JDBC コネクタ
このコネクタは、データが単純で、int などのプリミティブ型で構成されている場合にのみ使用してください。ClickHouse 固有の型 (例: map) はサポートされていません。
以下の例では、Kafka Connect の Confluent ディストリビューションを使用します。
ここでは、単一の Kafka トピックからメッセージを取得し、ClickHouse テーブルに行を挿入するシンプルなインストール方法について説明します。Kafka 環境をお持ちでない方には、無償枠が充実している Confluent Cloud の利用を推奨します。
JDBC コネクタにはスキーマが必須であることに注意してください (JDBC コネクタではプレーンな JSON や CSV は使用できません) 。スキーマは各メッセージにエンコードすることもできますが、関連するオーバーヘッドを避けるためにConfluent スキーマレジストリを使用することが強く推奨されます。ここで提供する挿入スクリプトは、メッセージからスキーマを自動的に推論してレジストリに登録するため、このスクリプトは他のデータセットにも再利用できます。Kafka のキーは String であることを前提としています。Kafka のスキーマの詳細はこちらを参照してください。
ライセンス
JDBC コネクタは Confluent Community License の下で配布されています。
手順
接続情報を収集する
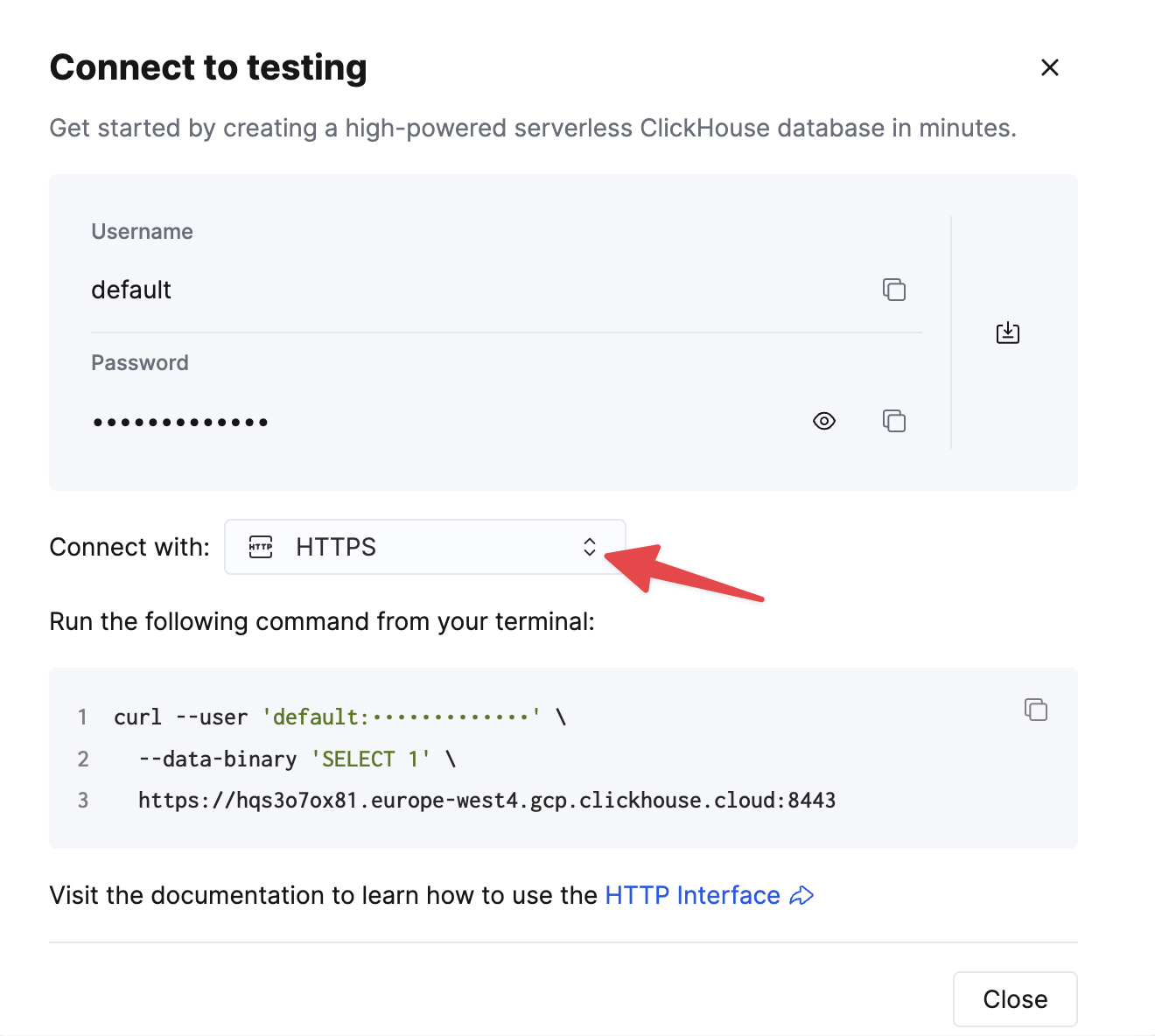
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
| Parameter(s) | Description |
|---|---|
HOST and PORT | 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合のポートは 8123 です。 |
DATABASE NAME | 既定で default という名前のデータベースが用意されています。接続したいデータベースの名前を使用してください。 |
USERNAME and PASSWORD | 既定のユーザー名は default です。用途に応じて適切なユーザー名を使用してください。 |
ClickHouse Cloud サービスに関する詳細情報は、ClickHouse Cloud コンソールで確認できます。 サービスを選択し、Connect をクリックします。
HTTPS を選択します。接続情報は、サンプルの curl コマンド内に表示されます。
セルフマネージドの ClickHouse を使用している場合、接続情報は ClickHouse 管理者によって設定されます。
1. Kafka Connect とコネクタをインストールする
Confluent パッケージをダウンロードしてローカルにインストール済みであることを前提とします。コネクタのインストール手順については、こちらに記載されている手順に従ってください。
confluent-hub によるインストール方法を使用した場合、ローカルの設定ファイルが更新されます。
Kafka から ClickHouse へデータを送信するには、コネクタの Sink コンポーネントを使用します。
2. JDBC ドライバをダウンロードしてインストールする
ClickHouse JDBC ドライバ clickhouse-jdbc-<version>-shaded.jar をこちらからダウンロードしてインストールします。Kafka Connect へのインストール方法はこちらに従ってください。他のドライバも動作する可能性はありますが、検証は行っていません。
よくある問題: ドキュメントでは、jar を share/java/kafka-connect-jdbc/ にコピーするように案内しています。Connect がドライバを見つけられない問題が発生した場合は、ドライバを share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/ にコピーしてください。もしくは、下記のように plugin.path を修正してドライバを含めてください。
3. 設定を準備する
スタンドアロン構成と分散クラスタ構成の違いに注意しながら、インストールタイプに応じた Connect のセットアップについてはこちらの手順に従ってください。Confluent Cloud を使用する場合は、分散構成が該当します。
以下のパラメータは、ClickHouse と組み合わせて JDBC コネクタを使用する際に重要となるものです。パラメータの全一覧はこちらにあります。
