ClickHouse Cloud と BigQuery の比較
リソースの構成
ClickHouse Cloud におけるリソースの構成方法は、BigQuery のリソース階層と類似しています。以下の図に示す ClickHouse Cloud のリソース階層に基づき、主な違いを説明します。
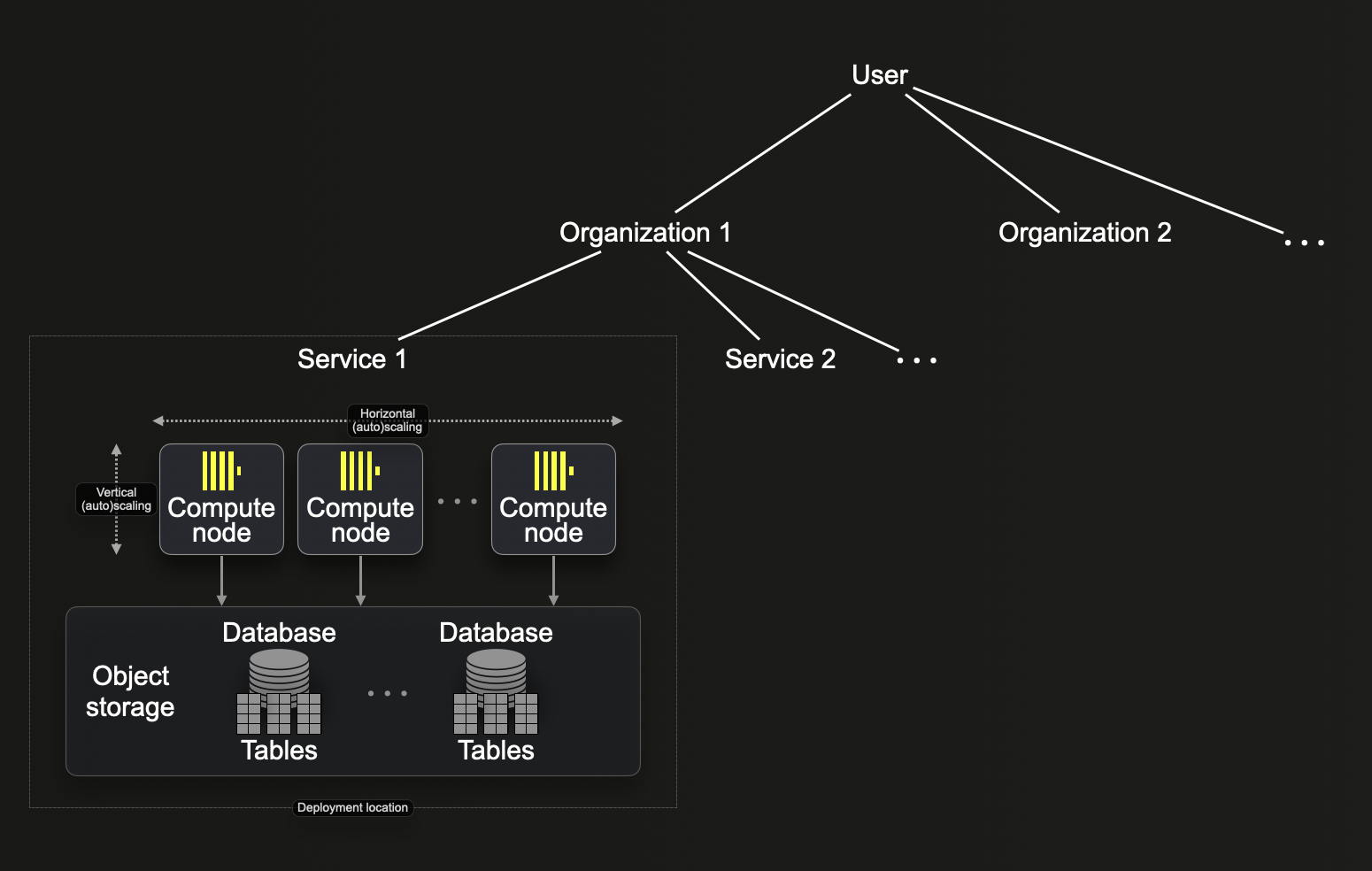
Organizations
BigQuery と同様に、organization は ClickHouse Cloud のリソース階層におけるルートノードです。ClickHouse Cloud アカウントで最初にセットアップしたユーザーは、自動的にそのユーザーが所有する organization に割り当てられます。ユーザーは、ほかのユーザーを organization に招待できます。
BigQuery Projects と ClickHouse Cloud Services の比較
organization の中では、BigQuery の project と大まかに同等の service を作成できます。これは、ClickHouse Cloud に保存されるデータが service に紐づいているためです。ClickHouse Cloud には複数の service タイプが用意されています。各 ClickHouse Cloud service は特定のリージョンにデプロイされ、次の要素を含みます:
- コンピュートノードのグループ(現在は Development ティアの service には 2 ノード、Production ティアの service には 3 ノード)。これらのノードについて、ClickHouse Cloud は垂直スケーリングおよび水平スケーリングの両方を、手動および自動でサポートします。
- service がすべてのデータを保存するオブジェクトストレージフォルダ。
- エンドポイント(または ClickHouse Cloud UI コンソールから作成される複数のエンドポイント) - service へ接続するために使用する service の URL(例:
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443)
BigQuery Datasets と ClickHouse Cloud Databases の比較
ClickHouse はテーブルを論理的にデータベースにグループ化します。BigQuery のデータセットと同様に、ClickHouse のデータベースはテーブルデータを整理し、アクセスを制御するための論理コンテナです。
BigQuery Folders
現在、ClickHouse Cloud には BigQuery のフォルダに相当する概念は存在しません。
BigQuery Slot reservations と Quotas
BigQuery の slot reservation と同様に、ClickHouse Cloud では 垂直および水平のオートスケーリングを構成できます。垂直オートスケーリングでは、service のコンピュートノードに対してメモリおよび CPU コアの最小値と最大値を設定できます。service はその範囲内で必要に応じてスケールします。これらの設定は、service の初期作成フローの際にも指定できます。service 内の各コンピュートノードは同じサイズです。水平スケーリングにより、service 内のコンピュートノード数を変更できます。
さらに、BigQuery の quota と同様に、ClickHouse Cloud は同時実行制御、メモリ使用量の制限、および I/O スケジューリングを提供し、クエリをワークロードクラスに分離できるようにします。特定のワークロードクラスに対して共有リソース (CPU コア、DRAM、ディスクおよびネットワーク I/O) の上限を設定することで、それらのクエリがほかの重要なビジネスクエリに影響を与えないようにします。同時実行制御により、多数の同時クエリが存在するシナリオでスレッドの過剰割り当てを防ぎます。
ClickHouse はメモリアロケーションのバイトサイズをサーバー、ユーザー、およびクエリレベルで追跡し、柔軟なメモリ使用量制限を可能にします。メモリオーバーコミットにより、クエリは保証メモリを超えて未使用メモリを追加で利用できますが、ほかのクエリに対するメモリ制限は維持されます。加えて、集約、ソート、結合句で使用されるメモリを制限でき、メモリ上限を超えた場合には外部アルゴリズムへのフォールバックが可能です。
