パーツマージ
ClickHouse におけるパートマージとは?
ClickHouse は、クエリだけでなくインサートも高速です。その理由は、ストレージレイヤ にあり、これは LSM tree と同様の動作をします。
① (MergeTree engine ファミリーの) テーブルへのインサートは、ソート済みで不変の data parts を生成します。
② すべてのデータ処理は バックグラウンドパートマージ にオフロードされます。
これにより、データ書き込みは軽量で、非常に効率的になります。
テーブルごとの parts の数を制御し、上記 ② を実現するために、ClickHouse はバックグラウンドで継続的に (パーティション単位で) 小さな parts を大きなものへとマージし、圧縮後のサイズがおよそ ~150 GB に達するまで続けます。
次の図は、このバックグラウンドマージ処理の概要を示しています。
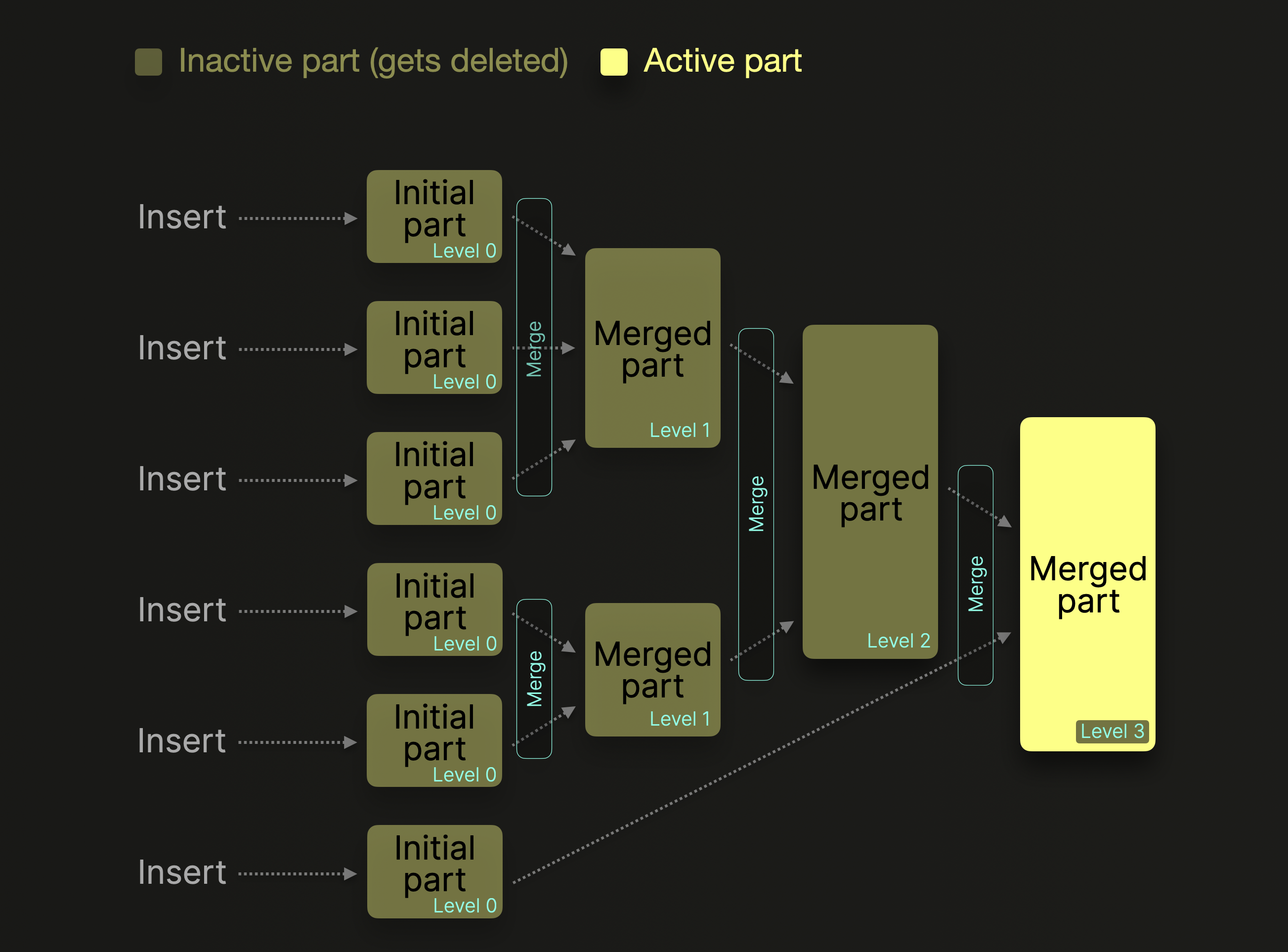
