インクリメンタルmaterialized view
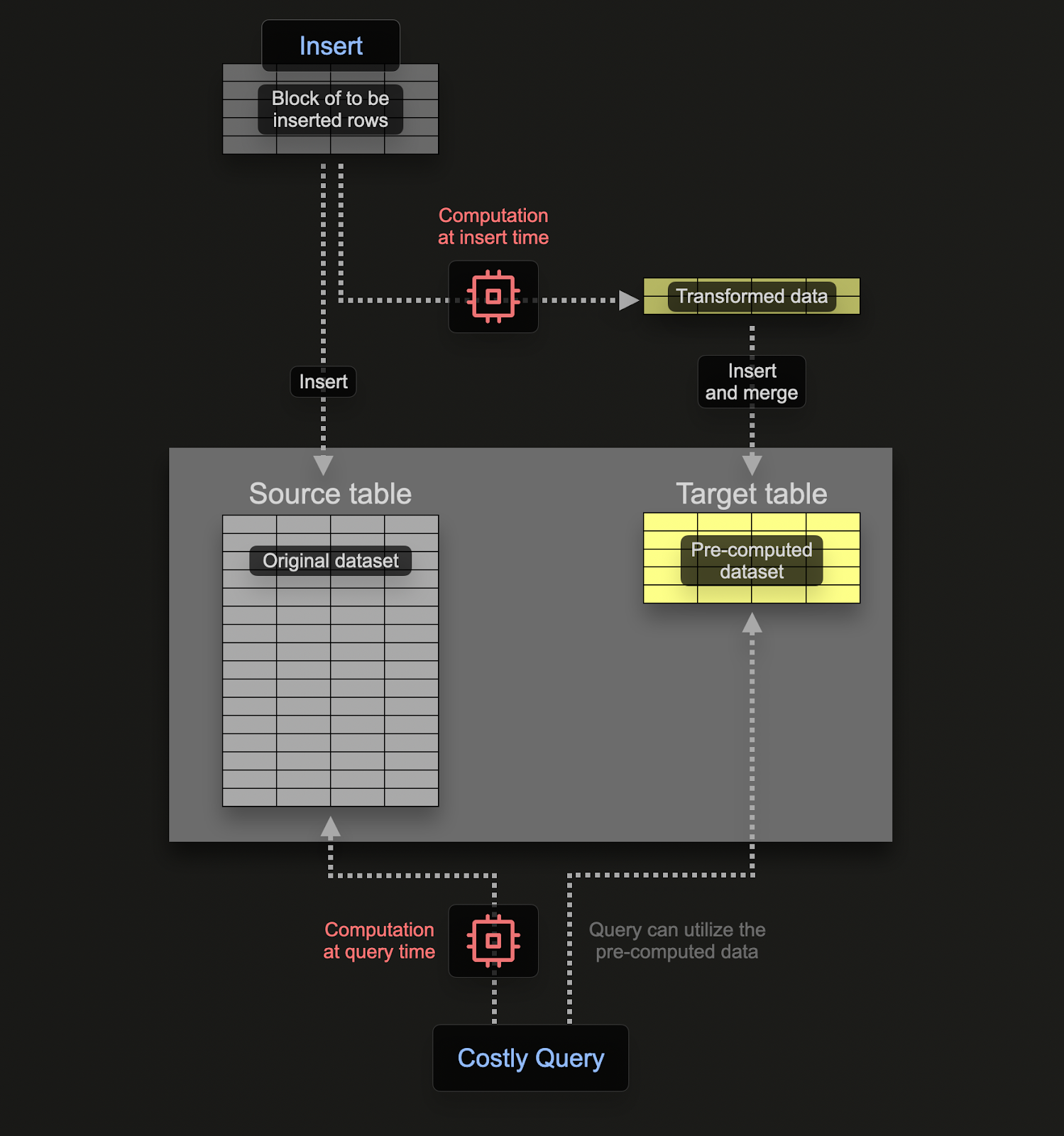
インクリメンタルmaterialized view(以下、materialized view)を使用すると、計算コストをクエリ実行時から挿入時に移し替えることで、SELECT クエリを高速化できます。
Postgres のようなトランザクション型データベースとは異なり、ClickHouse の materialized view は、テーブルにデータブロックが挿入される際にクエリを実行するトリガーにすぎません。このクエリの結果は 2 つ目の「ターゲット」テーブルに挿入されます。さらに行が挿入されると、結果は再度ターゲットテーブルに送られ、中間結果が更新・マージされます。このマージされた結果は、元のすべてのデータに対してクエリを実行した場合と同等のものです。
Materialized Views の主な目的は、ターゲットテーブルに挿入される結果が、行に対する集計・フィルタリング・変換の結果を表す点にあります。これらの結果は、多くの場合、元のデータをよりコンパクトに表現したもの(集計の場合は部分的なスケッチ(近似表現))となります。これに加えて、ターゲットテーブルから結果を読み取るためのクエリが単純になることで、同じ計算を元データに対して実行する場合と比べてクエリ時間が短くなり、計算(ひいてはクエリレイテンシ)がクエリ実行時から挿入時に移動します。
ClickHouse の materialized view は、ベースとなるテーブルにデータが流入するとリアルタイムで更新され、継続的に更新される索引のように機能します。これは、多くの他のデータベースでは Materialized Views が通常、リフレッシュが必要なクエリの静的なスナップショット(ClickHouse の Refreshable Materialized Views に類似)として扱われるのとは対照的です。
この例では、"Schema Design" で説明されている Stack Overflow データセットを使用します。
ある投稿について、日ごとの賛成票と反対票の数を取得したいとします。
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 29.359 sec. Processed 238.98 million rows, 2.13 GB (8.14 million rows/s., 72.45 MB/s.)
