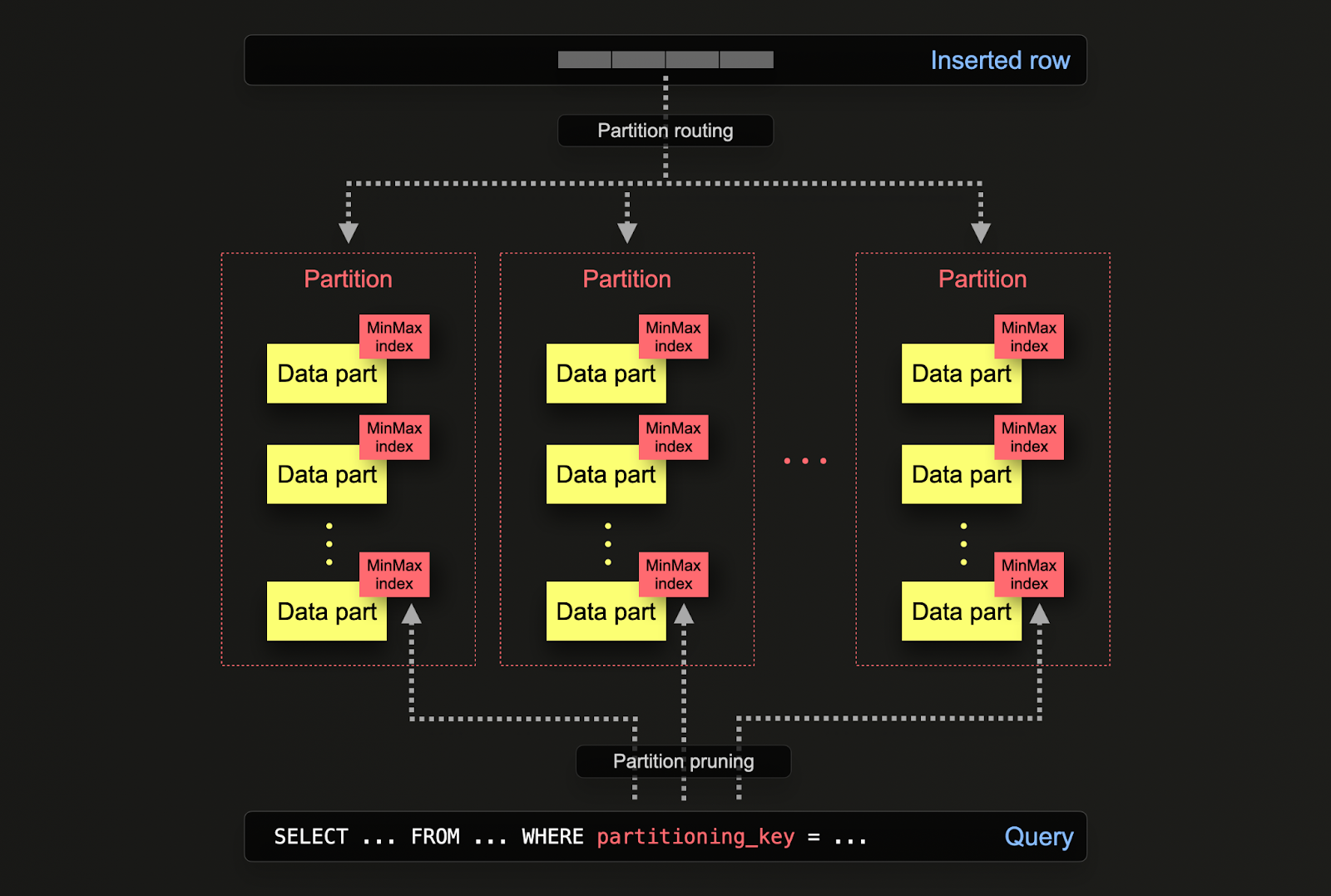
データパーツは(共通のフォルダ名プレフィックスを通じて)ディスク上の各パーティションと論理的に関連付けられ、個別にクエリを実行できます。以下の例では、デフォルトの otel_logs スキーマは toDate(Timestamp) という式を使って日単位でパーティション分割します。行が ClickHouse に挿入されると、この式が各行に対して評価され、対応するパーティションが存在する場合はそこにルーティングされます(その日の最初の行であれば、その時点でパーティションが作成されます)。
パーティションに対しては、バックアップ、カラム操作、行単位でデータを変更/削除するミューテーション、インデックスのクリア(例: セカンダリインデックス) など、さまざまな操作を実行できます。
例として、otel_logs テーブルが日単位でパーティション分割されているとします。構造化ログのデータセットでテーブルが埋められている場合、このテーブルには複数日分のデータが格納されます。
現在のパーティションは、システムテーブルに対する簡単なクエリで確認できます。
古いデータの保存用に、otel_logs_archive という別のテーブルを用意しておくこともできます。データはパーティション単位で効率的にこのテーブルへ移動でき(メタデータの変更だけで完了します)。
これは、INSERT INTO SELECT を使用してデータを新しい対象テーブルに書き換える必要がある他の手法とは対照的です。
テーブル間でのパーティション移動 には、いくつかの条件を満たす必要があります。特に、テーブルは同一の構造、パーティションキー、PRIMARY KEY、およびインデックス/プロジェクションを持っていなければなりません。ALTER DDL でパーティションを指定する方法に関する詳細な説明はこちらにあります。
さらに、データはパーティション単位で効率的に削除できます。これは、他の手法(ミューテーションや軽量削除)と比べてはるかにリソース効率に優れており、優先して使用すべき方法です。
この機能は、設定 ttl_only_drop_parts=1 を有効にした場合に TTL によって活用されます。詳細については TTL(Time to Live)によるデータ管理 を参照してください。
アプリケーション
上記では、データをパーティション単位で効率的に移動および操作できることを示しました。実際には、みなさんが Observability のユースケースでパーティション操作を最も頻繁に活用するのは、おそらく次の 2 つのシナリオです。
- 階層型アーキテクチャ - ストレージ階層間でデータを移動すること(ストレージ階層を参照)。これにより、ホット・コールド構成のアーキテクチャを構築できます。
- 効率的な削除 - データが指定された TTL に達したときに削除すること(TTL を用いたデータ管理を参照)
以下で、これら 2 つについて詳しく説明します。
クエリパフォーマンス
パーティションはクエリパフォーマンスの改善に役立つ場合がありますが、その効果はアクセスパターンに大きく依存します。クエリが少数のパーティション(理想的には 1 つ)のみを対象とする場合、パフォーマンスが向上する可能性があります。これは通常、パーティションキーが一次キーに含まれておらず、かつそのキーでフィルタリングしている場合にのみ有用です。一方で、多数のパーティションをまたいでアクセスする必要があるクエリでは、パーティションを使用しない場合と比べてパフォーマンスが低下する可能性があります(より多くのパーツが存在し得るためです)。パーティションキーがすでに一次キーの先頭付近に含まれている場合、単一パーティションを対象とすることによるメリットはほとんど、あるいはまったく享受できません。パーティション内の値が一意である場合、パーティションは GROUP BY クエリを最適化する ためにも使用できます。しかし一般的には、まず一次キーを最適化することを優先し、パーティション分割をクエリ最適化手法として検討するのは、アクセスパターンが特定の予測可能なデータサブセット(例:日単位でパーティション分割し、クエリのほとんどが直近 1 日を対象とする場合)に対して行われるといった例外的なケースに限るべきです。この挙動の例については こちら を参照してください。
