S3 から ClickHouse にデータを挿入できるほか、S3 をエクスポート先としても利用できるため、「データレイク」アーキテクチャとの連携が可能になります。さらに、S3 は「コールド」ストレージ階層を提供し、ストレージとコンピュートの分離にも役立ちます。以下のセクションでは、New York City taxi データセットを用いて、S3 と ClickHouse 間でデータを移動する手順を示すとともに、主要な構成パラメータを明らかにし、パフォーマンスを最適化するためのヒントを紹介します。
S3 テーブル関数
s3 テーブル関数を使用すると、S3 互換ストレージからおよび S3 互換ストレージへファイルの読み取りと書き込みができます。構文の概要は次のとおりです。
s3(path, [aws_access_key_id, aws_secret_access_key,] [format, [structure, [compression]]])
where:
- path — ファイルへのパスを含むバケットの URL。読み取り専用モードで次のワイルドカードをサポートします:
*, ?, {abc,def}, {N..M}。ここで、N, M は数値、'abc', 'def' は文字列です。詳細は、パスでのワイルドカードの使用に関するドキュメントを参照してください。
- format — ファイルのフォーマット。
- structure — テーブルの構造。書式は
'column1_name column1_type, column2_name column2_type, ...' です。
- compression — 省略可能なパラメータ。サポートされている値:
none, gzip/gz, brotli/br, xz/LZMA, zstd/zst。デフォルトでは、ファイル拡張子から圧縮形式を自動検出します。
パス式でワイルドカードを使用すると、複数のファイルを参照できるようになり、並列処理による読み取りが可能になります。
ClickHouse にテーブルを作成する前に、S3 バケット内のデータを詳しく確認しておくとよいでしょう。これは、ClickHouse から DESCRIBE ステートメントを使用して直接確認できます。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
DESCRIBE TABLEステートメントの出力から、S3バケット内にあるこのデータについて、ClickHouseがどのように自動的に型推論を行うかを確認できます。gzip圧縮形式も自動的に認識して解凍している点に注目してください。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') SETTINGS describe_compact_output=1
┌─name──────────────────┬─type───────────────┐
│ trip_id │ Nullable(Int64) │
│ vendor_id │ Nullable(Int64) │
│ pickup_date │ Nullable(Date) │
│ pickup_datetime │ Nullable(DateTime) │
│ dropoff_date │ Nullable(Date) │
│ dropoff_datetime │ Nullable(DateTime) │
│ store_and_fwd_flag │ Nullable(Int64) │
│ rate_code_id │ Nullable(Int64) │
│ pickup_longitude │ Nullable(Float64) │
│ pickup_latitude │ Nullable(Float64) │
│ dropoff_longitude │ Nullable(Float64) │
│ dropoff_latitude │ Nullable(Float64) │
│ passenger_count │ Nullable(Int64) │
│ trip_distance │ Nullable(String) │
│ fare_amount │ Nullable(String) │
│ extra │ Nullable(String) │
│ mta_tax │ Nullable(String) │
│ tip_amount │ Nullable(String) │
│ tolls_amount │ Nullable(Float64) │
│ ehail_fee │ Nullable(Int64) │
│ improvement_surcharge │ Nullable(String) │
│ total_amount │ Nullable(String) │
│ payment_type │ Nullable(String) │
│ trip_type │ Nullable(Int64) │
│ pickup │ Nullable(String) │
│ dropoff │ Nullable(String) │
│ cab_type │ Nullable(String) │
│ pickup_nyct2010_gid │ Nullable(Int64) │
│ pickup_ctlabel │ Nullable(Float64) │
│ pickup_borocode │ Nullable(Int64) │
│ pickup_ct2010 │ Nullable(String) │
│ pickup_boroct2010 │ Nullable(String) │
│ pickup_cdeligibil │ Nullable(String) │
│ pickup_ntacode │ Nullable(String) │
│ pickup_ntaname │ Nullable(String) │
│ pickup_puma │ Nullable(Int64) │
│ dropoff_nyct2010_gid │ Nullable(Int64) │
│ dropoff_ctlabel │ Nullable(Float64) │
│ dropoff_borocode │ Nullable(Int64) │
│ dropoff_ct2010 │ Nullable(String) │
│ dropoff_boroct2010 │ Nullable(String) │
│ dropoff_cdeligibil │ Nullable(String) │
│ dropoff_ntacode │ Nullable(String) │
│ dropoff_ntaname │ Nullable(String) │
│ dropoff_puma │ Nullable(Int64) │
└───────────────────────┴────────────────────┘
S3ベースのデータセットを操作するために、標準的なMergeTreeテーブルを宛先として準備します。以下のステートメントは、デフォルトデータベースにtripsという名前のテーブルを作成します。上記で推論されたデータ型の一部を変更しており、特にNullable()データ型修飾子は使用しないようにしています。これは、不要な追加ストレージと若干のパフォーマンスオーバーヘッドを引き起こす可能性があるためです。
CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
pickup_date フィールドに対するパーティショニングの利用に注目してください。通常、パーティションキーはデータ管理のために使用されますが、後ほどこのキーを使って S3 への書き込みを並列化します。
タクシーデータセットの各エントリは、1 件のタクシー乗車を表しています。この匿名化されたデータは、S3 バケット https://datasets-documentation.s3.eu-west-3.amazonaws.com/ の nyc-taxi フォルダ内に格納された、圧縮済みの 2,000 万件のレコードで構成されています。データは TSV 形式で、ファイルあたりおよそ 100 万行が含まれています。
S3 からのデータ読み取り
ClickHouse に永続化することなく、S3 データをソースとしてクエリを実行できます。次のクエリでは、10 行をサンプリングします。バケットがパブリックアクセス可能であるため、ここでは認証情報が不要である点に注意してください。
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 10;
TabSeparatedWithNames 形式では、最初の行にカラム名がエンコードされているため、カラムを列挙する必要はない点に注意してください。CSV や TSV などの他のフォーマットでは、このクエリに対して c1、c2、c3 などの自動生成されたカラムが返されます。
さらに、クエリでは、バケット内のパスおよびファイル名に関する情報をそれぞれ提供する _path や _file のような 仮想カラム もサポートされています。例えば次のとおりです。
SELECT _path, _file, trip_id
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_0.gz', 'TabSeparatedWithNames')
LIMIT 5;
┌─_path──────────────────────────────────────┬─_file──────┬────trip_id─┐
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999902 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999919 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999944 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999969 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999990 │
└────────────────────────────────────────────┴────────────┴────────────┘