これは、toStartOfDay 関数のおかげで、ClickHouse では比較的シンプルなクエリになります。
SELECT toStartOfDay(CreationDate) AS day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY day
ORDER BY day ASC
LIMIT 10
┌─────────────────day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 00:00:00 │ 6 │ 0 │
│ 2008-08-01 00:00:00 │ 182 │ 50 │
│ 2008-08-02 00:00:00 │ 436 │ 107 │
│ 2008-08-03 00:00:00 │ 564 │ 100 │
│ 2008-08-04 00:00:00 │ 1306 │ 259 │
│ 2008-08-05 00:00:00 │ 1368 │ 269 │
│ 2008-08-06 00:00:00 │ 1701 │ 211 │
│ 2008-08-07 00:00:00 │ 1544 │ 211 │
│ 2008-08-08 00:00:00 │ 1241 │ 212 │
│ 2008-08-09 00:00:00 │ 576 │ 46 │
└─────────────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.133 sec. Processed 238.98 million rows, 2.15 GB (1.79 billion rows/s., 16.14 GB/s.)
Peak memory usage: 363.22 MiB.
このクエリは ClickHouse のおかげですでに高速ですが、さらに高速化できるでしょうか?
挿入時に materialized view を使ってこれを計算したい場合、その結果を受け取るテーブルが必要です。このテーブルは 1 日あたり 1 行のみを保持する必要があります。既存の日付に対する更新を受信した場合、他のカラムは既存の日付の行にマージされる必要があります。この増分状態をマージできるようにするには、他のカラムについて部分的な状態を保存しておく必要があります。
これには ClickHouse では特別な種類のエンジンが必要です。それが SummingMergeTree です。これは、同じソートキーを持つすべての行を、数値カラムの合計値を含む 1 行に置き換えます。次のテーブルは、同じ日付を持つ行をマージし、数値カラムを合計します。
CREATE TABLE up_down_votes_per_day
(
`Day` Date,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = SummingMergeTree
ORDER BY Day
この materialized view を説明するために、votes テーブルが空で、まだ一切データを受信していないものとします。materialized view は、votes に挿入されたデータに対して上記の SELECT を実行し、その結果を up_down_votes_per_day に保存します。
CREATE MATERIALIZED VIEW up_down_votes_per_day_mv TO up_down_votes_per_day AS
SELECT toStartOfDay(CreationDate)::Date AS Day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY Day
ここでの TO 句が重要で、結果の送信先、つまり up_down_votes_per_day を指定しています。
先ほどの INSERT 文を使って、votes テーブルに再度データを投入できます。
INSERT INTO votes SELECT toUInt32(Id) AS Id, toInt32(PostId) AS PostId, VoteTypeId, CreationDate, UserId, BountyAmount
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 111.964 sec. Processed 477.97 million rows, 3.89 GB (4.27 million rows/s., 34.71 MB/s.)
Peak memory usage: 283.49 MiB.
完了したら、up_down_votes_per_day の行数を確認します。1 日あたり 1 行になっているはずです。
SELECT count()
FROM up_down_votes_per_day
FINAL
┌─count()─┐
│ 5723 │
└─────────┘
ここでは、votes の 2 億 3,800 万行から、クエリ結果を保存することで 5,000 行まで実質的に削減しました。ここで重要なのは、votes テーブルに新しい投票が挿入されると、その該当日についての新しい値が up_down_votes_per_day に送られ、バックグラウンドで非同期に自動マージされる点です。その結果、1 日あたり 1 行のみが保持されます。したがって、up_down_votes_per_day は常に小さく、かつ最新の状態に保たれます。
行のマージは非同期で行われるため、ユーザがクエリを実行した時点では、1 日あたり複数の行が存在している可能性があります。クエリ時に未マージの行を確実にマージするには、次の 2 つの方法があります。
- テーブル名に
FINAL 修飾子を付けて使用する。上記のカウントクエリではこれを行いました。
- 最終テーブルで使用している並び替えキー、すなわち
CreationDate で集約し、メトリクスを合計する。通常、こちらの方が効率的で柔軟性があります(テーブルを他の用途にも使える)が、前者の方が一部のクエリではよりシンプルです。以下に両方の方法を示します。
SELECT
Day,
UpVotes,
DownVotes
FROM up_down_votes_per_day
FINAL
ORDER BY Day ASC
LIMIT 10
10 rows in set. Elapsed: 0.004 sec. Processed 8.97 thousand rows, 89.68 KB (2.09 million rows/s., 20.89 MB/s.)
Peak memory usage: 289.75 KiB.
SELECT Day, sum(UpVotes) AS UpVotes, sum(DownVotes) AS DownVotes
FROM up_down_votes_per_day
GROUP BY Day
ORDER BY Day ASC
LIMIT 10
┌────────Day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 │ 6 │ 0 │
│ 2008-08-01 │ 182 │ 50 │
│ 2008-08-02 │ 436 │ 107 │
│ 2008-08-03 │ 564 │ 100 │
│ 2008-08-04 │ 1306 │ 259 │
│ 2008-08-05 │ 1368 │ 269 │
│ 2008-08-06 │ 1701 │ 211 │
│ 2008-08-07 │ 1544 │ 211 │
│ 2008-08-08 │ 1241 │ 212 │
│ 2008-08-09 │ 576 │ 46 │
└────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.010 sec. Processed 8.97 thousand rows, 89.68 KB (907.32 thousand rows/s., 9.07 MB/s.)
Peak memory usage: 567.61 KiB.