TTL(Time-to-live)によるデータ管理
Time-to-Live(TTL)は、膨大な量のデータが継続的に生成される状況において、効率的なデータ保持と管理を実現するための、ClickHouse ベースのオブザーバビリティソリューションにおける重要な機能です。ClickHouse で TTL を実装すると、古いデータの有効期限管理と削除を自動化でき、手動のオペレーションなしにストレージを最適に活用しつつパフォーマンスを維持できます。この機能により、データベースを軽量に保ち、ストレージコストを削減し、最新かつ最も関連性の高いデータにフォーカスすることでクエリを高速かつ効率的に保つことができます。さらに、データライフサイクルを体系的に管理することで、データ保持ポリシーへの準拠を支援し、オブザーバビリティソリューション全体の持続可能性とスケーラビリティを高めます。
TTL は ClickHouse において、テーブルレベルまたはカラムレベルで指定できます。
テーブルレベル TTL
ログとトレースの両方に対するデフォルトのスキーマには、指定した期間後にデータを自動的に削除する TTL が含まれています。これは、たとえば ClickHouse エクスポーター内の ttl キーで次のように指定します。
この構文は現在、Golang の Duration 構文 をサポートしています。h を使用し、それがパーティショニング期間と一致するようにすることを推奨します。たとえば、日単位でパーティションを切る場合は、24h、48h、72h など、1日の倍数になるようにしてください。 これにより、たとえば ttl: 96h の場合、自動的にテーブルに TTL 句が追加されます。
デフォルトでは、TTL が期限切れとなったデータは、ClickHouse がデータパーツをマージする際に削除されます。ClickHouse がデータの期限切れを検出すると、スケジュール外マージを実行します。
TTL は即時には適用されず、上記のとおりスケジュールに基づいて適用されます。MergeTree テーブル設定 merge_with_ttl_timeout は、削除 TTL を伴うマージを再実行するまでの最小遅延時間(秒)を設定します。デフォルト値は 14400 秒(4 時間)です。ただし、これはあくまで最小遅延であり、TTL マージがトリガーされるまでにさらに時間がかかる場合があります。この値が小さすぎると、多数のスケジュール外マージが発生し、多くのリソースを消費する可能性があります。TTL の有効期限の適用は、コマンド ALTER TABLE my_table MATERIALIZE TTL を使用して強制できます。
Important: ttl_only_drop_parts=1 の使用を推奨します(デフォルトのスキーマで適用されます)。この設定が有効な場合、そのパーツ内のすべての行が期限切れになったときに、ClickHouse はパーツ全体を削除します。パーツ全体を削除することで(ttl_only_drop_parts=0 の場合にリソース集約的なミューテーションによって行われる、TTL 対象行の部分的なクリーンアップではなく)、merge_with_ttl_timeout を短く設定しても、システムパフォーマンスへの影響を抑えることができます。データを TTL で有効期限を設定している単位(例: 日)と同じ単位でパーティション分割している場合、各パーツには自然とその定義された間隔のデータのみが含まれるようになります。これにより、ttl_only_drop_parts=1 を効率的に適用できるようになります。