最後に、I/O スケジューリングでは、最大帯域幅、インフライト要求数、およびポリシーに基づき、ワークロードクラスごとにローカルおよびリモートディスクへのアクセスを制限できます。
権限
ClickHouse Cloud では、cloud コンソールとデータベースの 2 か所でユーザーアクセスを制御します。コンソールアクセスは clickhouse.cloud のユーザーインターフェイスを介して管理されます。データベースアクセスは、データベースユーザーアカウントとロールによって管理されます。さらに、コンソールユーザーにはデータベース内のロールを付与でき、これによりコンソールユーザーはSQL コンソールを通じてデータベースと対話できます。
データ型
ClickHouse は数値型に関して、より細かい精度指定を提供します。たとえば、BigQuery は数値型として INT64, NUMERIC, BIGNUMERIC, FLOAT64 を提供しています。これに対して ClickHouse は、小数、浮動小数点数、整数に対して複数の精度レベルの型を提供しています。これらのデータ型を用いることで、ストレージおよびメモリのオーバーヘッドを最適化でき、その結果、クエリの高速化とリソース消費の削減につながります。以下では、各 BigQuery 型に対応する ClickHouse 型を対応付けています。
ClickHouse の型に複数の選択肢がある場合は、実際のデータの取り得る範囲を考慮し、必要最小限の型を選択してください。さらに圧縮率を高めるには、適切なコーデック の利用も検討してください。
クエリ高速化手法
主キー・外部キーとプライマリインデックス
BigQuery では、テーブルに 主キーおよび外部キー制約 を設定できます。一般的に、主キーと外部キーはリレーショナルデータベースにおいてデータ完全性を保証するために使用されます。主キーの値は通常、各行で一意であり、NULL にはなりません。各行の外部キーの値は、主キー側テーブルの主キー列に存在するか、NULL でなければなりません。BigQuery では、これらの制約は実際には強制されませんが、クエリオプティマイザがこの情報を利用してクエリをさらに最適化する場合があります。
ClickHouse でも、テーブルに主キーを設定できます。BigQuery と同様に、ClickHouse はテーブルの主キー列の値の一意性を強制しません。BigQuery と異なり、テーブルのデータはディスク上において主キー列で ソートされた順序 で格納されます。クエリオプティマイザはこのソート順を利用して再ソートを防ぎ、JOIN のためのメモリ使用量を最小化し、LIMIT 句の早期打ち切りを可能にします。BigQuery と異なり、ClickHouse は主キー列の値に基づいて (疎な) プライマリインデックス を自動的に作成します。このインデックスは、主キー列に対するフィルタを含むすべてのクエリの高速化に利用されます。ClickHouse は現在、外部キー制約をサポートしていません。
セカンダリインデックス(ClickHouse のみで利用可能)
テーブルのプライマリキー列の値から作成されるプライマリインデックスに加えて、ClickHouse ではプライマリキー以外の列にもセカンダリインデックスを作成できます。ClickHouse には複数種類のセカンダリインデックスがあり、それぞれ異なるタイプのクエリに適しています。
- Bloom Filter インデックス:
- 等価条件(例: =、IN)を含むクエリの高速化に使用されます。
- 確率的データ構造を用いて、データブロック内に値が存在するかどうかを判定します。
- Token Bloom Filter インデックス:
- Bloom Filter インデックスと似ていますが、トークン化された文字列に対して使用され、全文検索クエリに適しています。
- Min-Max インデックス:
- 各データパートごとに、その列の最小値と最大値を保持します。
- 指定された範囲に含まれないデータパートの読み取りをスキップするのに役立ちます。
検索インデックス
BigQuery の search indexes と同様に、ClickHouse のテーブルでは、文字列値を持つカラムに対して full-text indexes を作成できます。