merge level は、追加のマージが行われるたびに 1 ずつ増加します。0 のレベルは、そのパートが新しく、まだマージされていないことを意味します。より大きな parts にマージされた元の parts は inactive とマークされ、最終的には 設定可能 な時間 (デフォルトでは 8 分) 後に削除されます。時間の経過とともに、これによりマージされた parts の 木構造 が形成されます。これが merge tree テーブルという名称の由来です。
マージの監視
テーブルパーツとは何かの例では、ClickHouse がすべてのテーブルパーツを parts システムテーブルで追跡していることを示しました。例に用いたテーブルについて、アクティブな各パーツごとのマージレベルと保存されている行数を取得するために、次のクエリを使用しました。
前に説明したクエリ結果から、サンプルテーブルにはアクティブなパーツが4つあり、それぞれは最初に挿入されたパーツを1回マージして作成されたものであることが分かります。
クエリを実行すると、4つのパーツがその後1つの最終パートにマージされたことがわかります (テーブルにこれ以上 insert が行われていない場合) :
ClickHouse 24.10 では、組み込みの monitoring dashboards に新しい merges dashboard が追加されました。OSS と Cloud の両方で /merges HTTP ハンドラー経由で利用でき、このダッシュボードを使ってサンプルテーブルに対するすべてのパートマージを可視化できます。
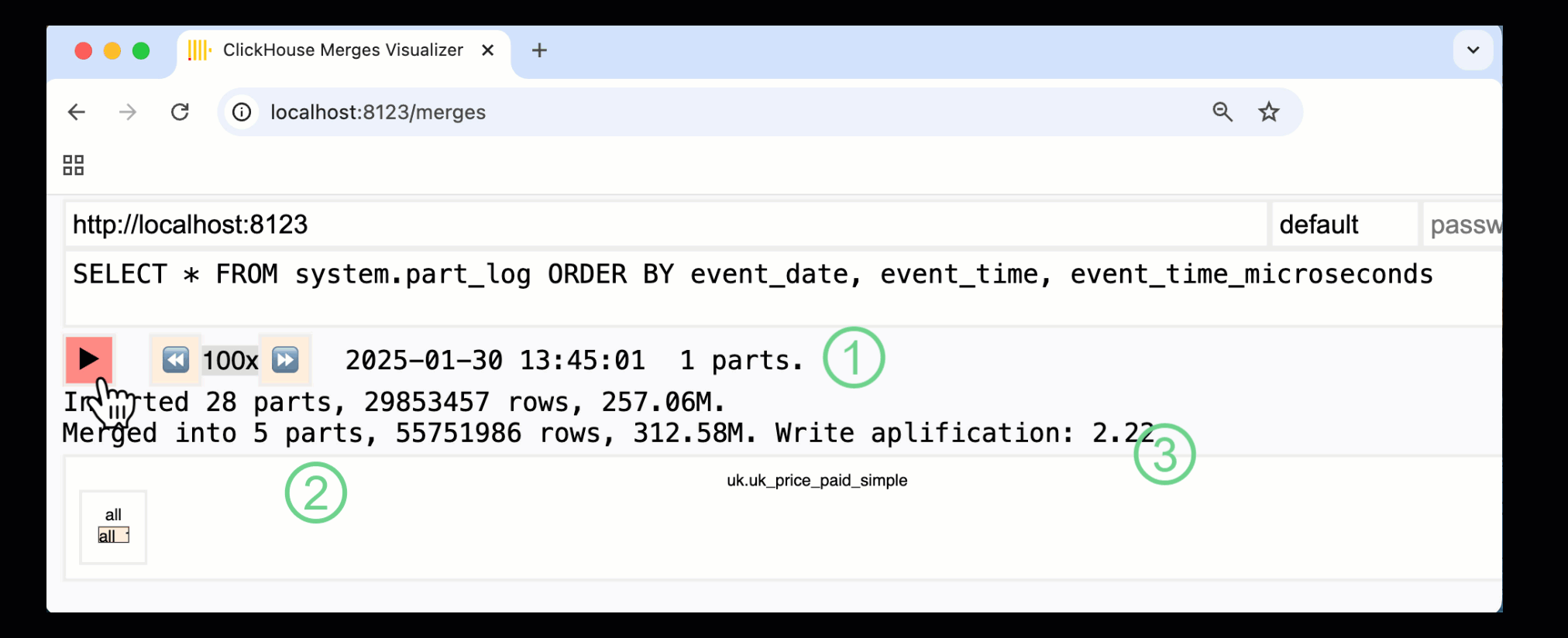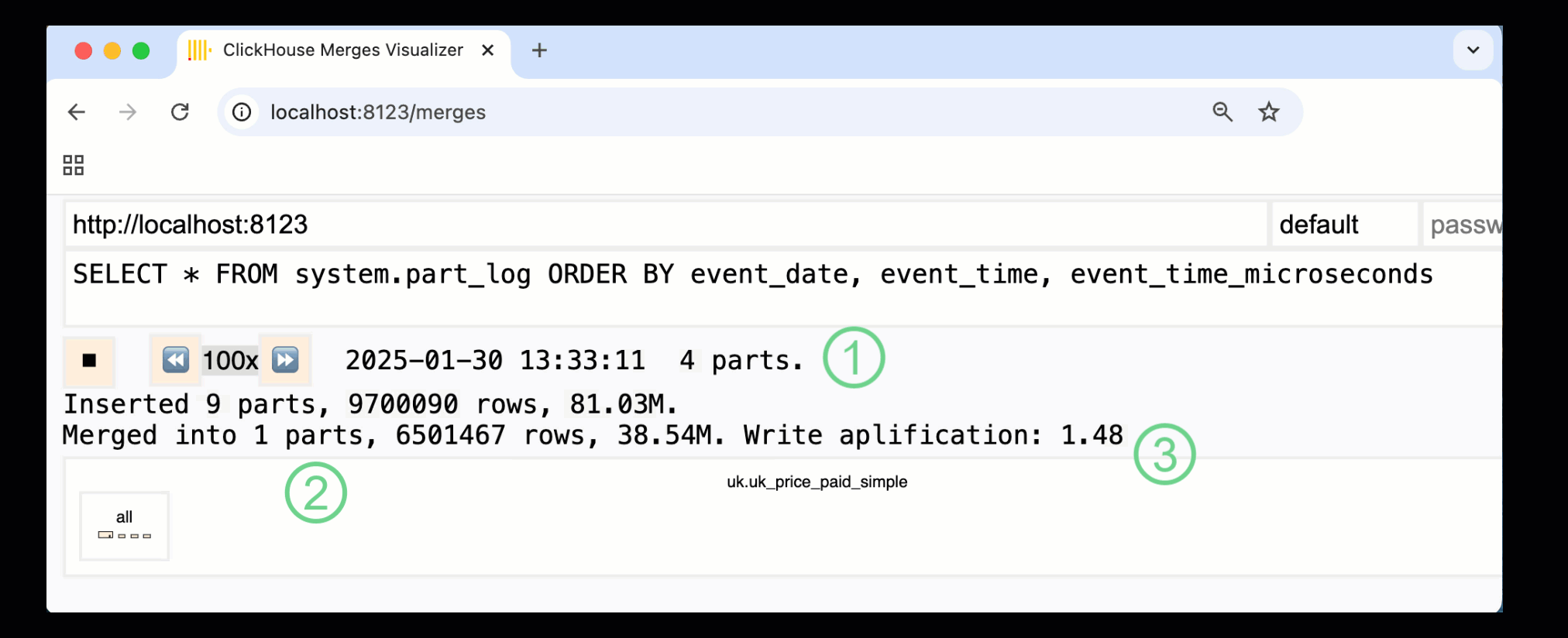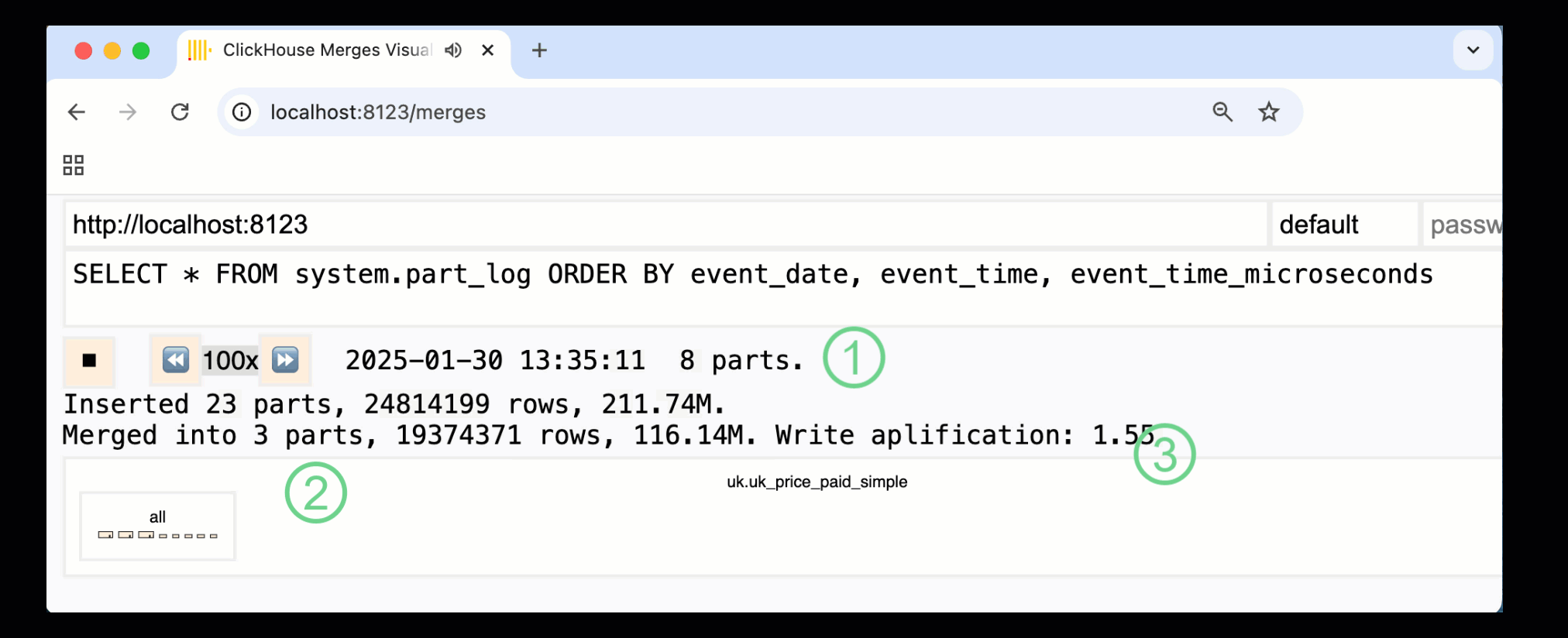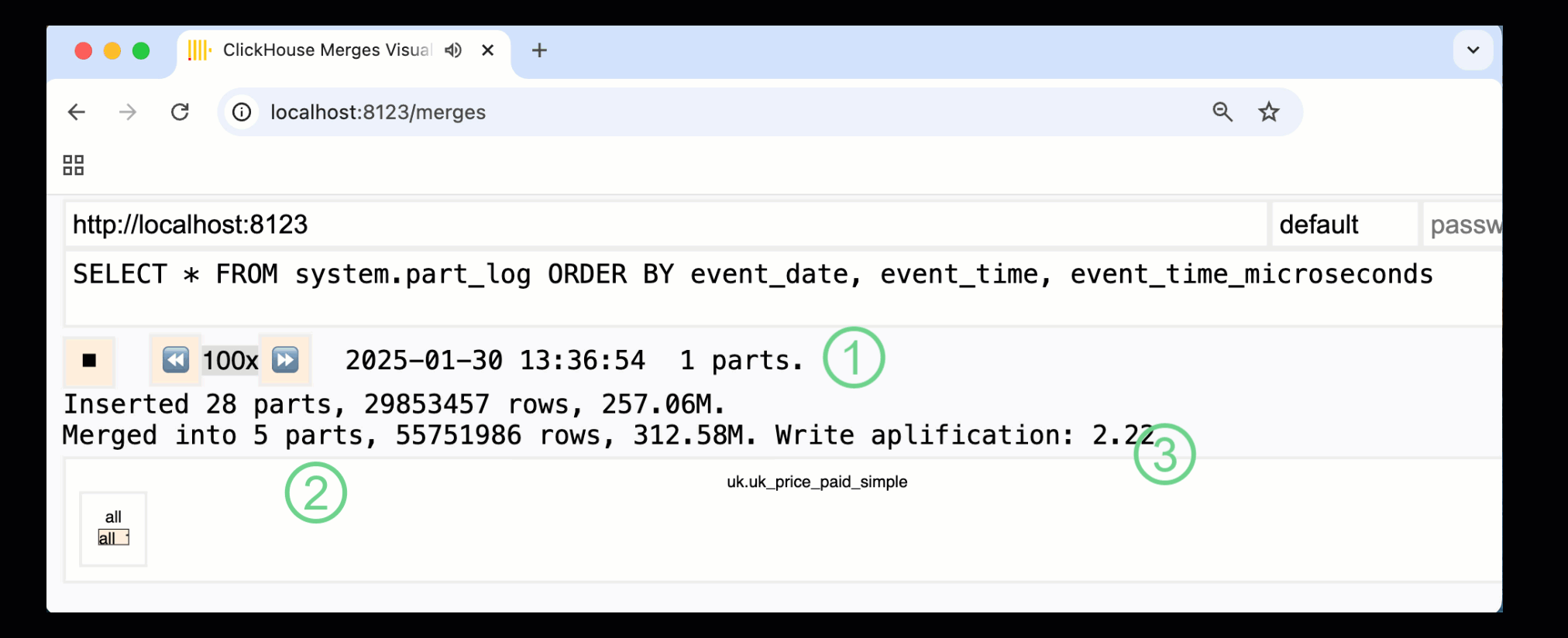
上のダッシュボードは、最初のデータ挿入から最終的に 1 つのパートへマージされるまでの全プロセスを捉えています。
① アクティブなパーツの数。
② パートマージ。ボックスで視覚的に表現されており (サイズはパートの大きさを反映しています) 。
同時マージ
1 台の ClickHouse サーバーは、複数のバックグラウンドマージスレッドを使用して、パーツマージを並行して実行します。
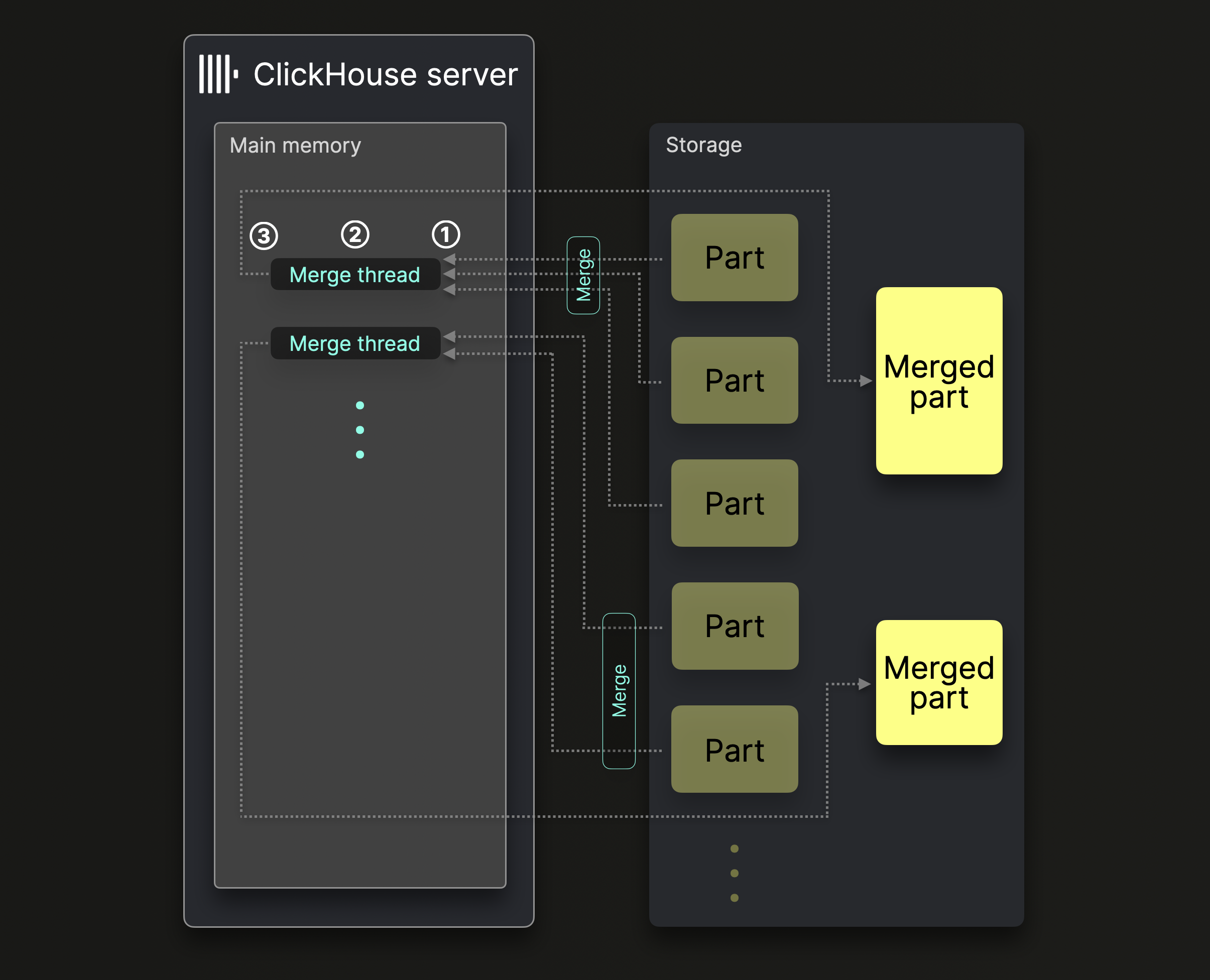