このサンプルデータセットの行数を確認します。ファイル展開のためにワイルドカードを使用しているため、20 個すべてのファイルが対象になります。ClickHouse インスタンスのコア数にもよりますが、このクエリの実行にはおよそ 10 秒かかります。
SELECT count() AS count
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
┌────count─┐
│ 20000000 │
└──────────┘
S3 から直接データを読み取ることは、データのサンプリングやアドホックな探索的クエリを実行するには有用ですが、日常的に行うべきものではありません。本格的に運用する段階になったら、ClickHouse の MergeTree テーブルにデータをインポートしてください。
clickhouse-local の使用
clickhouse-local プログラムを使用すると、ClickHouse サーバーをデプロイしたり設定したりすることなく、ローカルファイルに対して高速な処理を実行できます。s3 テーブル関数を用いたクエリは、すべてこのユーティリティで実行できます。例えば、次のように実行できます。
clickhouse-local --query "SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
S3 からのデータ挿入
ClickHouse の機能を最大限に活用するために、次にデータを読み取り、インスタンスに挿入します。
これを行うために、s3 関数とシンプルな INSERT 文を組み合わせます。ターゲットテーブル側で必要な構造が定義されているため、列を列挙する必要はない点に注意してください。この場合、テーブルの DDL 文で指定された順序で列が並んでいる必要があります。列は SELECT 句内での位置に基づいてマッピングされます。1,000 万行すべてを挿入する処理には、ClickHouse インスタンスによっては数分かかる場合があります。以下では、すばやく結果を得るために 100 万行のみを挿入しています。必要に応じて、LIMIT 句や列の選択を調整して、一部だけをインポートしてください。
INSERT INTO trips
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 1000000;
ClickHouse Local を使用したリモート挿入
ネットワークセキュリティポリシーによって ClickHouse クラスターからの外向き接続が禁止されている場合、clickhouse-local を使用して S3 データを挿入することもできます。以下の例では、S3 バケットから読み取り、remote 関数を使用して ClickHouse に挿入します。
clickhouse-local --query "INSERT INTO TABLE FUNCTION remote('localhost:9000', 'default.trips', 'username', 'password') (*) SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
注記
この操作を安全な SSL 接続で実行するには、remoteSecure 関数を使用してください。
データのエクスポート
s3 テーブル関数を使用して S3 上のファイルに書き込むことができます。これには適切な権限が必要です。必要な認証情報はリクエスト内で渡しますが、その他のオプションについては Managing Credentials ページを参照してください。
以下のシンプルな例では、テーブル関数をソースではなく出力先として使用しています。ここでは、trips テーブルから 10,000 行を、lz4 圧縮と出力形式としての CSV を指定して、S3 バケットにストリーミングしています。
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
SELECT *
FROM trips
LIMIT 10000;
ここでは、ファイルの形式が拡張子から自動的に判別されることに注目してください。また、s3 関数に対してカラムを明示的に指定する必要もありません。これは SELECT 文から自動的に推論されます。
大きなファイルの分割
データを 1 つのファイルとしてエクスポートしたい場面はあまりないでしょう。ClickHouse を含むほとんどのツールは、並列処理が可能になるため、複数ファイルへの読み書きを行うことでスループットが向上します。INSERT コマンドを複数回実行し、データの一部を対象にすることもできます。ClickHouse には、PARTITION キーを使用してファイルを自動的に分割する方法が用意されています。
次の例では、rand() 関数の剰余を用いて 10 個のファイルを作成します。生成されたパーティション ID がファイル名でどのように参照されているかに注目してください。これにより、trips_0.csv.lz4、trips_1.csv.lz4 などのように、数値のサフィックスを持つ 10 個のファイルが生成されます。
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY rand() % 10
SELECT *
FROM trips
LIMIT 100000;
別の方法として、データ内のフィールドを参照することもできます。このデータセットでは、payment_type はカーディナリティが 5 の自然なパーティションキーになります。
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY payment_type
SELECT *
FROM trips
LIMIT 100000;
クラスターの活用
上記の関数はすべて、単一ノード上での実行に限定されています。読み取り速度は、他のリソース(通常はネットワーク)が飽和するまで CPU コア数に比例して向上し、ユーザーは垂直スケールが可能です。しかし、このアプローチには制約があります。INSERT INTO SELECT クエリを実行する際に分散テーブルに挿入することで、ある程度リソースの負荷を軽減できますが、それでも単一ノードでデータの読み取り、パース、処理を行う点は変わりません。この課題に対処し、読み取りを水平方向にスケールさせるために用意されているのが、s3Cluster 関数です。
クエリを受け取るノードはイニシエーターと呼ばれ、クラスター内のすべてのノードに接続を確立します。どのファイルを読み取る必要があるかを決定するグロブパターンは、読み取り対象となるファイルの集合へと展開されます。イニシエーターは、クラスター内のノード(ワーカーとして動作)にファイルを分配します。これらのワーカーは、読み取りを完了するごとに、処理するファイルを要求します。このプロセスにより、読み取りを水平方向にスケールさせることができます。
s3Cluster 関数は、対象となるクラスターをワーカーノードとして指定する必要がある点を除き、単一ノード版と同じ形式を取ります。
s3Cluster(cluster_name, source, [access_key_id, secret_access_key,] format, structure)
cluster_name — リモートおよびローカルサーバーへのアドレスと接続パラメータの集合を構成するために使用されるクラスタ名。source — 単一または複数ファイルへの URL。読み取り専用モードで次のワイルドカードをサポートします: *, ?, {'abc','def'} および {N..M}。ここで N, M は数値、abc, def は文字列です。詳細は Wildcards In Path を参照してください。access_key_id と secret_access_key — 指定されたエンドポイントで使用する認証情報を表すキー。省略可能です。format — ファイルの format。structure — テーブルの構造。フォーマットは 'column1_name column1_type, column2_name column2_type, ...' です。
任意の s3 関数と同様に、バケットが保護されていない場合や、IAM ロールなどの環境経由で認証・権限付与を行っている場合は、認証情報は省略可能です。ただし s3 関数とは異なり、22.3.1 時点ではリクエスト内で structure を指定する必要があり、スキーマは自動推論されません。
この関数は、ほとんどのケースで INSERT INTO SELECT の一部として使用されます。この場合、多くは分散テーブルに対して INSERT を行います。以下では、trips_all が分散テーブルである単純な例を示します。このテーブルは events クラスタを使用していますが、読み取りおよび書き込みに使用されるノードの一貫性は必須要件ではありません。
INSERT INTO default.trips_all
SELECT *
FROM s3Cluster(
'events',
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz',
'TabSeparatedWithNames'
)
INSERT 文による書き込みはイニシエーターノードに対して実行されます。これは、各ノードで読み取りが行われる一方で、生成された行は分散処理のためにイニシエーターにルーティングされることを意味します。高スループットなシナリオでは、これがボトルネックとなる可能性があります。これに対処するには、s3cluster 関数に対してパラメータ parallel_distributed_insert_select を設定してください。
S3 テーブルエンジン
s3 関数を使用すると、S3 に保存されたデータに対してアドホッククエリを実行できますが、構文が冗長になりがちです。この問題を解決するために用意されているのが、バケットの URL や認証情報を何度も指定する必要がなくなる S3 テーブルエンジンです。
CREATE TABLE s3_engine_table (name String, value UInt32)
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, [compression])
[SETTINGS ...]