ベクトルインデックス
BigQuery は最近、Pre-GA 機能として ベクトルインデックス を導入しました。同様に、ClickHouse でもベクトル検索を高速化するための インデックス が実験的にサポートされています。
パーティション分割
BigQuery と同様に、ClickHouse もテーブルをパーティションに分割することで、大規模テーブルをより小さく管理しやすい単位に分け、パフォーマンスと管理性を向上させます。ClickHouse のパーティション分割の詳細についてはこちらをご覧ください。
クラスタリング
クラスタリングを使用すると、BigQuery は指定された少数のカラムの値に基づいてテーブルデータを自動的にソートし、それらを最適なサイズのブロックにまとめて格納します。クラスタリングによりクエリのパフォーマンスが向上し、BigQuery はクエリの実行コストをより正確に見積もれるようになります。クラスタリングされたカラムを利用することで、クエリは不要なデータのスキャンも回避できます。
ClickHouse では、テーブルのプライマリキーのカラムに基づいてデータは自動的にディスク上でクラスタ化され、プライマリインデックスのデータ構造を利用するクエリによってすばやく特定または除外できるブロックとして論理的に構成されます。
マテリアライズドビュー
BigQuery と ClickHouse はどちらもマテリアライズドビューをサポートしています。これは、ベーステーブルに対して実行される変換クエリの結果に基づいて結果を事前計算して保持する機能で、パフォーマンスと効率を向上させます。
マテリアライズドビューのクエリ実行
BigQuery のマテリアライズドビューは、直接クエリすることも、オプティマイザが基となるテーブルへのクエリを処理するために利用することもできます。基となるテーブルへの変更によってマテリアライズドビューが無効化される可能性がある場合は、データは基となるテーブルから直接読み取られます。基となるテーブルへの変更がマテリアライズドビューを無効化しない場合は、残りのデータはマテリアライズドビューから読み取られ、変更分のみが基となるテーブルから読み取られます。
ClickHouse では、マテリアライズドビューは直接クエリすることしかできません。ただし、BigQuery(マテリアライズドビューは基となるテーブルの変更から 5 分以内に自動更新されますが、30 分ごとよりも頻繁には更新されません)と比較すると、ClickHouse のマテリアライズドビューは常に基となるテーブルと同期しています。
マテリアライズドビューの更新
BigQuery は、基となるテーブルに対してビューの変換クエリを実行することで、マテリアライズドビューを定期的にフルリフレッシュします。リフレッシュの間は、一貫したクエリ結果を提供しつつマテリアライズドビューを引き続き利用するために、BigQuery はマテリアライズドビューのデータと新しい基となるテーブルのデータを組み合わせます。
ClickHouse では、マテリアライズドビューはインクリメンタルに更新されます。このインクリメンタル更新メカニズムにより、高いスケーラビリティと低い計算コストが実現されます。インクリメンタル更新されるマテリアライズドビューは、基となるテーブルが数十億から数兆行のデータを含むようなシナリオ向けに特別に設計されています。マテリアライズドビューをリフレッシュするために、増え続ける基となるテーブル全体に対して繰り返しクエリを実行する代わりに、ClickHouse は新たに挿入された基となるテーブル行の値だけから部分的な結果を計算します。この部分的な結果は、バックグラウンドで以前に計算された部分的な結果とインクリメンタルにマージされます。その結果、基となるテーブル全体からマテリアライズドビューを繰り返しリフレッシュする場合と比べて、計算コストを劇的に削減できます。
トランザクション
ClickHouse と対照的に、BigQuery は 1 つのクエリ内、またはセッションを使用することで複数のクエリにまたがる複数ステートメントのトランザクションをサポートしています。複数ステートメントのトランザクションを使用すると、1 つ以上のテーブルに対する行の挿入や削除といった変更操作を行い、その変更を原子的にコミットまたはロールバックできます。複数ステートメントトランザクションは ClickHouse の 2024 年のロードマップ に含まれています。