これにより、クエリの処理時間は 0.133 秒から 0.004 秒に短縮され、25 倍以上高速化されました。
情報
重要: ORDER BY = GROUP BYほとんどの場合、materialized view の変換処理における GROUP BY 句で使用するカラムは、ターゲットテーブルで SummingMergeTree または AggregatingMergeTree テーブルエンジンを使用している場合、そのテーブルの ORDER BY 句で使用するカラムと一致させる必要があります。これらのエンジンは、バックグラウンドのマージ処理中に同一値を持つ行をマージするために ORDER BY カラムに依存しています。GROUP BY と ORDER BY のカラムが揃っていないと、クエリ性能の低下、不適切なマージ、さらにはデータ不整合を招く可能性があります。
より複雑な例
上記の例では、1 日あたり 2 つの合計値を計算・維持するために Materialized Views を使用しています。合計値は中間状態を維持するための最も単純な集約形式であり、新しい値が到着したときに既存の値に加算するだけで済みます。ただし、ClickHouse の Materialized Views はあらゆる種類の集約に利用できます。
ここでは、各日の投稿についていくつかの統計量を計算したいとします。具体的には、Score の 99.9 パーセンタイル値と CommentCount の平均値です。これを計算するクエリは次のようになります。
SELECT
toStartOfDay(CreationDate) AS Day,
quantile(0.999)(Score) AS Score_99th,
avg(CommentCount) AS AvgCommentCount
FROM posts
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
┌─────────────────Day─┬────────Score_99th─┬────AvgCommentCount─┐
│ 2024-03-31 00:00:00 │ 5.23700000000008 │ 1.3429811866859624 │
│ 2024-03-30 00:00:00 │ 5 │ 1.3097158891616976 │
│ 2024-03-29 00:00:00 │ 5.78899999999976 │ 1.2827635327635327 │
│ 2024-03-28 00:00:00 │ 7 │ 1.277746158224246 │
│ 2024-03-27 00:00:00 │ 5.738999999999578 │ 1.2113264918282023 │
│ 2024-03-26 00:00:00 │ 6 │ 1.3097536945812809 │
│ 2024-03-25 00:00:00 │ 6 │ 1.2836721018539201 │
│ 2024-03-24 00:00:00 │ 5.278999999999996 │ 1.2931667891256429 │
│ 2024-03-23 00:00:00 │ 6.253000000000156 │ 1.334061135371179 │
│ 2024-03-22 00:00:00 │ 9.310999999999694 │ 1.2388059701492538 │
└─────────────────────┴───────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.113 sec. Processed 59.82 million rows, 777.65 MB (528.48 million rows/s., 6.87 GB/s.)
Peak memory usage: 658.84 MiB.
前と同様に、posts テーブルに新しい投稿が挿入されるたびに、上記のクエリを実行する materialized view を作成できます。
サンプル用であり、かつ S3 から投稿データを読み込むことを避けるために、posts と同じスキーマを持つ複製テーブル posts_null を作成します。ただし、このテーブルはデータを一切保存せず、行が挿入されたときに materialized view によって参照されるだけです。データの保存を防ぐためには、Null table engine type を使用できます。
CREATE TABLE posts_null AS posts ENGINE = Null
Null テーブルエンジンは強力な最適化機構で、/dev/null のようなものと考えることができます。posts_null テーブルが挿入時に行を受け取ると、materialized view がサマリー統計量を計算して保存しますが、これはトリガーの役割を果たすだけです。ただし、生データは保存されません。この例ではおそらく元の投稿データも保存しておきたいところですが、この手法を使うことで、生データの保存コストを避けつつ集計値を計算できます。
このように、materialized view は次のようになります。
CREATE MATERIALIZED VIEW post_stats_mv TO post_stats_per_day AS
SELECT toStartOfDay(CreationDate) AS Day,
quantileState(0.999)(Score) AS Score_quantiles,
avgState(CommentCount) AS AvgCommentCount
FROM posts_null
GROUP BY Day
集約関数の末尾にサフィックスとして State を付与している点に注目してください。これにより、関数の最終結果ではなく、関数の集約状態が返されます。この集約状態には、他の状態とマージできるようにするための追加情報が含まれます。たとえば平均値の場合、対象カラムの件数と合計が含まれます。
正しい結果を計算するには、部分集約状態が必要です。たとえば平均値を計算する場合、部分範囲ごとの平均値を単に平均しても、正しい結果にはなりません。
次に、これらの部分集約状態を保存するための、VIEW post_stats_per_day のターゲットテーブルを作成します。
CREATE TABLE post_stats_per_day
(
`Day` Date,
`Score_quantiles` AggregateFunction(quantile(0.999), Int32),
`AvgCommentCount` AggregateFunction(avg, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY Day
以前は SummingMergeTree だけでカウントを保存するには十分でしたが、他の関数向けには、より高度なエンジンタイプが必要になります。それが AggregatingMergeTree です。
ClickHouse が集約状態を保存することを認識できるようにするために、Score_quantiles と AvgCommentCount の型を AggregateFunction として定義し、部分状態を生成する関数と、その元となるカラムの型を指定します。SummingMergeTree と同様に、同じ ORDER BY キー値を持つ行はマージされます(上記の例では Day)。
materialized view を介して post_stats_per_day にデータを投入するには、posts から posts_null にすべての行を単純に挿入するだけで済みます。
INSERT INTO posts_null SELECT * FROM posts
0 rows in set. Elapsed: 13.329 sec. Processed 119.64 million rows, 76.99 GB (8.98 million rows/s., 5.78 GB/s.)