path — ファイルへのパスを含むバケットの URL。読み取り専用モードでは、次のワイルドカードをサポートします: *、?、{abc,def}、{N..M}。ここで N、M は数値、'abc'、'def' は文字列です。詳細はこちらを参照してください。format — ファイルのフォーマット。aws_access_key_id, aws_secret_access_key - AWS アカウントユーザー用の長期認証情報。リクエストの認証に使用できます。このパラメータは省略可能です。認証情報が指定されていない場合は、設定ファイルの値が使用されます。詳細は認証情報の管理を参照してください。compression — 圧縮形式。サポートされる値: none, gzip/gz, brotli/br, xz/LZMA, zstd/zst。パラメータは省略可能です。デフォルトでは、ファイル拡張子に基づいて圧縮方式を自動検出します。
データの読み取り
次の例では、https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/ バケット内の最初の 10 個の TSV ファイルを使用して、trips_raw という名前のテーブルを作成します。これらの各ファイルには、それぞれ 100 万行のデータが含まれています。
CREATE TABLE trips_raw
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type_` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` FixedString(7),
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` FixedString(7),
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
) ENGINE = S3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..9}.gz', 'TabSeparatedWithNames', 'gzip');
最初の10個のファイルに限定するために {0..9} パターンを使用している点に注意してください。作成したら、このテーブルには他のテーブルと同様にクエリを実行できます。
SELECT DISTINCT(pickup_ntaname)
FROM trips_raw
LIMIT 10;
┌─pickup_ntaname───────────────────────────────────┐
│ Lenox Hill-Roosevelt Island │
│ Airport │
│ SoHo-TriBeCa-Civic Center-Little Italy │
│ West Village │
│ Chinatown │
│ Hudson Yards-Chelsea-Flatiron-Union Square │
│ Turtle Bay-East Midtown │
│ Upper West Side │
│ Murray Hill-Kips Bay │
│ DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill │
└──────────────────────────────────────────────────┘
データの挿入
S3 テーブルエンジンは並列読み出しをサポートします。テーブル定義にグロブパターンが含まれていないテーブルに対してのみ書き込みをサポートします。したがって、上記のテーブルでは書き込みはできません。
書き込みの例として、書き込み可能な S3 バケットを指すテーブルを作成します。
CREATE TABLE trips_dest
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`tip_amount` Float32,
`total_amount` Float32
) ENGINE = S3('<bucket path>/trips.bin', 'Native');
INSERT INTO trips_dest
SELECT
trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
tip_amount,
total_amount
FROM trips
LIMIT 10;
SELECT * FROM trips_dest LIMIT 5;
┌────trip_id─┬─pickup_date─┬─────pickup_datetime─┬────dropoff_datetime─┬─tip_amount─┬─total_amount─┐
│ 1200018648 │ 2015-07-01 │ 2015-07-01 00:00:16 │ 2015-07-01 00:02:57 │ 0 │ 7.3 │
│ 1201452450 │ 2015-07-01 │ 2015-07-01 00:00:20 │ 2015-07-01 00:11:07 │ 1.96 │ 11.76 │
│ 1202368372 │ 2015-07-01 │ 2015-07-01 00:00:40 │ 2015-07-01 00:05:46 │ 0 │ 7.3 │
│ 1200831168 │ 2015-07-01 │ 2015-07-01 00:01:06 │ 2015-07-01 00:09:23 │ 2 │ 12.3 │
│ 1201362116 │ 2015-07-01 │ 2015-07-01 00:01:07 │ 2015-07-01 00:03:31 │ 0 │ 5.3 │
└────────────┴─────────────┴─────────────────────┴─────────────────────┴────────────┴──────────────┘
行は新しいファイルにしか挿入できないことに注意してください。マージサイクルやファイル分割処理はありません。いったんファイルに書き込まれると、その後の挿入は失敗します。ユーザーには次の 2 つの選択肢があります。
- 設定
s3_create_new_file_on_insert=1 を指定します。これにより、挿入ごとに新しいファイルが作成されます。各ファイルの末尾には数値のサフィックスが付加され、挿入操作ごとに単調増加します。上記の例では、後続の挿入を行うと trips_1.bin ファイルが作成されます。
- 設定
s3_truncate_on_insert=1 を指定します。これによりファイルが切り詰められ、完了時には新たに挿入された行のみを含むようになります。
これら 2 つの設定のデフォルト値はいずれも 0 であるため、どちらか一方をユーザーが設定する必要があります。両方が設定されている場合は s3_truncate_on_insert が優先されます。
S3 テーブルエンジンについての注意点:
- 従来の
MergeTree ファミリのテーブルとは異なり、S3 テーブルを DROP しても、基盤となるデータは削除されません。
- このテーブルタイプの完全な設定一覧は、こちらにあります。
- このエンジンを使用する際は、次の点に注意してください:
- ALTER クエリはサポートされません。
- SAMPLE 操作はサポートされません。
- 主キーやスキップインデックスといったインデックスの概念はありません。
認証情報の管理
前の例では、s3 関数または S3 テーブル定義の中で認証情報を渡してきました。これは単発の利用であれば許容できる場合もありますが、本番環境では、ユーザーは認証情報を明示的に記述しなくてもよい認証メカニズムを必要とします。これに対応するため、ClickHouse にはいくつかの選択肢があります。
-
接続情報を config.xml または conf.d 配下の同等の設定ファイルに指定します。以下に、Debian パッケージを用いてインストールしたことを前提とした例ファイルの内容を示します。
ubuntu@single-node-clickhouse:/etc/clickhouse-server/config.d$ cat s3.xml
<clickhouse>
<s3>
<endpoint-name>
<endpoint>https://dalem-files.s3.amazonaws.com/test/</endpoint>
<access_key_id>key</access_key_id>
<secret_access_key>secret</secret_access_key>
<!-- <use_environment_credentials>false</use_environment_credentials> -->
<!-- <header>Authorization: Bearer SOME-TOKEN</header> -->
</endpoint-name>
</s3>
</clickhouse>
これらの認証情報は、上記のエンドポイントが要求された URL の先頭部分と完全に一致するリクエストに対して使用されます。また、この例ではアクセスキーおよびシークレットキーの代わりに、認可ヘッダーを指定できることにも注目してください。サポートされている設定の完全な一覧はこちらにあります。
-
上の例では、設定パラメータ use_environment_credentials を利用できることを示しています。この設定パラメータは、s3 レベルでグローバルに設定することもできます。
<clickhouse>
<s3>
<use_environment_credentials>true</use_environment_credentials>
</s3>
</clickhouse>
この設定を有効にすると、環境から S3 の認証情報を取得しようと試みるようになり、IAM ロールを通じてアクセスできるようになります。具体的には、次の順序で認証情報の取得が行われます。
- 環境変数
AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY および AWS_SESSION_TOKEN の参照
- $HOME/.aws の確認
- AWS Security Token Service 経由で取得した一時的な認証情報(
AssumeRole API 経由)
- ECS 環境変数
AWS_CONTAINER_CREDENTIALS_RELATIVE_URI または AWS_CONTAINER_CREDENTIALS_FULL_URI および AWS_ECS_CONTAINER_AUTHORIZATION_TOKEN に対する認証情報の確認
- AWS_EC2_METADATA_DISABLED が true に設定されていない場合に、Amazon EC2 インスタンスメタデータ 経由で認証情報を取得
- これらと同じ設定は、同じプレフィックスマッチング規則を用いて特定のエンドポイントに対しても設定できます。
S3 関数を使用した読み取りおよび挿入の最適化方法については、専用のパフォーマンスガイドを参照してください。
S3 ストレージのチューニング
内部的には、ClickHouse の MergeTree は 2 つの主要なストレージ形式(Wide と Compact)を使用します。現在の実装では、ClickHouse のデフォルトの動作(min_bytes_for_wide_part および min_rows_for_wide_part 設定によって制御)に準拠していますが、今後のリリースでは S3 向けに動作が変化すると予想されます。例えば、min_bytes_for_wide_part のデフォルト値を大きくすることで、より Compact な形式が推奨され、その結果としてファイル数が減少します。S3 ストレージのみを使用する場合は、これらの設定の調整を検討してください。
S3 バックエンドの MergeTree
s3 関数と関連するテーブルエンジンを使用すると、なじみのある ClickHouse の構文で S3 上のデータをクエリできます。ただし、データ管理機能およびパフォーマンスの観点からは制限があります。プライマリインデックスのサポートがなく、キャッシュ機構のサポートもありません。また、ファイルの挿入(書き込み)はユーザーが管理する必要があります。
ClickHouse は、特に「コールド」データに対するクエリ性能がそれほど重要ではなく、ストレージとコンピュートを分離したい場合に、S3 が魅力的なストレージソリューションであることを認識しています。これを実現するために、MergeTree エンジンのストレージとして S3 を使用するためのサポートが提供されています。これにより、S3 のスケーラビリティとコストメリット、および MergeTree エンジンの挿入とクエリのパフォーマンスを活用できるようになります。
ストレージ階層
ClickHouse のストレージボリューム機能により、物理ディスクを MergeTree テーブルエンジンから抽象化できます。単一のボリュームは、順序付けられたディスクの集合で構成できます。これは主に複数のブロックデバイスをデータストレージに利用できるようにするためのものですが、この抽象化により S3 を含む他のストレージタイプも利用可能になります。ClickHouse のデータパーツは、ストレージポリシーと使用率に従ってボリューム間を移動できるため、ストレージ階層という概念が生まれます。
ストレージ階層によりホット・コールド構成が可能になります。もっとも新しいデータは、通常もっとも頻繁にクエリされるため、高性能ストレージ (例: NVMe SSD) の比較的小さな容量のみを必要とします。データが古くなるにつれて、SLA で許容されるクエリ時間は長くなり、クエリ頻度も増加します。この裾野の広いロングテールのデータは、HDD のような低速で性能の低いストレージや、S3 のようなオブジェクトストレージに保存できます。
ディスクの作成
S3 バケットをディスクとして利用するには、まず ClickHouse の設定ファイル内で宣言する必要があります。config.xml を拡張するか、望ましくは conf.d 配下に新しいファイルを用意します。S3 ディスクの定義例を次に示します。
<clickhouse>
<storage_configuration>
...