集約関数
BigQuery と比べると、ClickHouse には標準で利用できる集約関数が大幅に多く用意されています:
- BigQuery には 18 個の集約関数 と、4 個の近似集約関数 が用意されています。
- ClickHouse には 150 個以上の事前定義された集約関数 に加えて、事前定義された集約関数の動作を拡張するための強力な aggregation combinator が用意されています。例えば、150 個を超える事前定義済み集約関数をテーブルの行ではなく配列に対して適用したい場合は、-Array サフィックス を付けて呼び出すだけで構いません。-Map サフィックス を付けると、任意の集約関数を Map 型に対して適用できます。また、-ForEach サフィックス を付けると、任意の集約関数をネストされた配列に対して適用できます。
データソースとファイル形式
BigQuery と比較すると、ClickHouse ははるかに多くのファイル形式とデータソースをサポートしています。
- ClickHouse は、事実上あらゆるデータソースから 90 以上のファイル形式でデータを読み込むことをネイティブにサポートしています
- BigQuery は 5 種類のファイル形式と 19 種類のデータソースをサポートしています
SQL 言語機能
ClickHouse は、分析タスクにより適したものとなるよう、多くの拡張と改良を施した標準 SQL を提供します。例えば、ClickHouse SQL は ラムダ関数をサポートし、高階関数も利用できるため、変換処理を行う際に配列をアンネストしたり explode したりする必要がありません。これは BigQuery のような他のシステムと比べて大きな利点です。
配列
BigQuery の配列関数が 8 個であるのに対して、ClickHouse には 80 個以上の組み込み配列関数があり、幅広い問題をエレガントかつシンプルにモデリング・解決できます。
ClickHouse における典型的な設計パターンは、groupArray 集約関数を使用して、テーブル内の特定の行の値を(一時的に)配列に変換することです。これにより配列関数で効率的に処理でき、その結果は arrayJoin 集約関数を使って再び個々のテーブル行に変換できます。
ClickHouse SQL は高階ラムダ関数をサポートしているため、多くの高度な配列操作は、BigQuery でよく必要となるような、一時的に配列をテーブルへ戻す処理を行わなくても、高階の組み込み配列関数を 1 つ呼び出すだけで実現できます。たとえば、配列のフィルタリングやzip 結合などです。ClickHouse では、これらの操作はそれぞれ高階関数 arrayFilter と arrayZip を呼び出すだけです。
以下では、配列操作に関する BigQuery から ClickHouse への対応表を示します。
| BigQuery | ClickHouse |
|---|---|
| ARRAY_CONCAT | arrayConcat |
| ARRAY_LENGTH | length |
| ARRAY_REVERSE | arrayReverse |
| ARRAY_TO_STRING | arrayStringConcat |
| GENERATE_ARRAY | range |
サブクエリ内の各行に対応する 1 要素の配列を作成する
BigQuery
ClickHouse
groupArray 集約関数
配列を行の集合に変換する
BigQuery
UNNEST 演算子
ClickHouse
日付の配列を返す
BigQuery
ClickHouse
タイムスタンプ配列を返す
BigQuery
ClickHouse
配列のフィルタリング
BigQuery
UNNEST 演算子を使って、一時的に配列をテーブルに展開し直す必要があります
ClickHouse
arrayFilter 関数
配列のジップ(zipping)
BigQuery
UNNEST 演算子を使用して、一時的に配列をテーブル形式に戻す必要がある
ClickHouse
arrayZip 関数
配列の集約
BigQuery
UNNEST 演算子で配列をテーブルに戻す必要がある
ClickHouse
arraySum、arrayAvg などの関数、または 90 を超える既存の集約関数名のいずれかを arrayReduce 関数の引数として使用できます