_connection.url_- これはjdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>の形式にする必要がありますconnection.user- 対象データベースへの書き込み権限を持つユーザーtable.name.format- データを挿入する ClickHouse テーブル。事前に作成されている必要があります。batch.size- 1 回のバッチで送信する行数。十分に大きな値に設定してください。ClickHouse の推奨事項 に従い、1000 を最小値として検討してください。tasks.max- JDBC Sink コネクタは 1 つ以上のタスクで実行できます。これは性能向上に利用できます。batch.sizeと併用することで、主な性能改善手段となります。value.converter.schemas.enable- スキーマレジストリを使用する場合は false、メッセージ内にスキーマを埋め込む場合は true に設定します。value.converter- 利用するデータ型に応じて設定します。例: JSON の場合はio.confluent.connect.json.JsonSchemaConverter。key.converter-org.apache.kafka.connect.storage.StringConverterを設定します。キーは文字列を使用します。pk.mode- ClickHouse には関連しません。noneに設定してください。auto.create- サポートされていないため、false に設定する必要があります。auto.evolve- 将来的にサポートされる可能性はありますが、この設定は false にすることを推奨します。insert.mode- "insert" に設定します。他のモードは現在サポートされていません。key.converter- キーの型に応じて設定します。value.converter- トピック上のデータ型に基づいて設定します。このデータは JSON、Avro、Protobuf 形式のいずれかのサポート対象スキーマを持っている必要があります。
テスト用にサンプルデータセットを使用する場合は、次の設定になっていることを確認してください:
value.converter.schemas.enable- スキーマレジストリを利用するため false に設定します。各メッセージにスキーマを埋め込む場合は true に設定します。key.converter- "org.apache.kafka.connect.storage.StringConverter" に設定します。キーは文字列を使用します。value.converter- "io.confluent.connect.json.JsonSchemaConverter" に設定します。value.converter.schema.registry.url- スキーマサーバーの URL を設定し、パラメータvalue.converter.schema.registry.basic.auth.user.infoを通じてスキーマサーバーの認証情報を指定します。
GitHub サンプルデータ用の設定ファイル例は、Connect をスタンドアロンモードで実行し、Kafka を Confluent Cloud 上でホストしていることを前提として、こちら から参照できます。
4. ClickHouse テーブルを作成する
テーブルが作成されていることを確認し、以前の例で既に存在している場合は削除してください。縮小版 Github データセットと互換性のある例を以下に示します。現時点ではサポートされていない Array や Map 型を一切使用していないことに注意してください。
5. Kafka Connect を起動する
Kafka Connect を スタンドアロン モードまたは 分散 モードのいずれかで起動します。
6. Kafka にデータを追加する
提供されているスクリプトと設定を使用して、メッセージを Kafka に送信します。github.config を編集し、Kafka の認証情報を設定する必要があります。スクリプトは現在、Confluent Cloud での使用向けに構成されています。
このスクリプトは、任意の ndjson ファイルを Kafka トピックに挿入するために使用できます。自動的にスキーマの推論を試みます。提供されているサンプル設定では 1 万件のメッセージのみを挿入します。必要に応じて こちらを変更 してください。この設定では、Kafka への挿入時に、データセット内の互換性のない Array フィールドも削除します。
JDBC connector がメッセージを INSERT ステートメントに変換するためには、この設定が必要です。独自のデータを使用する場合は、(_value.converter.schemas.enable を true に設定して) 各メッセージにスキーマを含めて送信するか、クライアントがスキーマを参照するメッセージをレジストリに公開していることを確認してください。
Kafka Connect はメッセージの消費を開始し、ClickHouse に行を挿入し始めるはずです。「[JDBC Compliant Mode] Transaction is not supported.」に関する警告メッセージが出力されることがありますが、これは想定された動作であり無視してかまいません。
対象テーブル "Github" に対して単純な読み取りを行うことで、データが挿入されたことを確認できます。