<disks>
<s3>
<type>s3</type>
<endpoint>https://sample-bucket.s3.us-east-2.amazonaws.com/tables/</endpoint>
<access_key_id>your_access_key_id</access_key_id>
<secret_access_key>your_secret_access_key</secret_access_key>
<region></region>
<metadata_path>/var/lib/clickhouse/disks/s3/</metadata_path>
</s3>
<s3_cache>
<type>cache</type>
<disk>s3</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
...
</storage_configuration>
</clickhouse>
このディスク宣言に関連する設定の完全な一覧はこちらで参照できます。クレデンシャルは、Managing credentials で説明したのと同じ手法を用いてここでも管理できます。たとえば、上記の設定ブロックで use_environment_credentials を true に設定することで、IAM ロールを使用できます。
ストレージポリシーの作成
一度設定すると、この「ディスク」はポリシー内で宣言されたストレージボリュームで使用できます。以下の例では、S3 が唯一のストレージであると仮定します。これは、TTL や使用率に基づいてデータを再配置できる、より複雑なホット・コールド構成は考慮していません。
<clickhouse>
<storage_configuration>
<disks>
<s3>
...
</s3>
<s3_cache>
...
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
テーブルの作成
書き込み権限を持つバケットを使用するようにディスクを設定してあれば、以下の例のようなテーブルを作成できます。簡潔にするため、NYC タクシーのカラムの一部のみを使用し、データを S3 をバックエンドストレージとするテーブルに直接ストリーミングします。
CREATE TABLE trips_s3
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`tip_amount` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
SETTINGS storage_policy='s3_main'
INSERT INTO trips_s3 SELECT trip_id, pickup_date, pickup_datetime, dropoff_datetime, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, passenger_count, trip_distance, tip_amount, total_amount, payment_type FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
ハードウェアによっては、後者の 100 万行の INSERT の実行に数分かかる場合があります。進行状況は system.processes テーブルで確認できます。行数は最大 1,000 万行まで調整し、いくつかのサンプルクエリを試してみてください。
SELECT passenger_count, avg(tip_amount) AS avg_tip, avg(total_amount) AS avg_amount FROM trips_s3 GROUP BY passenger_count;
テーブルの変更
特定のテーブルのストレージポリシーを変更する必要が生じることがあります。これは可能ではありますが、いくつか制限があります。新しいターゲットポリシーには、以前のポリシーに含まれていたすべてのディスクおよびボリュームが含まれていなければなりません。つまり、ポリシー変更に対応するためにデータが移動されることはありません。これらの制約を検証する際、ボリュームとディスクは名前によって識別され、これに反する変更を行おうとするとエラーになります。ただし、前述の例を使用している場合、次の変更は許可されます。
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
<s3_tiered>
<volumes>
<hot>
<disk>default</disk>
</hot>
<main>
<disk>s3</disk>
</main>
</volumes>
<move_factor>0.2</move_factor>
</s3_tiered>
</policies>
ALTER TABLE trips_s3 MODIFY SETTING storage_policy='s3_tiered'
ここでは、新しい s3_tiered ポリシーで既存のメインボリュームを再利用し、新しいホットボリュームを導入します。このホットボリュームはデフォルトディスクを使用しており、このデフォルトディスクはパラメータ <path> で設定された 1 つのディスクのみで構成されています。ボリューム名とディスクが変わらない点に注意してください。テーブルへの新規挿入データは、move_factor * disk_size に到達するまではデフォルトディスク上に保持され、その時点でデータは S3 に移動されます。
レプリケーションの処理
S3 ディスクを使用したレプリケーションは、ReplicatedMergeTree テーブルエンジンで実現できます。詳細については、S3 Object Storage を使用して 2 つの AWS リージョン間で単一分片をレプリケートする ガイドを参照してください。
読み取りと書き込み
以下の注意事項では、ClickHouse による S3 との連携実装について説明します。主に情報提供を目的としていますが、パフォーマンス最適化 を行う際に役立つ場合があります。
- デフォルトでは、クエリ処理パイプラインの任意のステージで使用されるクエリ処理用スレッドの最大数は、コア数と同じになります。ステージによって並列化のしやすさが異なるため、この値が上限として機能します。ディスクからデータがストリーミングされるため、複数のクエリステージが同時に実行される場合があります。そのため、クエリで実際に使用されるスレッド数がこの値を超えることもあります。この動作は設定 max_threads で変更できます。
- S3 上での読み取りは、デフォルトでは非同期で行われます。この挙動は
remote_filesystem_read_method 設定によって決まり、デフォルト値は threadpool です。リクエストを処理する際、ClickHouse はストライプ単位でグラニュールを読み取ります。各ストライプには多くのカラムが含まれる可能性があります。1 本のスレッドが、そのグラニュールに対応するカラムを一つずつ読み取ります。これを同期的に行う代わりに、データを待つ前にすべてのカラムに対して先読み(prefetch)を行います。この方式により、各カラムを同期的に待機する場合と比べて大きな性能向上が得られます。多くのケースでは、この設定を変更する必要はありません。詳細は パフォーマンス最適化 を参照してください。
- 書き込みは並列で実行され、最大 100 本のファイル書き込みスレッドが同時に動作します。
max_insert_delayed_streams_for_parallel_write はデフォルト値 1000 で、並列に書き込まれる S3 の BLOB オブジェクトの数を制御します。書き込み中の各ファイルごとにバッファ(約 1MB)が必要になるため、これは実質的に INSERT のメモリ消費量の上限を制約します。サーバーのメモリが少ない環境では、この値を下げることが適切な場合があります。
S3 オブジェクトストレージを ClickHouse のディスクとして使用する
バケットと IAM ロールを作成するための詳細な手順が必要な場合は、「How to create an AWS IAM user and S3 bucket」を参照してください。
次の例は、デフォルトの ClickHouse ディレクトリを使用してサービスとしてインストールされた Linux の DEB パッケージを前提としています。
- ストレージ構成を保存するために、ClickHouse の
config.d ディレクトリに新しいファイルを作成します。
vim /etc/clickhouse-server/config.d/storage_config.xml
- ストレージ設定として以下を追加し、先ほどの手順で取得したバケットパス、アクセスキー、シークレットキーに置き換えてください。
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<endpoint>https://mars-doc-test.s3.amazonaws.com/clickhouse3/</endpoint>
<access_key_id>ABC123</access_key_id>
<secret_access_key>Abc+123</secret_access_key>
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
注記
<disks> タグ内の s3_disk および s3_cache は任意のラベルです。これらは別の名前に設定できますが、そのディスクを参照するために、同じラベルを <policies> タグ配下の <disk> タグでも使用する必要があります。
<S3_main> タグも任意であり、ClickHouse 内でリソースを作成する際に、ストレージターゲットを識別するために使用されるポリシー名です。
上記の設定は ClickHouse バージョン 22.8 以降向けです。以前のバージョンを使用している場合は、storing data ドキュメントを参照してください。
S3 の利用に関する詳細については、次を参照してください:
Integrations Guide: S3 Backed MergeTree
- ファイルの所有者を
clickhouse ユーザーおよびグループに変更します
chown clickhouse:clickhouse /etc/clickhouse-server/config.d/storage_config.xml
- 変更を有効にするために ClickHouse インスタンスを再起動します。
service clickhouse-server restart
テスト
- 次のようなコマンドを使用して ClickHouse クライアントにログインします
clickhouse-client --user default --password ClickHouse123!
- 新しい S3 ストレージポリシーを指定してテーブルを作成する
CREATE TABLE s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main';
- テーブルが正しいポリシーで作成されたことを確認します
SHOW CREATE TABLE s3_table1;
┌─statement────────────────────────────────────────────────────
│ CREATE TABLE default.s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main', index_granularity = 8192
└──────────────────────────────────────────────────────────────
- テーブルにテスト行を挿入する
INSERT INTO s3_table1
(id, column1)
VALUES
(1, 'abc'),
(2, 'xyz');
INSERT INTO s3_table1 (id, column1) FORMAT Values
Query id: 0265dd92-3890-4d56-9d12-71d4038b85d5
Ok.