本番環境では、通常この materialized view を posts テーブルに関連付けます。ここでは、null テーブルを示すために posts_null を使用しています。
最終的なクエリでは、(カラムが部分集計の状態を保持しているため)関数に Merge というサフィックスを付けて使用する必要があります。
SELECT
Day,
quantileMerge(0.999)(Score_quantiles),
avgMerge(AvgCommentCount)
FROM post_stats_per_day
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
ここでは FINAL ではなく GROUP BY を使用していることに注意してください。
その他の用途
上記では主に、Materialized View を使用してデータの部分集計をインクリメンタルに更新し、計算処理をクエリ実行時から挿入時へと移す方法に焦点を当てました。この一般的なユースケースに加えて、Materialized View には他にもさまざまな用途があります。
状況によっては、挿入時に行やカラムの一部だけを挿入したい場合があります。この場合、posts_null テーブルで挿入を受け付け、その後に SELECT クエリで行をフィルタリングしてから posts テーブルに挿入できます。例えば、posts テーブル内の Tags カラムを変換したいとします。これはタグ名をパイプ区切りで格納したリストです。これらを配列に変換することで、個々のタグ値ごとに集計しやすくなります。
この変換は INSERT INTO SELECT を実行する際に行うこともできます。materialized view を利用すると、このロジックを ClickHouse の DDL として定義し、INSERT 自体はシンプルなまま、新しい行に対して自動的に変換を適用できます。
この変換用の materialized view は以下のようになります。
CREATE MATERIALIZED VIEW posts_mv TO posts AS
SELECT * EXCEPT Tags, arrayFilter(t -> (t != ''), splitByChar('|', Tags)) as Tags FROM posts_null
ルックアップテーブル
ClickHouse の ORDER BY キーを選択する際には、そのアクセスパターンを考慮する必要があります。フィルタや集約句で頻繁に使用されるカラムを利用するべきです。これは、ユーザーがより多様なアクセスパターンを持ち、それらを単一のカラム集合に収められないシナリオでは制約となり得ます。たとえば、次のような comments テーブルを考えてみます。
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY PostId
0 rows in set. Elapsed: 46.357 sec. Processed 90.38 million rows, 11.14 GB (1.95 million rows/s., 240.22 MB/s.)
ここでの並び替えキーは、PostId でフィルタするクエリに対してテーブルを最適化します。
ユーザーが特定の UserId でフィルタし、そのユーザーの平均 Score を計算したいとします。
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.778 sec. Processed 90.38 million rows, 361.59 MB (116.16 million rows/s., 464.74 MB/s.)
Peak memory usage: 217.08 MiB.
高速ではありますが(ClickHouse にとってはデータ量が小さいため)、処理された行数が 9,038 万行であることから、フルテーブルスキャンが行われていると分かります。より大きなデータセットに対しては、フィルタリング対象のカラム UserId に対応する並び替えキー PostId の値をルックアップするために materialized view を使用できます。これらの値を使って効率的なルックアップを実行できます。
この例では、materialized view は非常にシンプルで、挿入時に comments から PostId と UserId のみを選択します。これらの結果は、UserId で並び替えられたテーブル comments_posts_users に送られます。以下で Comments テーブルの空バージョンを作成し、これを使って materialized view と comments_posts_users テーブルにデータを投入します。
CREATE TABLE comments_posts_users (
PostId UInt32,
UserId Int32
) ENGINE = MergeTree ORDER BY UserId
CREATE TABLE comments_null AS comments
ENGINE = Null
CREATE MATERIALIZED VIEW comments_posts_users_mv TO comments_posts_users AS
SELECT PostId, UserId FROM comments_null
INSERT INTO comments_null SELECT * FROM comments
0 rows in set. Elapsed: 5.163 sec. Processed 90.38 million rows, 17.25 GB (17.51 million rows/s., 3.34 GB/s.)
これで、この VIEW をサブクエリとして利用し、先ほどのクエリを高速化できます。
SELECT avg(Score)
FROM comments
WHERE PostId IN (
SELECT PostId
FROM comments_posts_users
WHERE UserId = 8592047
) AND UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 88.61 thousand rows, 771.37 KB (7.09 million rows/s., 61.73 MB/s.)