各マージスレッドは次のループを実行します。
① 次にどのパーツをマージするかを決定し、それらのパーツをメモリに読み込みます。
② メモリ上でパーツをマージして、より大きな 1 つのパーツにします。
③ マージされたパーツをディスクに書き込みます。
① に戻る
CPU コア数と RAM 容量を増やすことで、バックグラウンドマージのスループットを高めることができます。
メモリ最適化されたマージ
ClickHouse は、前の例で示したように、マージ対象となるすべてのパーツを必ずしも一度にメモリへ読み込むわけではありません。いくつかの要因に応じて、メモリ消費量を削減する (マージ速度を犠牲にする) ために、いわゆる垂直マージを用い、パーツを一度にではなく、ブロックのchunkごとに読み込んでマージします。
マージの仕組み
下の図は、ClickHouse における単一のバックグラウンドマージスレッドが、 (デフォルトではバーティカルマージなしで) パーツをどのようにマージするかを示しています:
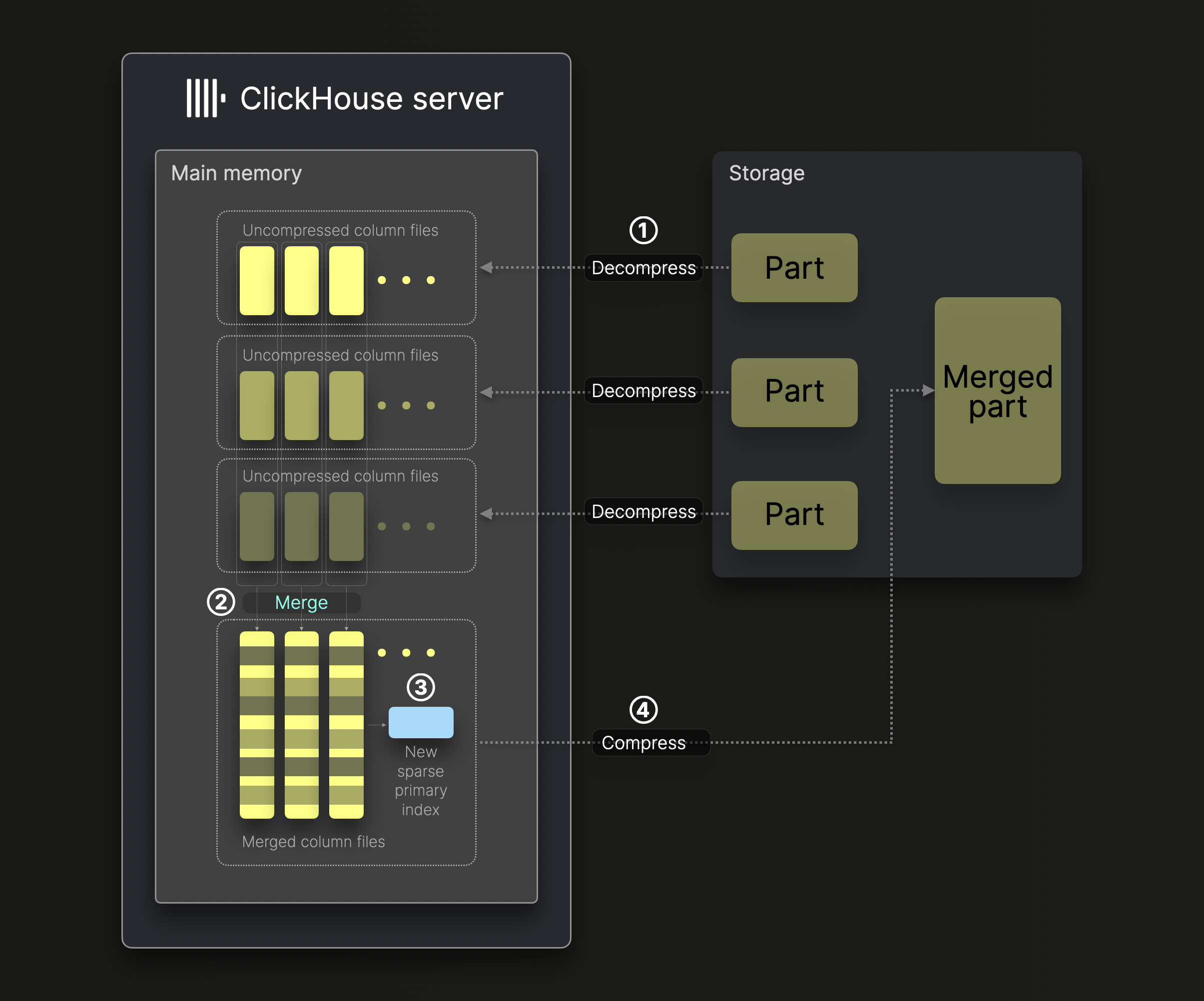
パーツのマージは、次のステップで行われます:
① 解凍と読み込み: マージ対象のパーツから取得した圧縮済みバイナリカラムファイルを解凍し、メモリに読み込みます。
② マージ: データをより大きなカラムファイルにマージします。
③ インデックス作成: マージ後のカラムファイルに対して、新しい疎なプライマリインデックスを生成します。
④ 圧縮と保存: 新しいカラムファイルとインデックスを圧縮し、マージ後のデータパーツを表す新しいディレクトリに保存します。
セカンダリのデータスキップインデックス、カラム統計情報、チェックサム、min-max インデックスなどのデータパーツ内の追加メタデータも、マージ後のカラムファイルに基づいて再生成されます。ここでは説明を簡潔にするため、これらの詳細は省略しています。
ステップ ② の動作は、使用している特定の MergeTree エンジンに依存します。エンジンごとにマージ処理の方法が異なり、たとえば行が集約されたり、古い行が置き換えられたりすることがあります。前述のとおり、このアプローチによりすべてのデータ処理がバックグラウンドのマージにオフロードされ、書き込み処理を軽量かつ効率的に保つことで、極めて高速な挿入を実現します。
次に、MergeTree ファミリー内の特定のエンジンにおけるマージの仕組みについて、簡単に概観します。
標準的なマージ
以下の図は、標準的な MergeTree テーブルにおいてパーツがどのようにマージされるかを示しています。
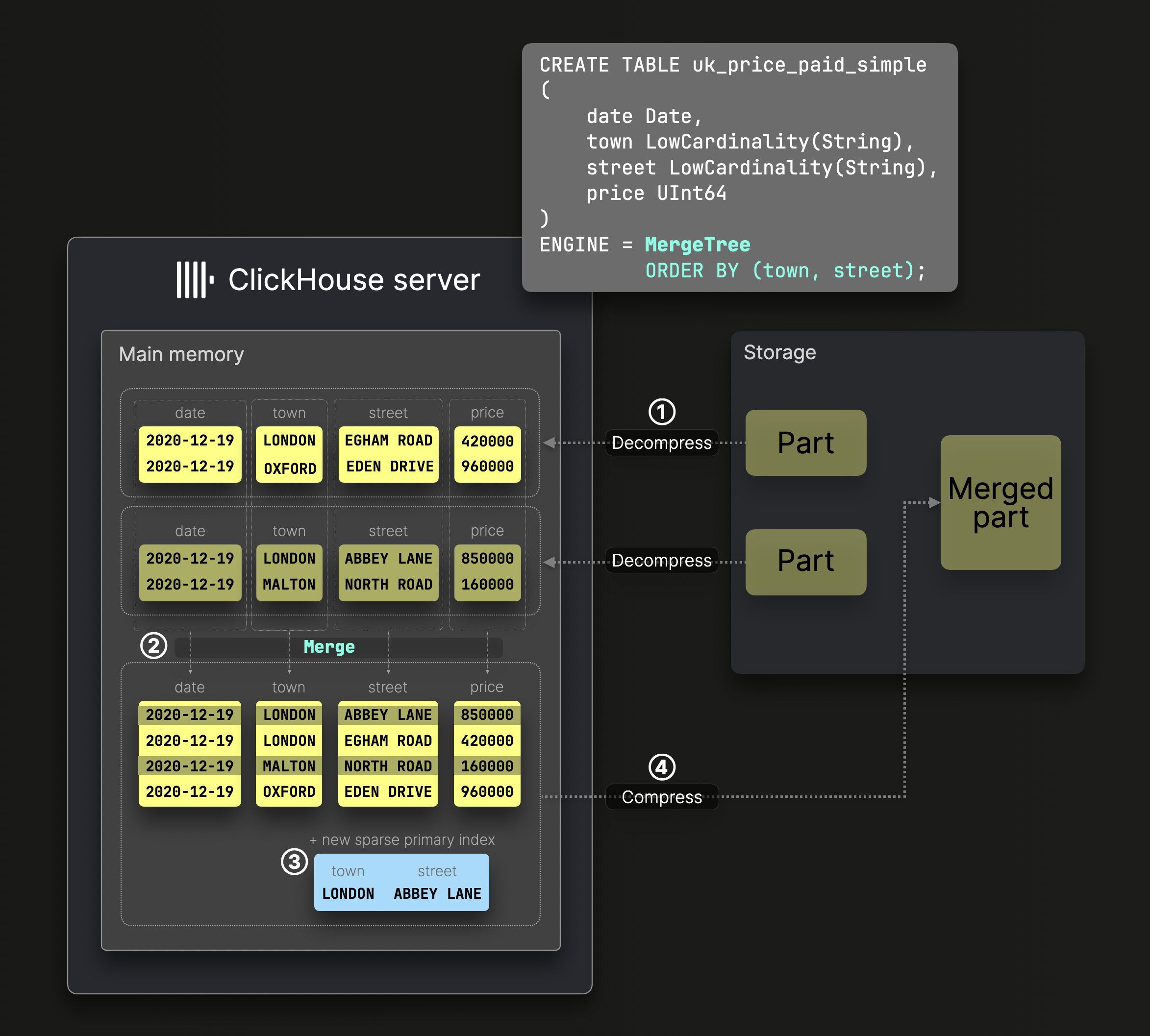
上図の DDL 文は、ソートキー (town, street) を持つ MergeTree テーブルを作成します。これは、ディスク上のデータがこれらのカラムでソートされ、それに応じてスパースなプライマリインデックスが生成されることを意味します。
① 解凍され事前にソート済みのテーブルカラムが、テーブルのソートキーによって定義されるテーブル全体のソート順を維持したまま ② マージされ、③ 新しいスパースなプライマリインデックスが生成され、④ マージされたカラムファイルとインデックスが圧縮されて、新しいデータパーツとしてディスクに保存されます。
置換マージ
ReplacingMergeTree テーブルにおけるパーツマージは 標準的なマージ と同様に動作しますが、各行について最新バージョンのみが保持され、古いバージョンは破棄されます。