カラムレベルの TTL
上記の例では、テーブルレベルでデータの有効期限を設定しています。データにはカラムレベルでも有効期限を設定できます。データが古くなるにつれ、調査における価値が、その保持に必要なリソースコストに見合わないと判断されるカラムを削除するのに利用できます。例えば、挿入時にまだ抽出されていない新しい動的メタデータ(例: 新しい Kubernetes ラベル)が追加される可能性に備えて、Body カラムを保持しておくことを推奨します。一定期間、例えば 1 か月が経過した後、この追加のメタデータが有用ではないことが明らかになるかもしれません。その場合、Body カラムを保持し続ける価値は限定的です。
以下では、Body カラムを 30 日後に削除する方法を示します。
カラムレベルの TTL を指定する場合は、ユーザーが独自にスキーマを定義する必要があります。これは OTel collector では指定できません。
データの再圧縮
通常、オブザーバビリティ向けデータセットには ZSTD(1) を推奨していますが、別の圧縮アルゴリズムや、より高い圧縮レベル(例: ZSTD(3))を試すこともできます。スキーマ作成時にこれを指定できるだけでなく、一定期間経過後に圧縮方式を変更するように設定することも可能です。これは、あるコーデックや圧縮アルゴリズムが圧縮率を向上させる一方で、クエリ性能を低下させる場合に有効です。このトレードオフは、クエリ頻度の低い古いデータには許容できる一方で、調査で頻繁に利用される最新データには適さない場合があります。
以下はその一例で、データを削除する代わりに、4日後に ZSTD(3) を使ってデータを再圧縮します。
常に、異なる圧縮レベルおよびアルゴリズムが挿入およびクエリのパフォーマンスに与える影響を評価することを推奨します。たとえば、デルタコーデックはタイムスタンプの圧縮に有用な場合があります。しかし、これらがプライマリキーの一部として使用されている場合、フィルタリングのパフォーマンスが低下する可能性があります。
TTL の設定に関する詳細と例についてはこちらを参照してください。テーブルやカラムに TTL を追加・変更する方法の例はこちらを参照してください。TTL によって hot-warm アーキテクチャのようなストレージ階層を実現する方法については、ストレージ階層を参照してください。
ストレージ階層
ClickHouse では、異なるディスク上にストレージ階層を作成できます。たとえば、ホット/最新データを SSD 上に、古いデータを S3 に配置します。このアーキテクチャにより、調査で参照される頻度が低く、クエリの SLA 要件がより緩い古いデータについて、より低コストなストレージを利用できます。
ClickHouse Cloud では、S3 上に保存された単一のデータコピーと、SSD をバックエンドとするノードキャッシュを使用します。そのため、ClickHouse Cloud ではストレージ階層を構成する必要はありません。
ストレージ階層を作成するには、まずディスクを作成し、それを使用してストレージポリシーを定義します。ストレージポリシーにはボリュームを含めることができ、テーブル作成時に指定できます。データは、使用率、パーツサイズ、ボリュームの優先度に基づいてディスク間で自動的に移動できます。詳細はこちらを参照してください。
データは ALTER TABLE MOVE PARTITION コマンドを使用してディスク間で手動で移動できますが、ボリューム間のデータ移動は TTL を使って制御することもできます。包括的な例はこちらにあります。
スキーマ変更の管理