materialized view のチェーン/カスケード
materialized view はチェーン(またはカスケード)させることができ、複雑なワークフローを構築できます。
詳細は、ガイド「Cascading materialized views」を参照してください。
materialized view と JOIN
リフレッシャブルmaterialized view
以下の内容はインクリメンタルmaterialized view のみに適用されます。リフレッシャブルmaterialized view は、対象となる全データセットに対してクエリを定期的に実行し、JOIN を完全にサポートします。結果の鮮度がある程度低下しても許容できる場合は、複雑な JOIN にはリフレッシャブルmaterialized view の利用を検討してください。
ClickHouse におけるインクリメンタルmaterialized view は JOIN 操作を完全にサポートしますが、1 つ重要な制約があります。materialized view は、ソーステーブル(クエリ内の最も左側のテーブル)への挿入時にのみトリガーされるという点です。JOIN の右側のテーブルは、データが変更されても更新をトリガーしません。この挙動は、挿入時にデータを集約または変換する インクリメンタル materialized view を構築する際に特に重要です。
インクリメンタルmaterialized view が JOIN を使って定義されている場合、SELECT クエリ内の最も左側のテーブルがソースとして機能します。このテーブルに新しい行が挿入されると、ClickHouse は materialized view のクエリを、その新しく挿入された行に対して のみ 実行します。JOIN の右側のテーブルは、この実行中に全件読み出されますが、それらのテーブルだけが変更されても view はトリガーされません。
この挙動により、materialized view 上での JOIN は、静的なディメンションデータに対するスナップショット的な JOIN に近いものになります。
これは、リファレンスまたはディメンションテーブルを用いたデータの付加(エンリッチ)には有効です。ただし、右側のテーブル(例: ユーザーメタデータ)に対する更新は、materialized view を遡って更新しません。更新後のデータを反映させるには、ソーステーブルに新たな挿入が行われる必要があります。
Stack Overflow データセット を使った具体例を見ていきます。users テーブルからユーザーの表示名を含めて、ユーザーごとの1日あたりのバッジ数 を計算するために materialized view を使用します。
おさらいとして、テーブルスキーマは次のとおりです。
CREATE TABLE badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
CREATE TABLE users
(
`Id` Int32,
`Reputation` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`DisplayName` LowCardinality(String),
`LastAccessDate` DateTime64(3, 'UTC'),
`Location` LowCardinality(String),
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = MergeTree
ORDER BY Id;
users テーブルには既にデータが投入されている前提とします。
INSERT INTO users
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet');
materialized view と、それに関連付けられたターゲットテーブルは次のように定義されています:
CREATE TABLE daily_badges_by_user
(
Day Date,
UserId Int32,
DisplayName LowCardinality(String),
Gold UInt32,
Silver UInt32,
Bronze UInt32
)
ENGINE = SummingMergeTree
ORDER BY (DisplayName, UserId, Day);
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user AS
SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
グループ化と並び順の整合性
materialized view の GROUP BY 句には、SummingMergeTree ターゲットテーブルの ORDER BY と整合させるために、DisplayName、UserId、Day を含める必要があります。これにより、行が正しく集約・マージされます。いずれかを省略すると、誤った結果や非効率なマージにつながる可能性があります。
ここで badge データを投入すると、materialized view がトリガーされ、daily_badges_by_user テーブルにデータが書き込まれます。
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 433.762 sec. Processed 1.16 billion rows, 28.50 GB (2.67 million rows/s., 65.70 MB/s.)
特定のユーザーが獲得したバッジを表示したい場合、次のクエリを実行できます。
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
8 rows in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 642.14 KB (1.86 million rows/s., 36.44 MB/s.)
ここで、このユーザーに新しいバッジが付与されて行が挿入されると、VIEW が更新されます。
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2025-04-13 │ 2936484 │ gingerwizard │ 1 │ 0 │ 0 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
9 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 642.27 KB (1.96 million rows/s., 38.50 MB/s.)
注意
ここでの挿入処理のレイテンシに注目してください。挿入された user 行は users テーブル全体と JOIN されるため、挿入パフォーマンスに大きな影響があります。これに対処する手法については、以下の "フィルタおよび JOIN でソーステーブルを使用する" で説明します。
逆に、新しいユーザーに対して先に badge を挿入し、その後にユーザーの行を挿入した場合、materialized view はユーザーのメトリクスを正しく取りこぼすことなく取得できません。
INSERT INTO badges VALUES (53505059, 23923286, 'Good Answer', now(), 'Bronze', 0);
INSERT INTO users VALUES (23923286, 1, now(), 'brand_new_user', now(), 'UK', 1, 1, 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user';
0 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 644.32 KB (1.98 million rows/s., 38.94 MB/s.)
この場合、このビューは、ユーザーの行が存在する前に行われるバッジの挿入に対してのみ実行されます。ユーザーに対して別のバッジを挿入すると、期待どおり行が挿入されます。
INSERT INTO badges VALUES (53505060, 23923286, 'Teacher', now(), 'Bronze', 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user'
┌────────Day─┬───UserId─┬─DisplayName────┬─Gold─┬─Silver─┬─Bronze─┐
│ 2025-04-13 │ 23923286 │ brand_new_user │ 0 │ 0 │ 1 │
└────────────┴──────────┴────────────────┴──────┴────────┴────────┘
1 row in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 644.48 KB (1.87 million rows/s., 36.72 MB/s.)