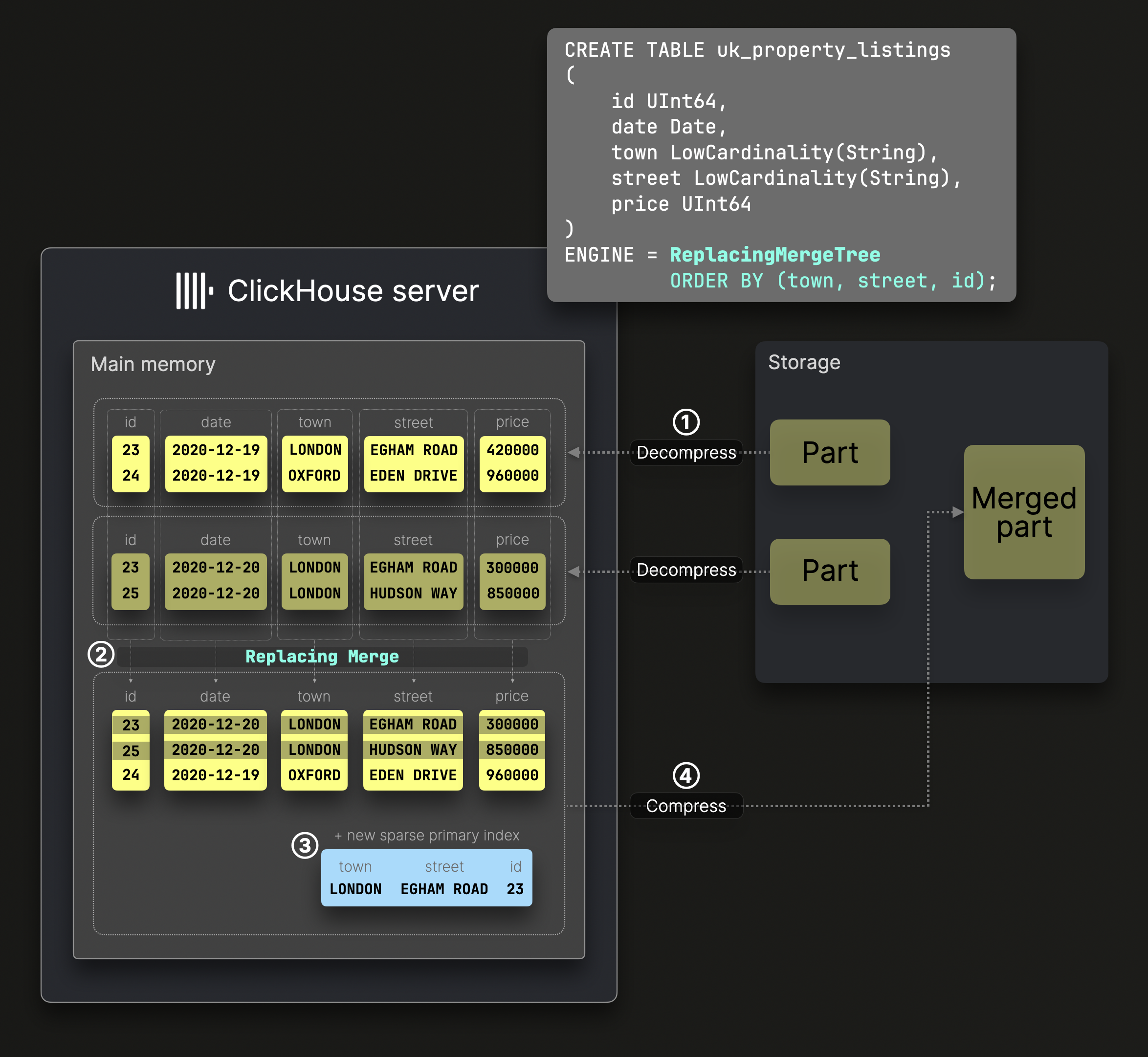
上図の DDL 文は、ソートキー (town, street, id) を持つ ReplacingMergeTree テーブルを作成します。これは、ディスク上のデータがこれらのカラムでソートされ、それに応じてスパースなプライマリインデックスが生成されることを意味します。
② のマージは標準的な MergeTree テーブルと同様に動作し、グローバルなソート順を維持しながら、解凍済みで事前ソートされたカラムを結合します。
ただし、ReplacingMergeTree は同じソートキーを持つ重複行を削除し、それを含むパーツの作成タイムスタンプに基づいて、最新の行のみを保持します。
集計マージ
数値データは、SummingMergeTree テーブルのパーツマージ中に自動的に集計されます。
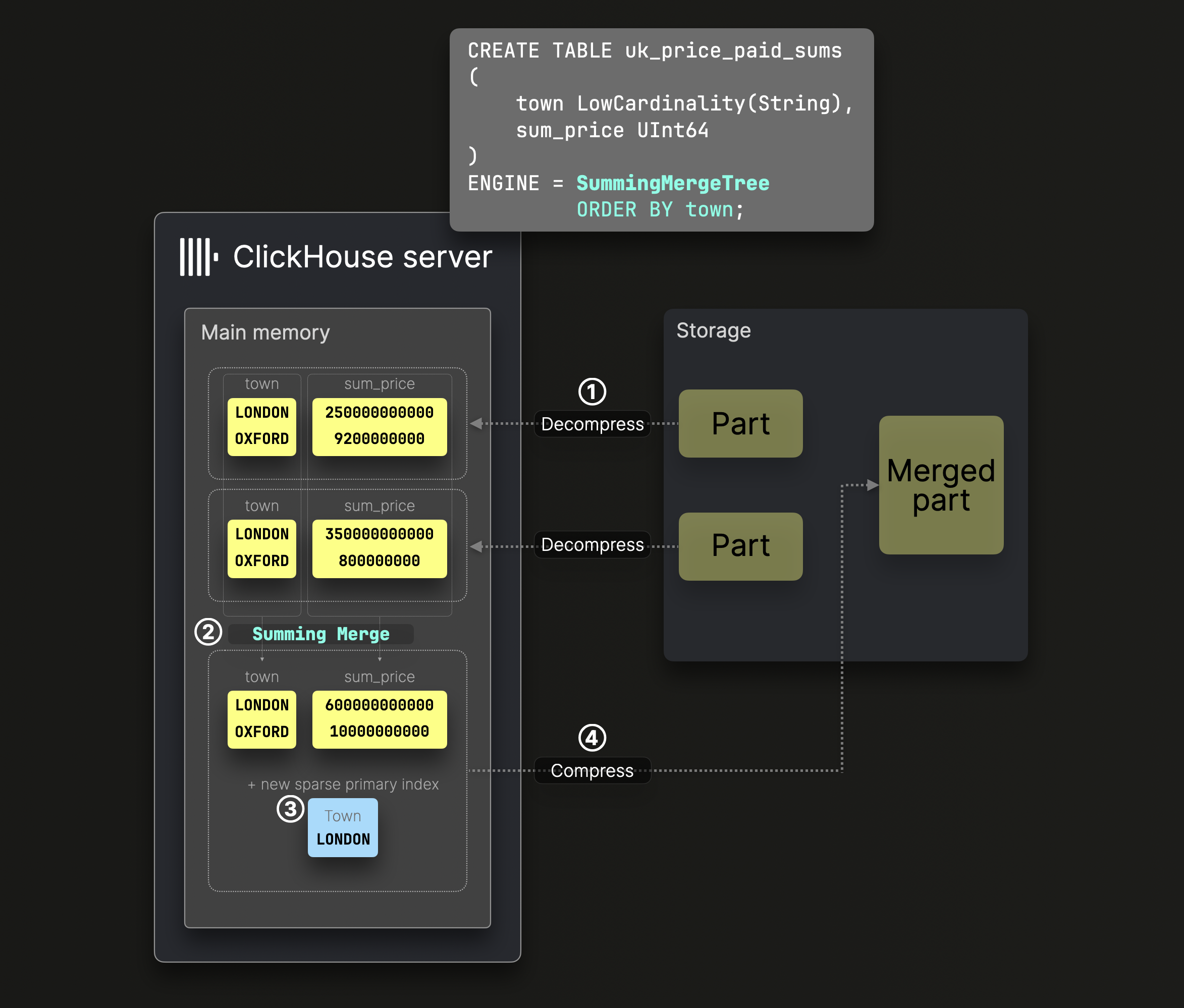
上図の DDL 文は、town をソートキーとする SummingMergeTree テーブルを定義しています。これは、ディスク上のデータがこのカラムでソートされ、それに応じてスパースなプライマリインデックスが作成されることを意味します。