ログおよびトレースのスキーマは、たとえばユーザーが異なるメタデータやポッドラベルを持つ新しいシステムを監視するようになるなど、システムのライフサイクルを通じて必然的に変化します。OTel スキーマを用いてデータを出力し、元のイベントデータを構造化形式で取り込んでおくことで、ClickHouse のスキーマはこれらの変更に対して堅牢になります。しかし、新しいメタデータが利用可能になったり、クエリアクセスパターンが変化したりすると、それに合わせてスキーマを更新したくなるでしょう。
スキーマ変更の際のダウンタイムを回避するために、ユーザーにはいくつかの方法があり、以下で紹介します。
既定値を使用する
カラムは DEFAULT 値 を使用してスキーマに追加できます。INSERT 時に値が指定されなかった場合、指定した DEFAULT が使用されます。
スキーマの変更は、これらの新しいカラムが送信されるきっかけとなるマテリアライズドビューの変換ロジックや OTel collector の設定を変更する前に行うことができます。
スキーマを変更したら、ユーザーは OTel collector を再設定できます。ユーザーが "Extracting structure with SQL" で示した推奨プロセス、すなわち OTel collector がデータを Null テーブルエンジンに送信し、マテリアライズドビューが対象スキーマを抽出して結果を保存用のターゲットテーブルに送信する、という流れを使用していると仮定すると、ビューは ALTER TABLE ... MODIFY QUERY 構文 を使用して変更できます。以下のようなターゲットテーブルと、それに対応するマテリアライズドビュー("Extracting structure with SQL" で使用したものと同様)を用いて、OTel の構造化ログから対象スキーマを抽出するものとします。
LogAttributes から新しいカラム Size を抽出したいとします。ALTER TABLE で既定値を指定することで、このカラムをスキーマに追加できます。
上記の例では、LogAttributes の size キーをデフォルトとして指定しています(存在しない場合は 0 になります)。そのため、この列にアクセスするクエリは、値が挿入されていない行については Map にアクセスする必要があり、その分だけ遅くなります。代わりに 0 などの定数をデフォルトとして指定することも容易であり、その場合、値を持たない行に対する後続クエリのコストを削減できます。このテーブルをクエリすると、Map から期待どおりに値が設定されていることが確認できます。
今後のすべてのデータにこの値が挿入されるようにするには、以下のように ALTER TABLE 構文を使用してマテリアライズドビューを変更できます。
以降の行では、挿入時に Size 列に値が設定されます。
新しいテーブルを作成する
上記の手順の代替として、新しいスキーマを持つ新しいターゲットテーブルを作成するだけでも問題ありません。いずれのマテリアライズドビューも、上記の ALTER TABLE MODIFY QUERY を使用して新しいテーブルを参照するように変更できます。このアプローチでは、otel_logs_v3 のようにテーブルをバージョン管理できます。
このアプローチでは、クエリ対象として複数のテーブルが存在する状態になります。テーブルを横断してクエリするには、テーブル名にワイルドカードパターンを指定できる merge 関数 を使用できます。以下では、otel_logs テーブルの v2 と v3 に対してクエリを実行する例を示します。
merge 関数の使用を避けつつ、複数のテーブルを統合した結果をエンドユーザーに 1 つのテーブルとして公開したい場合は、Merge テーブルエンジン を使用できます。以下でその例を示します。
EXCHANGE TABLE 構文を使用すると、新しいテーブルを追加するたびにこれを更新できます。たとえば、v4 テーブルを追加する場合は、新しいテーブルを作成し、それを以前のバージョンとアトミックに入れ替えることができます。