2 rows in set. Elapsed: 0.337 sec.
- 行を表示する
┌─id─┬─column1─┐
│ 1 │ abc │
│ 2 │ xyz │
└────┴─────────┘
2 rows in set. Elapsed: 0.284 sec.
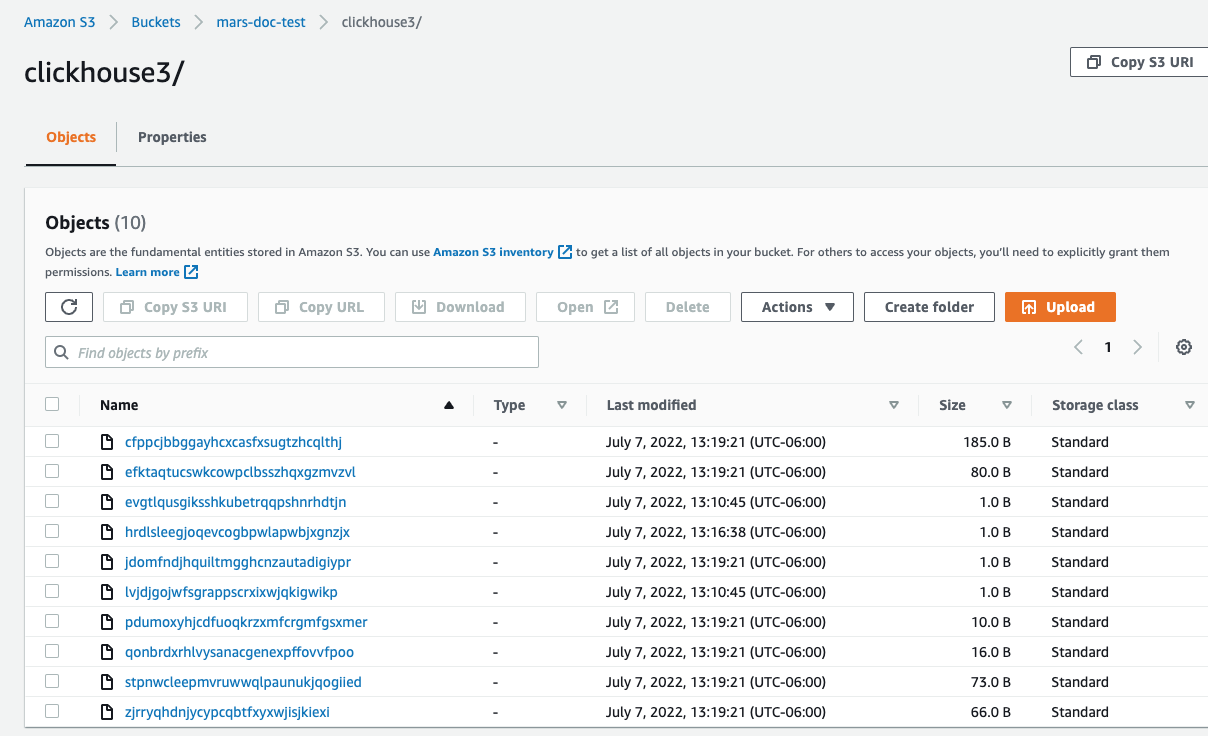
- AWS コンソールでバケット一覧に移動し、作成したバケットとフォルダーを選択します。
次のような画面が表示されるはずです。
S3 オブジェクトストレージを使用して単一シャードを 2 つの AWS リージョン間でレプリケートする
ヒント
ClickHouse Cloud では既定でオブジェクトストレージが使用されているため、ClickHouse Cloud 上で実行している場合はこの手順を実施する必要はありません。
デプロイを計画する
このチュートリアルは、AWS EC2 上に 2 つの ClickHouse サーバーノードと 3 つの ClickHouse Keeper ノードをデプロイすることを前提としています。ClickHouse サーバーのデータストアには S3 を使用します。ディザスタリカバリをサポートするために、2 つの AWS リージョンを使用し、それぞれのリージョンに 1 つずつ ClickHouse サーバーと S3 バケットを配置します。
ClickHouse テーブルは 2 台のサーバー間でレプリケートされるため、2 つのリージョン間でもレプリケートされます。
ソフトウェアをインストールする
ClickHouse サーバーノード
ClickHouse サーバーノードでデプロイ手順を実行する際は、インストール手順 を参照してください。
ClickHouse をデプロイする
2 つのホストに ClickHouse をデプロイします。サンプル構成では、これらは chnode1、chnode2 という名前になっています。
chnode1 を 1 つ目の AWS リージョンに、chnode2 を 2 つ目の AWS リージョンに配置します。
ClickHouse Keeper をデプロイする
3 つのホストに ClickHouse Keeper をデプロイします。サンプル構成では、これらは keepernode1、keepernode2、keepernode3 という名前になっています。keepernode1 は chnode1 と同じリージョンに、keepernode2 は chnode2 と同じリージョンに、keepernode3 はいずれかのリージョン内で、そのリージョンの ClickHouse ノードとは別のアベイラビリティーゾーンにデプロイします。
ClickHouse Keeper ノードでデプロイ手順を実行する際は、インストール手順 を参照してください。
S3 バケットを作成する
chnode1 と chnode2 を配置したそれぞれのリージョンに、S3 バケットを 1 つずつ、合計 2 つ作成します。
バケットと IAM ロールの作成についてステップごとの手順が必要な場合は、S3 バケットと IAM ロールの作成 を展開して、手順に従ってください。
S3バケットとIAMユーザーを作成
この記事では、AWS IAMユーザーの構成、S3バケットの作成、およびClickHouseがバケットをS3ディスクとして使用するための構成の基本を説明します。
使用する権限を決定するには、セキュリティチームと協力してください。これらを出発点として検討してください。
AWS IAMユーザーの作成
以下の手順では、サービスアカウントユーザー(ログインユーザーではなく)を作成します。
-
AWS IAM マネジメントコンソールにサインインします。
-
Users メニューから Create user を選択します
- ユーザー名を入力し、認証情報の種類を
Access key - Programmatic accessに設定し、Next: Permissionsを選択します。
- ユーザーをどのグループにも追加せずに、
Next: Tags を選択します
- タグを追加する必要がなければ、
Next: Review を選択します。
Create User を選択します
注記
ユーザーに権限がないという警告メッセージは無視できます。次のセクションでバケットに対するユーザーの権限が付与されます
- ユーザーの作成が完了したら、
show をクリックし、アクセスキーとシークレットキーをコピーします。
注記
キーを別の場所に保存してください。シークレットアクセスキーが利用可能なのはこの時だけです。
- 「閉じる」をクリックし、ユーザー画面で該当ユーザーを探します。
- ARN (Amazon Resource Name) をコピーし、バケットのアクセスポリシーを構成する際に使用できるよう保存しておきます。
S3バケットの作成
- S3 バケットセクションで
Create bucketを選択します
- バケット名を入力し、他のオプションはデフォルトのままにしておきます
注記
バケット名は組織内だけでなく、AWS全体で一意である必要があります。そうでない場合、エラーが発生します。
Block all Public Access は有効にしたままにしておきます。パブリックアクセスは不要です。
- ページ下部のバケットを作成を選択します
-
リンクを選択してARNをコピーし、バケットのアクセスポリシーを構成する際に使用できるよう保存しておきます。
-
バケットが作成されたら、S3バケット一覧から新しいS3バケットを見つけてそのリンクを選択します。
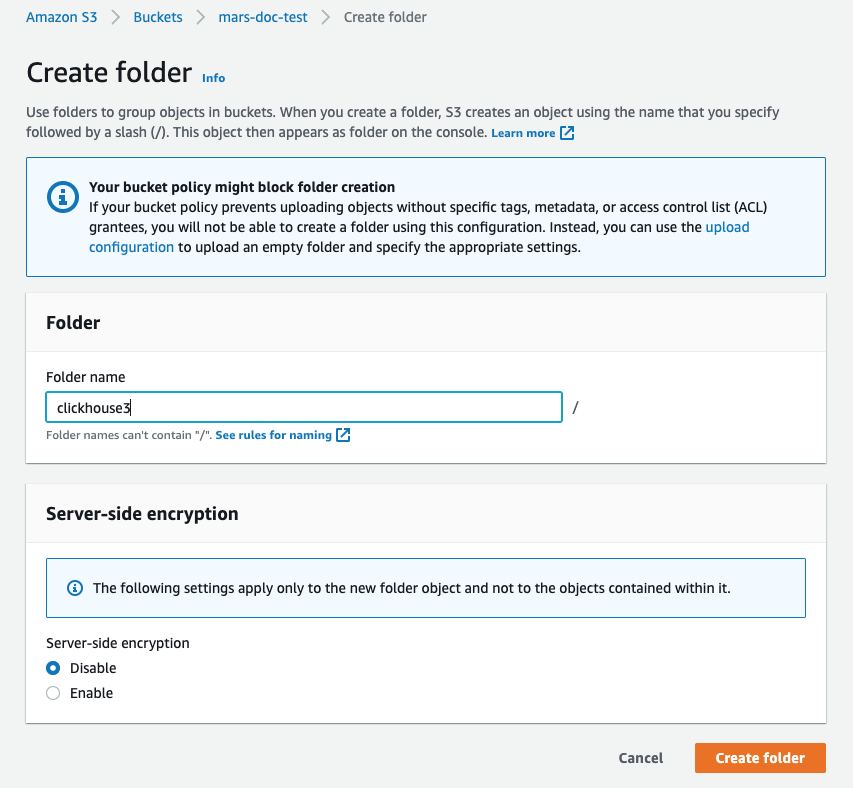
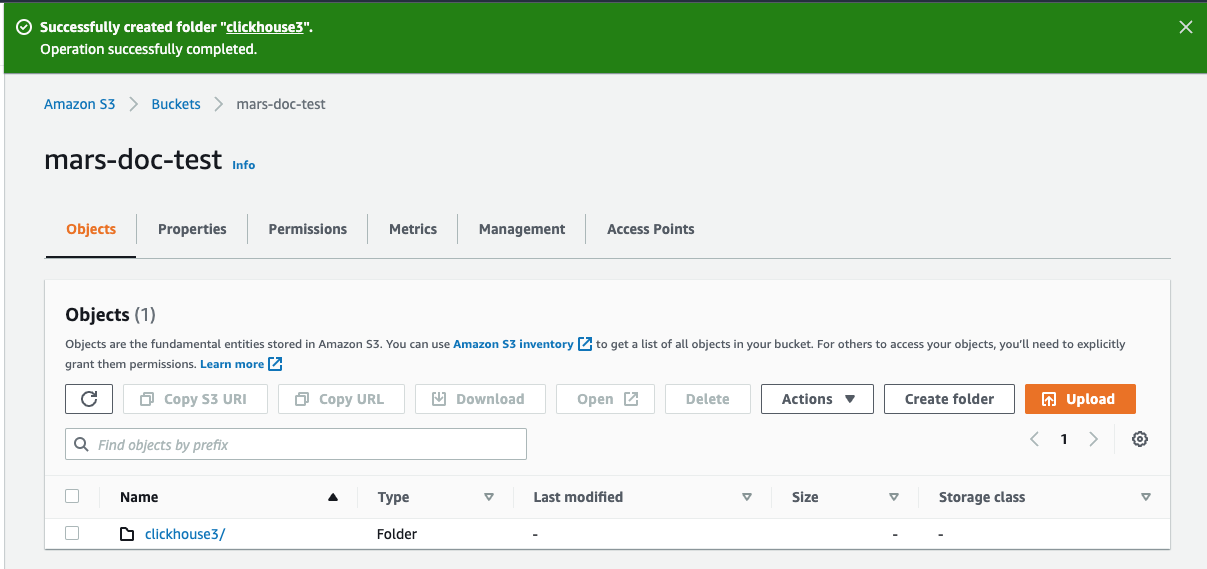
Create folder を選択します
- ClickHouse S3ディスクの対象となるフォルダ名を入力し、
Create folder を選択します
- フォルダがバケットリストに表示されているはずです
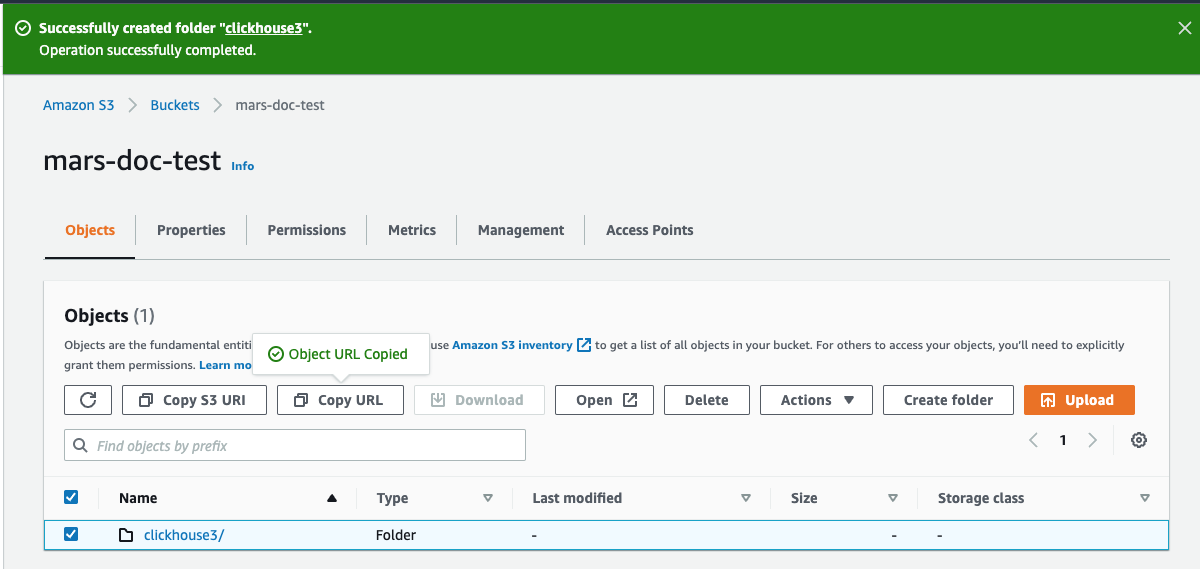
- 新しいフォルダのチェックボックスを選択し、
Copy URL をクリックします。コピーしたURLは、次のセクションで行うClickHouseストレージの設定で使用できるよう保存しておきます。
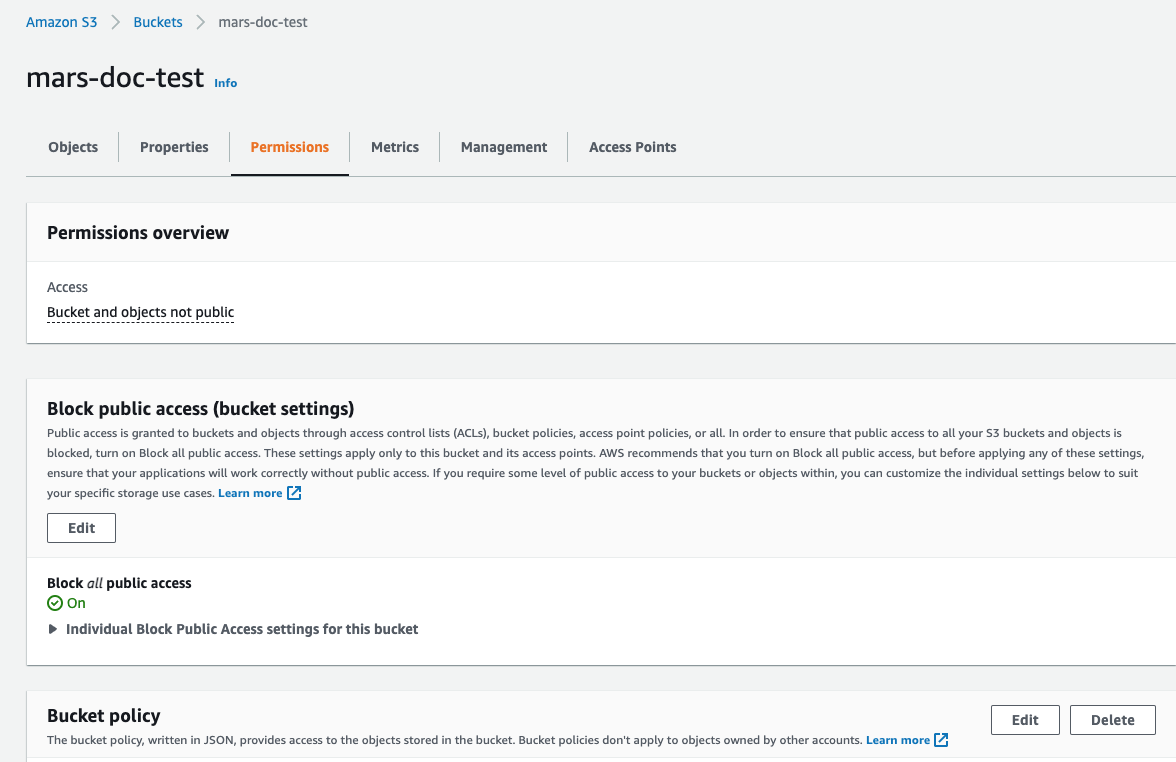
Permissions タブを選択し、Bucket Policy セクションの Edit ボタンをクリックします
- バケットポリシーを追加します。以下は例です。
{
"Version" : "2012-10-17",
"Id" : "Policy123456",
"Statement" : [
{
"Sid" : "abc123",
"Effect" : "Allow",
"Principal" : {
"AWS" : "arn:aws:iam::921234567898:user/mars-s3-user"
},
"Action" : "s3:*",
"Resource" : [
"arn:aws:s3:::mars-doc-test",
"arn:aws:s3:::mars-doc-test/*"
]
}
]
}
|Parameter | Description | Example Value |
|----------|-------------|----------------|
|Version | Version of the policy interpreter, leave as-is | 2012-10-17 |
|Sid | User-defined policy id | abc123 |