② のマージ処理ステップでは、ClickHouse は同じソートキーを持つすべての行を 1 行に集約し、数値カラムの値を合計します。
集約マージ
上の SummingMergeTree テーブルの例は、AggregatingMergeTree テーブルの特殊なバリアントであり、パーツマージ中に 90+ の任意の集計関数を適用することで、自動インクリメンタルデータ変換 を可能にします。
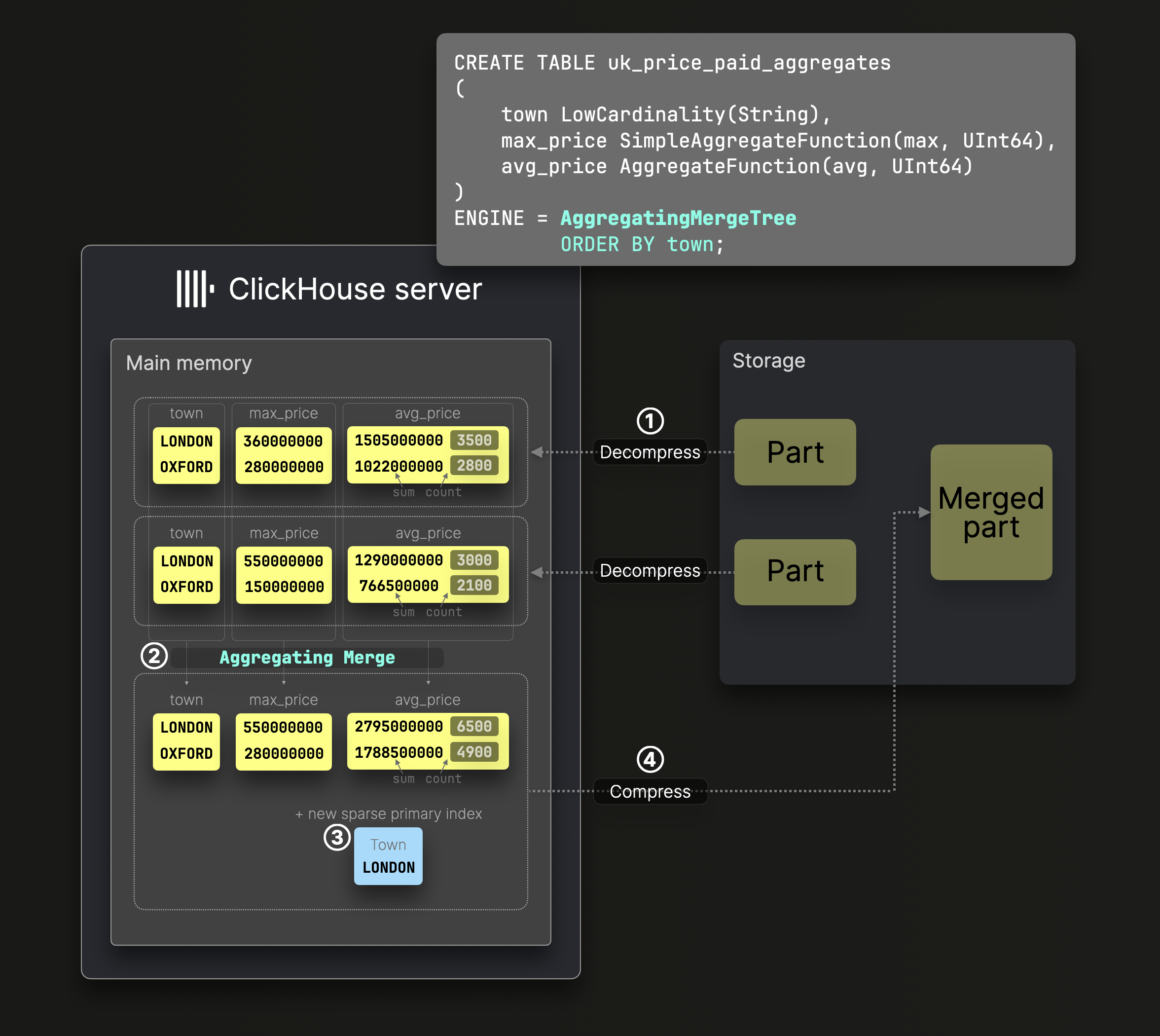
上図の DDL 文は、town をソートキーとする AggregatingMergeTree テーブルを作成します。これにより、ディスク上でデータがこのカラムでソートされ、対応するスパースなプライマリインデックスが生成されます。
② のマージ中、ClickHouse は同じソートキーを持つすべての行を、部分集約状態(例: avg() 向けの sum と count)を格納する 1 つの行に置き換えます。これらの状態により、インクリメンタルなバックグラウンドマージを通じて正確な結果が保証されます。