ただし、この結果は誤っています。
materialized view における JOIN のベストプラクティス
-
左側のテーブルをトリガーとして使用する。 SELECT 文の左側にあるテーブルのみが materialized view をトリガーします。右側のテーブルへの変更では更新がトリガーされません。
-
結合対象のデータを事前に挿入する。 ソーステーブルに行を挿入する前に、JOIN 先テーブルに必要なデータが存在していることを確認します。JOIN は挿入時に評価されるため、データが欠けていると、マッチしない行や null が発生します。
-
JOIN から取得するカラムを絞り込む。 メモリ使用量を最小限に抑え、挿入時のレイテンシーを削減するために、JOIN 先テーブルからは必要なカラムのみを選択します(下記参照)。
-
挿入時のパフォーマンスを評価する。 JOIN は挿入コストを増加させます。特に右側のテーブルが大きい場合は顕著です。本番相当の代表的なデータを用いて挿入レートをベンチマークしてください。
-
単純なルックアップには Dictionary を優先して使う。 コストの高い JOIN 処理を避けるため、キー・バリュールックアップ(例: ユーザー ID から名前への対応)には Dictionaries を使用します。
-
GROUP BY と ORDER BY をマージ効率のために揃える。 SummingMergeTree や AggregatingMergeTree を使用する場合、ターゲットテーブルの ORDER BY 句と GROUP BY を一致させて、行のマージを効率的に行えるようにします。
-
明示的なカラムエイリアスを使用する。 テーブル間でカラム名が重複している場合は、あいまいさを防ぎ、ターゲットテーブルで正しい結果を得るためにエイリアスを使用します。
-
挿入量と頻度を考慮する。 JOIN は中程度の挿入ワークロードではうまく機能します。高スループットのインジェストが必要な場合は、ステージングテーブル、事前に JOIN を行う方式、あるいは Dictionary や Refreshable Materialized Views などの別手法の利用を検討してください。
フィルタおよび JOIN におけるソーステーブルの使用
ClickHouse で materialized view を扱う際には、その materialized view のクエリ実行時にソーステーブルがどのように扱われるかを理解しておくことが重要です。具体的には、materialized view のクエリ内にあるソーステーブルは、挿入中のデータブロックで置き換えられます。この動作を正しく理解していないと、予期しない結果につながる可能性があります。
シナリオ例
次のような構成を考えます。
CREATE TABLE t0 (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw1_inner (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw2_inner (`c0` Int) ENGINE = Memory;
CREATE VIEW vt0 AS SELECT * FROM t0;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN ( SELECT * FROM t0 ) AS x ON t0.c0 = x.c0;
CREATE MATERIALIZED VIEW mvw2 TO mvw2_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN vt0 ON t0.c0 = vt0.c0;
INSERT INTO t0 VALUES (1),(2),(3);
INSERT INTO t0 VALUES (1),(2),(3),(4),(5);
SELECT * FROM mvw1;
┌─c0─┐
│ 3 │
│ 5 │
└────┘
SELECT * FROM mvw2;
┌─c0─┐
│ 3 │
│ 8 │
└────┘
上記の例では、mvw1 と mvw2 という 2 つの materialized view があり、どちらも似た処理を行いますが、ソーステーブル t0 の参照方法にわずかな違いがあります。
mvw1 では、テーブル t0 は JOIN の右側にある (SELECT * FROM t0) サブクエリの中で直接参照されています。t0 にデータが挿入されると、その materialized view のクエリは、t0 の代わりに挿入されたデータブロックを用いて実行されます。これは、JOIN 処理がテーブル全体ではなく、新しく挿入された行に対してのみ実行されることを意味します。
2 つ目の vt0 との JOIN のケースでは、その VIEW は t0 からすべてのデータを読み取ります。これにより、JOIN 処理は新しく挿入されたブロックだけでなく、t0 内のすべての行を対象とすることが保証されます。
重要な違いは、ClickHouse が materialized view のクエリ内でソーステーブルをどのように扱うかにあります。materialized view が insert によってトリガーされると、ソーステーブル(この例では t0)は挿入されたデータブロックに置き換えられます。この挙動はクエリの最適化に活用できますが、一方で予期しない結果を避けるために注意深い検討も必要です。
ユースケースと注意点
実運用では、この動作を利用して、ソーステーブルのデータの一部だけを処理すればよい materialized view を最適化できます。たとえば、他のテーブルと結合する前に、サブクエリを使ってソーステーブルをフィルタリングできます。これにより、materialized view が処理するデータ量を減らし、パフォーマンスを向上させられます。
CREATE TABLE t0 (id UInt32, value String) ENGINE = MergeTree() ORDER BY id;
CREATE TABLE t1 (id UInt32, description String) ENGINE = MergeTree() ORDER BY id;
INSERT INTO t1 VALUES (1, 'A'), (2, 'B'), (3, 'C');
CREATE TABLE mvw1_target_table (id UInt32, value String, description String) ENGINE = MergeTree() ORDER BY id;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_target_table AS
SELECT t0.id, t0.value, t1.description
FROM t0
JOIN (SELECT * FROM t1 WHERE t1.id IN (SELECT id FROM t0)) AS t1
ON t0.id = t1.id;
この例では、IN (SELECT id FROM t0) サブクエリから構築される Set には新規に挿入された行のみが含まれており、その Set を使って t1 を絞り込むことができます。
スタックオーバーフローの例
users テーブルからユーザーの表示名を取得しつつ、ユーザーごとの日次バッジ数 を計算するための 先ほどの materialized view の例 を考えます。
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
このビューにより、badges テーブルへの挿入レイテンシが大きく悪化しました。例えば:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
上記のアプローチを用いて、このビューを最適化していきます。挿入されたバッジ行に含まれるユーザー ID を使って、users テーブルにフィルタ条件を追加します。
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN
(
SELECT
Id,
DisplayName
FROM users
WHERE Id IN (
SELECT UserId
FROM badges
)
) AS u ON b.UserId = u.Id
GROUP BY
Day,
b.UserId,
u.DisplayName
これはバッジの初回挿入処理を高速化するだけでなく、
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 132.118 sec. Processed 323.43 million rows, 4.69 GB (2.45 million rows/s., 35.49 MB/s.)
Peak memory usage: 1.99 GiB.
さらに、今後のバッジ挿入も効率的になります。
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 0.583 sec.