|Effect | Whether user requests will be allowed or denied | Allow |
|Principal | The accounts or user that will be allowed | arn:aws:iam::921234567898:user/mars-s3-user |
|Action | What operations are allowed on the bucket| s3:*|
|Resource | Which resources in the bucket will operations be allowed in | "arn:aws:s3:::mars-doc-test", "arn:aws:s3:::mars-doc-test/*" |
- ポリシー構成を保存します。
その後、設定ファイルは /etc/clickhouse-server/config.d/ に配置します。以下は 1 つのバケットに対するサンプル設定ファイルであり、もう一方も同様ですが、ハイライトされている 3 行のみが異なります。
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<!--highlight-start-->
<endpoint>https://docs-clickhouse-s3.s3.us-east-2.amazonaws.com/clickhouses3/</endpoint>
<access_key_id>ABCDEFGHIJKLMNOPQRST</access_key_id>
<secret_access_key>Tjdm4kf5snfkj303nfljnev79wkjn2l3knr81007</secret_access_key>
<!--highlight-end-->
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
注記
このガイドの多くの手順では、設定ファイルを /etc/clickhouse-server/config.d/ に配置するよう指示されます。これは、Linux システムにおける設定の上書き用ファイルのデフォルトの場所です。これらのファイルをこのディレクトリに配置すると、ClickHouse はその内容を使用してデフォルト設定を上書きします。これらのファイルをオーバーライド用ディレクトリに配置しておくことで、アップグレード時に設定が失われるのを防ぐことができます。
ClickHouse Keeper を(ClickHouse サーバーとは別に)スタンドアロンで実行する場合、設定は 1 つの XML ファイルになります。このチュートリアルでは、そのファイルは /etc/clickhouse-keeper/keeper_config.xml です。3 つの Keeper サーバーはいずれも同じ設定を使用しますが、1 つだけ異なる設定項目があります。それが <server_id> です。
server_id は、その設定ファイルを使用するホストに割り当てられる ID を示します。以下の例では、server_id は 3 であり、ファイル内のさらに下にある <raft_configuration> セクションを見ると、サーバー 3 のホスト名が keepernode3 となっていることがわかります。ClickHouse Keeper プロセスは、この情報を基に、リーダーの選出やその他の処理全般を行う際に、どのサーバーへ接続すべきかを認識します。
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<!--highlight-next-line-->
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>warning</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>keepernode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>keepernode2</hostname>
<port>9234</port>
</server>
<!--highlight-start-->
<server>
<id>3</id>
<hostname>keepernode3</hostname>
<port>9234</port>
</server>
<!--highlight-end-->
</raft_configuration>
</keeper_server>
</clickhouse>
ClickHouse Keeper の設定ファイルを所定の場所にコピーします(<server_id> を必ず設定してください):
sudo -u clickhouse \
cp keeper.xml /etc/clickhouse-keeper/keeper.xml
クラスターの定義
ClickHouse のクラスターは設定の <remote_servers> セクション内で定義します。この例では cluster_1S_2R という 1 つのクラスターが定義されており、単一の分片と 2 つのレプリカで構成されています。レプリカはそれぞれ chnode1 と chnode2 のホスト上に配置されています。
<clickhouse>
<remote_servers replace="true">
<cluster_1S_2R>
<shard>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_1S_2R>
</remote_servers>
</clickhouse>
クラスターを扱う場合、クラスター、シャード、レプリカの設定を DDL クエリに埋め込むマクロを定義しておくと便利です。このサンプルでは、shard と replica を個別に指定しなくても、レプリケーション対応テーブルエンジンを利用できるようにしています。テーブルを作成したら、system.tables をクエリすることで、shard と replica のマクロがどのように展開されているかを確認できます。
<clickhouse>
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<macros>
<cluster>cluster_1S_2R</cluster>
<shard>1</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
注記
上記のマクロは chnode1 向けです。chnode2 では replica を replica_2 に設定してください。
ゼロコピー レプリケーションを無効化する
ClickHouse バージョン 22.7 以前では、allow_remote_fs_zero_copy_replication 設定は S3 および HDFS ディスクに対してデフォルトで true に設定されています。このディザスタリカバリのシナリオでは、この設定を false にする必要があり、バージョン 22.8 以降ではデフォルトで false に設定されています。
この設定は次の 2 つの理由から false にする必要があります。1) この機能はまだ本番環境での利用に十分な成熟度に達していないこと、2) ディザスタリカバリシナリオでは、データとメタデータの両方を複数のリージョンに保存する必要があることです。allow_remote_fs_zero_copy_replication を false に設定してください。
<clickhouse>
<merge_tree>
<allow_remote_fs_zero_copy_replication>false</allow_remote_fs_zero_copy_replication>
</merge_tree>
</clickhouse>
ClickHouse Keeper は、ClickHouse ノード間でのデータレプリケーションを調整する役割を担います。ClickHouse に ClickHouse Keeper ノードを認識させるには、各 ClickHouse ノードに設定ファイルを追加します。
<clickhouse>
<zookeeper>
<node index="1">
<host>keepernode1</host>
<port>9181</port>
</node>
<node index="2">
<host>keepernode2</host>
<port>9181</port>
</node>
<node index="3">
<host>keepernode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
サーバー同士、また利用者がサーバーと通信できるようにするために、AWS のセキュリティ設定を行う際は、ネットワークポートの一覧を参照してください。
3 台すべてのサーバーが、サーバー間および S3 との通信を行えるように、ネットワーク接続を待ち受けるよう構成する必要があります。デフォルトでは ClickHouse はループバックアドレスでのみ待ち受けるため、これを変更する必要があります。これは /etc/clickhouse-server/config.d/ で設定します。以下は、ClickHouse および ClickHouse Keeper がすべての IPv4 インターフェイスで待ち受けるように構成するサンプルです。詳細については、ドキュメントまたはデフォルトの設定ファイル /etc/clickhouse/config.xml を参照してください。
<clickhouse>
<listen_host>0.0.0.0</listen_host>
</clickhouse>
サーバーを起動する
ClickHouse Keeper を起動する
各 Keeper サーバーで、使用しているオペレーティングシステムに応じたコマンドを実行します。例えば:
sudo systemctl enable clickhouse-keeper
sudo systemctl start clickhouse-keeper
sudo systemctl status clickhouse-keeper
ClickHouse Keeper のステータスを確認する
netcat を使用して ClickHouse Keeper にコマンドを送信します。たとえば mntr は、ClickHouse Keeper クラスタの状態を返します。このコマンドを各 Keeper ノードで実行すると、1 つがリーダーで、残り 2 つがフォロワーであることがわかります。
echo mntr | nc localhost 9181
zk_version v22.7.2.15-stable-f843089624e8dd3ff7927b8a125cf3a7a769c069
zk_avg_latency 0
zk_max_latency 11
zk_min_latency 0
zk_packets_received 1783
zk_packets_sent 1783
# highlight-start
zk_num_alive_connections 2
zk_outstanding_requests 0
zk_server_state leader
# highlight-end
zk_znode_count 135
zk_watch_count 8
zk_ephemerals_count 3
zk_approximate_data_size 42533
zk_key_arena_size 28672
zk_latest_snapshot_size 0
zk_open_file_descriptor_count 182
zk_max_file_descriptor_count 18446744073709551615
# highlight-start
zk_followers 2
zk_synced_followers 2
# highlight-end
ClickHouse サーバーを起動する
各 ClickHouse サーバーで次を実行します。
sudo service clickhouse-server start
ClickHouse サーバーを検証する
クラスタ設定を追加したとき、2 つの ClickHouse ノード間でレプリケートされる 1 つのシャードが定義されました。この検証ステップでは、ClickHouse の起動時にクラスタが構築されていることを確認し、そのクラスタを使用してレプリケートされたテーブルを作成します。
-
クラスタが存在することを確認します:
┌─cluster───────┐
│ cluster_1S_2R │
└───────────────┘
1 row in set. Elapsed: 0.009 sec. `
-
ReplicatedMergeTree テーブルエンジンを使用してクラスタ内にテーブルを作成します:
create table trips on cluster 'cluster_1S_2R' (
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`tip_amount` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4))
ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
SETTINGS storage_policy='s3_main'
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode1 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode2 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
-
先ほど定義したマクロの使われ方を確認する
マクロ shard と replica は前に定義しました。下のハイライトされた行では、各 ClickHouse ノードでそれぞれの値がどのように置き換えられているかを確認できます。さらに uuid という値も使用されています。uuid はシステムによって生成されるため、マクロ内では定義されていません。
SELECT create_table_query
FROM system.tables
WHERE name = 'trips'
FORMAT Vertical
Query id: 4d326b66-0402-4c14-9c2f-212bedd282c0
Row 1:
──────
create_table_query: CREATE TABLE default.trips (`trip_id` UInt32, `pickup_date` Date, `pickup_datetime` DateTime, `dropoff_datetime` DateTime, `pickup_longitude` Float64, `pickup_latitude` Float64, `dropoff_longitude` Float64, `dropoff_latitude` Float64, `passenger_count` UInt8, `trip_distance` Float64, `tip_amount` Float32, `total_amount` Float32, `payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4))