上記の操作では、ユーザー ID が 2936484 の行が users テーブルから 1 行だけ取得されます。このルックアップは、テーブルの並び替えキーとして Id 列を使用することで最適化されています。
materialized view と UNION
UNION ALL クエリは、複数のソーステーブルにあるデータを 1 つの結果セットに結合するためによく使用されます。
UNION ALL はインクリメンタルmaterialized view では直接サポートされていませんが、各 SELECT ブランチごとに個別の materialized view を作成し、その結果を共有のターゲットテーブルに書き込むことで、同じ結果を得ることができます。
この例では Stack Overflow データセットを使用します。以下の badges テーブルと comments テーブルを考えます。これらは、それぞれユーザーが獲得したバッジと、投稿に対して行ったコメントを表しています。
CREATE TABLE stackoverflow.comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY CreationDate
CREATE TABLE stackoverflow.badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
これらには次の INSERT INTO コマンドでデータを投入できます。
INSERT INTO stackoverflow.badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
INSERT INTO stackoverflow.comments SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/comments/*.parquet')
これら 2 つのテーブルを組み合わせて、各ユーザーの最新アクティビティを表示するユーザーアクティビティの統合ビューを作成したいとします。
SELECT
UserId,
argMax(description, event_time) AS last_description,
argMax(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
LIMIT 10
このクエリの結果を受け取るためのターゲットテーブルがあると仮定しましょう。AggregatingMergeTree テーブルエンジンと AggregateFunction を使用して、結果が正しくマージされるようにしている点に注意してください。
CREATE TABLE user_activity
(
`UserId` String,
`last_description` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`activity_type` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`last_activity` SimpleAggregateFunction(max, DateTime64(3, 'UTC'))
)
ENGINE = AggregatingMergeTree
ORDER BY UserId
badges または comments のいずれかに新しい行が挿入されるたびにこのテーブルを更新したい場合、この問題に対する素朴なアプローチとしては、前述の UNION クエリを使って materialized view を作成することが考えられます。
CREATE MATERIALIZED VIEW user_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(description, event_time) AS last_description,
argMaxState(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
構文的には正しいですが、意図しない結果になります。この VIEW は comments テーブルへの挿入に対してのみトリガーされます。たとえば、
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
badges テーブルへの挿入ではその VIEW はトリガーされないため、user_activity は更新されません。
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
この問題を解決するには、それぞれの SELECT 文に対して materialized view を作成します。
DROP TABLE user_activity_mv;
TRUNCATE TABLE user_activity;
CREATE MATERIALIZED VIEW comment_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Text, CreationDate) AS last_description,
argMaxState('comment', CreationDate) AS activity_type,
max(CreationDate) AS last_activity
FROM stackoverflow.comments
GROUP BY UserId;
CREATE MATERIALIZED VIEW badges_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Name, Date) AS last_description,
argMaxState('badge', Date) AS activity_type,
max(Date) AS last_activity
FROM stackoverflow.badges
GROUP BY UserId;
どちらのテーブルにデータを挿入しても、正しい結果が得られるようになりました。たとえば、comments テーブルに対して次のように挿入します。
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 10:18:47.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
同様に、badges テーブルへの挿入は user_activity テーブルにも反映されます。
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ gingerwizard │ badge │ 2025-04-15 10:20:18.000 │
└─────────┴──────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
並列処理と逐次処理
前の例で示したように、1 つのテーブルは複数の materialized view のソースとして機能できます。これらが実行される順序は、設定 parallel_view_processing によって決まります。
デフォルトでは、この設定は 0(false)であり、materialized view は uuid の順序で順次実行されます。
例として、次の source テーブルと、それぞれが target テーブルに行を送る 3 つの materialized view を考えます。
CREATE TABLE source
(
`message` String
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE TABLE target
(
`message` String,
`from` String,
`now` DateTime64(9),
`sleep` UInt8
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE MATERIALIZED VIEW mv_2 TO target
AS SELECT
message,
'mv2' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_3 TO target
AS SELECT
message,
'mv3' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_1 TO target
AS SELECT
message,
'mv1' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
それぞれの VIEW は、自身の名前と挿入時刻を含めつつ、target テーブルに行を挿入する前に 1 秒間一時停止することに注意してください。
source テーブルに 1 行を挿入するには約 3 秒かかり、それぞれの VIEW は順次実行されます。
INSERT INTO source VALUES ('test')
1 row in set. Elapsed: 3.786 sec.
SELECT 文を実行して、各ビューから行が到着していることを確認できます:
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 14:52:01.306162309 │
│ test │ mv1 │ 2025-04-15 14:52:02.307693521 │
│ test │ mv2 │ 2025-04-15 14:52:03.309250283 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.015 sec.
これは各 VIEW の uuid と対応しています:
SELECT
name,
uuid
FROM system.tables
WHERE name IN ('mv_1', 'mv_2', 'mv_3')
ORDER BY uuid ASC
┌─name─┬─uuid─────────────────────────────────┐
│ mv_3 │ ba5e36d0-fa9e-4fe8-8f8c-bc4f72324111 │
│ mv_1 │ b961c3ac-5a0e-4117-ab71-baa585824d43 │
│ mv_2 │ e611cc31-70e5-499b-adcc-53fb12b109f5 │
└──────┴──────────────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
一方で、parallel_view_processing=1 を有効にした状態で行を挿入するとどうなるかを考えてみます。これを有効にすると、VIEW は並列に実行され、行がターゲットテーブルに到着する順序については一切保証されません。
TRUNCATE target;
SET parallel_view_processing = 1;
INSERT INTO source VALUES ('test');
1 row in set. Elapsed: 1.588 sec.
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 19:47:32.242937372 │
│ test │ mv1 │ 2025-04-15 19:47:32.243058183 │
│ test │ mv2 │ 2025-04-15 19:47:32.337921800 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
各 VIEW からの行の到着順序は同じですが、これは保証されていません。各行の挿入時刻が近いことからもそれが分かります。また、挿入パフォーマンスが向上していることにも注目してください。
並列処理をいつ有効化するか
parallel_view_processing=1 を有効にすると、特に 1 つのテーブルに複数の Materialized Views がアタッチされている場合、上記のとおり挿入スループットが大きく向上する可能性があります。ただし、その際のトレードオフを理解しておくことが重要です。
- 挿入負荷の増大: すべての Materialized Views が同時に実行されるため、CPU とメモリ使用量が増加します。各 view が重い計算や JOIN を実行する場合、システムが過負荷になる可能性があります。
- 厳密な実行順序の必要性: view の実行順序が重要となる(例: 連鎖した依存関係がある)ワークフローではまれに、並列実行によって不整合な状態やレースコンディションが発生する可能性があります。これを回避するように設計することも可能ですが、そのような構成は脆く、将来のバージョンで動作しなくなる場合があります。
過去のデフォルトと安定性
逐次実行は長い間デフォルトでしたが、その一因としてエラー処理の複雑さがありました。歴史的には、1 つの materialized view の失敗によって、他の view の実行が妨げられることがありました。新しいバージョンではブロック単位で失敗を分離することでこの点が改善されていますが、逐次実行は依然として失敗時の挙動をより明確にします。
一般的には、次のような場合に parallel_view_processing=1 を有効化します:
- 複数の独立した Materialized Views がある場合
- 挿入パフォーマンスの最大化を目指している場合
- view の同時実行を処理できるシステムのキャパシティを把握している場合
次のような場合は無効のままにしておきます:
- Materialized Views 同士に依存関係がある場合
- 予測可能で順序どおりの実行が必要な場合
- 挿入動作のデバッグや監査を行っており、決定的なリプレイを行いたい場合
materialized view と共通テーブル式 (CTE)
非再帰的な 共通テーブル式 (CTE) は materialized view でサポートされています。
注記
共通テーブル式は マテリアライズされませんClickHouse は CTE をマテリアライズしません。その代わり、CTE の定義をそのままクエリ内に展開します。このため、(CTE が 2 回以上使用される場合には)同じ式が複数回評価される可能性があります。
各投稿タイプごとの日次アクティビティを計算する、次の例を考えます。
CREATE TABLE daily_post_activity
(
Day Date,
PostType String,
PostsCreated SimpleAggregateFunction(sum, UInt64),
AvgScore AggregateFunction(avg, Int32),
TotalViews SimpleAggregateFunction(sum, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (Day, PostType);
CREATE MATERIALIZED VIEW daily_post_activity_mv TO daily_post_activity AS
WITH filtered_posts AS (
SELECT
toDate(CreationDate) AS Day,
PostTypeId,
Score,
ViewCount
FROM posts
WHERE Score > 0 AND PostTypeId IN (1, 2) -- Question or Answer
)
SELECT
Day,
CASE PostTypeId
WHEN 1 THEN 'Question'
WHEN 2 THEN 'Answer'
END AS PostType,
count() AS PostsCreated,
avgState(Score) AS AvgScore,
sum(ViewCount) AS TotalViews
FROM filtered_posts
GROUP BY Day, PostTypeId;
ここではCTEは厳密には不要ですが、例示のために使用しており、このVIEWは期待どおりに動作します。
INSERT INTO posts
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SELECT
Day,
PostType,
avgMerge(AvgScore) AS AvgScore,
sum(PostsCreated) AS PostsCreated,
sum(TotalViews) AS TotalViews
FROM daily_post_activity
GROUP BY
Day,
PostType
ORDER BY Day DESC
LIMIT 10
┌────────Day─┬─PostType─┬───────────AvgScore─┬─PostsCreated─┬─TotalViews─┐
│ 2024-03-31 │ Question │ 1.3317757009345794 │ 214 │ 9728 │
│ 2024-03-31 │ Answer │ 1.4747191011235956 │ 356 │ 0 │
│ 2024-03-30 │ Answer │ 1.4587912087912087 │ 364 │ 0 │
│ 2024-03-30 │ Question │ 1.2748815165876777 │ 211 │ 9606 │
│ 2024-03-29 │ Question │ 1.2641509433962264 │ 318 │ 14552 │
│ 2024-03-29 │ Answer │ 1.4706927175843694 │ 563 │ 0 │
│ 2024-03-28 │ Answer │ 1.601637107776262 │ 733 │ 0 │
│ 2024-03-28 │ Question │ 1.3530864197530865 │ 405 │ 24564 │
│ 2024-03-27 │ Question │ 1.3225806451612903 │ 434 │ 21346 │
│ 2024-03-27 │ Answer │ 1.4907539118065434 │ 703 │ 0 │
└────────────┴──────────┴────────────────────┴──────────────┴────────────┘
10 rows in set. Elapsed: 0.013 sec. Processed 11.45 thousand rows, 663.87 KB (866.53 thousand rows/s., 50.26 MB/s.)
Peak memory usage: 989.53 KiB.
ClickHouse において、CTE はインライン展開されます。つまり、最適化の過程でクエリ内に実質的にコピーペーストされるだけで、マテリアライズ されません。これは次のことを意味します。
- CTE がソーステーブル(すなわち、その materialized view が紐付いているテーブル)とは別のテーブルを参照しており、かつ
JOIN や IN 句で使用されている場合、それはトリガーではなく、サブクエリまたは JOIN のように動作します。
- materialized view は依然としてメインのソーステーブルへの INSERT のみをトリガーとしますが、CTE は INSERT ごとに再実行されます。参照しているテーブルが大きい場合、これは不要なオーバーヘッドを引き起こす可能性があります。
例えば、
WITH recent_users AS (
SELECT Id FROM stackoverflow.users WHERE CreationDate > now() - INTERVAL 7 DAY
)
SELECT * FROM stackoverflow.posts WHERE OwnerUserId IN (SELECT Id FROM recent_users)
この場合、users CTE は posts への挿入ごとに再評価され、users に新しい行が挿入されても materialized view は更新されず、posts に行が挿入されたときにのみ更新されます。
一般的には、materialized view が紐づいている同じソーステーブルに対して処理を行うロジックに CTE を使用するか、参照されるテーブルが小さく、パフォーマンスのボトルネックになりにくいことを確認してください。あるいは、Materialized Views での JOIN と同様の最適化を検討してください。