# highlight-next-line
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
PARTITION BY toYYYYMM(pickup_date) ORDER BY pickup_datetime SETTINGS storage_policy = 's3_main'
1 row in set. Elapsed: 0.012 sec.
注記
上記に示した ZooKeeper パス 'clickhouse/tables/{uuid}/{shard} は、default_replica_path および default_replica_name を設定することでカスタマイズできます。ドキュメントはこちらにあります。
テスト
以下のテストでは、データが2つのサーバー間でレプリケーションされていること、およびローカルディスクではなくS3バケットに保存されていることを検証します。
- New York Cityタクシーデータセットからデータを追加します:
INSERT INTO trips
SELECT trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
tip_amount,
total_amount,
payment_type
FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
-
データが S3 に保存されていることを確認します。
このクエリは、ディスク上のデータサイズと、どのディスクが使用されるかを決定するために使用されているストレージポリシーを表示します。
SELECT
engine,
data_paths,
metadata_path,
storage_policy,
formatReadableSize(total_bytes)
FROM system.tables
WHERE name = 'trips'
FORMAT Vertical
Query id: af7a3d1b-7730-49e0-9314-cc51c4cf053c
Row 1:
──────
engine: ReplicatedMergeTree
data_paths: ['/var/lib/clickhouse/disks/s3_disk/store/551/551a859d-ec2d-4512-9554-3a4e60782853/']
metadata_path: /var/lib/clickhouse/store/e18/e18d3538-4c43-43d9-b083-4d8e0f390cf7/trips.sql
storage_policy: s3_main
formatReadableSize(total_bytes): 36.42 MiB
1 row in set. Elapsed: 0.009 sec.
ローカルディスク上のデータサイズを確認します。上の結果から、保存されている数百万行のディスク上のサイズは 36.42 MiB です。これはローカルディスクではなく S3 上にあるはずです。上記のクエリからは、ローカルディスク上のデータとメタデータの保存場所も分かります。ローカル側のデータを確認します:
root@chnode1:~# du -sh /var/lib/clickhouse/disks/s3_disk/store/551
536K /var/lib/clickhouse/disks/s3_disk/store/551
各 S3 バケット内のデータを確認します(合計は表示されていませんが、両方のバケットにはインサート後に約 36 MiB が保存されています):
S3Express
S3Express は、Amazon S3 における新しい高性能な単一アベイラビリティーゾーン向けストレージクラスです。
S3Express を ClickHouse でテストした際の経験については、この ブログ記事 を参照してください。
注記
S3Express はデータを単一の AZ 内に保存します。これは、AZ 障害時にはデータにアクセスできなくなることを意味します。
S3 disk
S3Express バケット上のストレージをバックエンドとするテーブルを作成するには、次の手順を実行します。
Directory タイプのバケットを作成する- S3 ユーザーに必要なすべての権限を付与するため、適切なバケットポリシーを設定する(例: 無制限アクセスを許可するために
"Action": "s3express:*" を設定)
- ストレージポリシーを設定する際に、
region パラメータを指定する
ストレージ構成は通常の S3 と同じであり、たとえば次のようになります。
<storage_configuration>
<disks>
<s3_express>
<type>s3</type>
<endpoint>https://my-test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/store/</endpoint>
<region>eu-north-1</region>
<access_key_id>...</access_key_id>
<secret_access_key>...</secret_access_key>
</s3_express>
</disks>
<policies>
<s3_express>
<volumes>
<main>
<disk>s3_express</disk>
</main>
</volumes>
</s3_express>
</policies>
</storage_configuration>
次に、新しいストレージ上にテーブルを作成します。
CREATE TABLE t
(
a UInt64,
s String
)
ENGINE = MergeTree
ORDER BY a
SETTINGS storage_policy = 's3_express';
S3 ストレージ
S3 ストレージもサポートされていますが、Object URL パスでのみ利用できます。例:
SELECT * FROM s3('https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/file.csv', ...)
また、設定でバケットのリージョンを指定する必要もあります:
<s3>
<perf-bucket-url>
<endpoint>https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com</endpoint>
<region>eu-north-1</region>
</perf-bucket-url>
</s3>
バックアップ
上で作成したディスクにバックアップを保存できます。
BACKUP TABLE t TO Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status─────────┐
│ c61f65ac-0d76-4390-8317-504a30ba7595 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
RESTORE TABLE t AS t_restored FROM Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status───┐
│ 4870e829-8d76-4171-ae59-cffaf58dea04 │ RESTORED │
└──────────────────────────────────────┴──────────┘