Dataflow BigQuery から ClickHouse へのテンプレート
BigQuery から ClickHouse へのテンプレートは、BigQuery テーブルから ClickHouse テーブルにデータを取り込むバッチパイプラインです。 このテンプレートでは、テーブル全体を読み取ることも、指定された SQL クエリを使用して特定のレコードをフィルタリングすることもできます。
パイプラインの要件
- ソース BigQuery テーブルが存在している必要があります。
- ターゲット ClickHouse テーブルが存在している必要があります。
- ClickHouse ホストが Dataflow ワーカーマシンからアクセス可能である必要があります。
テンプレートパラメータ
| Parameter Name | Parameter Description | Required | Notes |
|---|---|---|---|
jdbcUrl | jdbc:clickhouse://<host>:<port>/<schema> 形式の ClickHouse JDBC URL。 | ✅ | ユーザー名とパスワードは JDBC オプションとして追加しないでください。その他の JDBC オプションは JDBC URL の末尾に追加できます。ClickHouse Cloud ユーザーは、jdbcUrl に ssl=true&sslmode=NONE を追加してください。 |
clickHouseUsername | 認証に使用する ClickHouse のユーザー名。 | ✅ | |
clickHousePassword | 認証に使用する ClickHouse のパスワード。 | ✅ | |
clickHouseTable | データの挿入先となる ClickHouse テーブル。 | ✅ | |
maxInsertBlockSize | 挿入用のブロック作成を制御する場合の、挿入時の最大ブロックサイズ(ClickHouseIO オプション)。 | ClickHouseIO オプション。 | |
insertDistributedSync | この設定が有効な場合、分散テーブルへの INSERT クエリは、データがクラスタ内のすべてのノードへ送信されるまで待機します(ClickHouseIO オプション)。 | ClickHouseIO オプション。 | |
insertQuorum | レプリケートされたテーブルに対する INSERT クエリで、指定された数のレプリカへの書き込み完了を待機し、データの追加を直列化します。0 の場合は無効。 | ClickHouseIO オプション。この設定はデフォルトのサーバー設定では無効になっています。 | |
insertDeduplicate | レプリケートされたテーブルに対する INSERT クエリで、挿入ブロックの重複排除を実行することを指定します。 | ClickHouseIO オプション。 | |
maxRetries | 1 回の挿入あたりの最大リトライ回数。 | ClickHouseIO オプション。 | |
InputTableSpec | 読み取り元の BigQuery テーブル。inputTableSpec または query のいずれか一方を指定します。両方が設定されている場合は、query パラメータが優先されます。例: <BIGQUERY_PROJECT>:<DATASET_NAME>.<INPUT_TABLE>。 | BigQuery Storage Read API を使用して BigQuery ストレージから直接データを読み取ります。Storage Read API の制限事項 に注意してください。 | |
outputDeadletterTable | 出力テーブルへの書き込みに失敗したメッセージ用の BigQuery テーブル。テーブルが存在しない場合は、パイプライン実行中に作成されます。指定しない場合、<outputTableSpec>_error_records が使用されます。例: <PROJECT_ID>:<DATASET_NAME>.<DEADLETTER_TABLE>。 | ||
query | BigQuery からデータを読み取るために使用する SQL クエリ。BigQuery データセットが Dataflow ジョブとは別のプロジェクトにある場合は、SQL クエリ内で完全なデータセット名を指定します(例: <PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>)。useLegacySql が true の場合を除き、デフォルトでは GoogleSQL が使用されます。 | inputTableSpec または query のいずれか一方を必ず指定してください。両方のパラメータを設定した場合、テンプレートは query パラメータを使用します。例: SELECT * FROM sampledb.sample_table。 | |
useLegacySql | レガシー SQL を使用する場合は true に設定します。このパラメータは query パラメータを使用する場合にのみ適用されます。デフォルトは false。 | ||
queryLocation | 基盤となるテーブルへの権限なしで承認済みビューから読み取る場合に必要です。例: US。 | ||
queryTempDataset | クエリ結果を保存する一時テーブルを作成するために使用する既存のデータセットを指定します。例: temp_dataset。 | ||
KMSEncryptionKey | クエリソースを使用して BigQuery から読み取る場合に、一時テーブルを暗号化するために使用する Cloud KMS キー。例: projects/your-project/locations/global/keyRings/your-keyring/cryptoKeys/your-key。 |
すべての ClickHouseIO パラメータのデフォルト値は、ClickHouseIO Apache Beam Connector に記載されています。
ソースおよびターゲットテーブルのスキーマ
BigQuery のデータセットを ClickHouse に効果的にロードするために、このパイプラインは次の段階からなる列推論プロセスを実行します。
- テンプレートは、ターゲットの ClickHouse テーブルに基づいてスキーマオブジェクトを構築します。
- テンプレートは BigQuery データセットを反復処理し、列名に基づいて列の対応付けを試みます。
ただし、BigQuery データセット(テーブルまたはクエリ)の列名は、ClickHouse のターゲットテーブルと完全に一致している必要があります。
データ型のマッピング
BigQuery の型は、ClickHouse テーブル定義に基づいて変換されます。したがって、上記の表では(特定の BigQuery テーブル/クエリに対して)ClickHouse 側のテーブルで使用することを推奨するマッピングを示しています。
| BigQuery 型 | ClickHouse 型 | 備考 |
|---|---|---|
| 配列型 | 配列型 | 内側の型は、この表に記載されているサポート対象のプリミティブ型のいずれかである必要があります。 |
| ブール型 | Bool 型 | |
| 日付型 | 日付型 | |
| Datetime 型 | Datetime 型 | Enum8、Enum16、FixedString に対しても同様に使用できます。 |
| 文字列型 | 文字列型 | BigQuery では、すべての Int 型(INT、SMALLINT、INTEGER、BIGINT、TINYINT、BYTEINT)は INT64 のエイリアスです。テンプレートは定義されたカラム型(Int8、Int16、Int32、Int64)に基づいてカラムを変換するため、ClickHouse では適切な整数サイズを設定することを推奨します。 |
| 数値 - 整数型 | 整数型 | BigQuery では、すべての Int 型(INT、SMALLINT、INTEGER、BIGINT、TINYINT、BYTEINT)は INT64 のエイリアスです。テンプレートは定義されたカラム型(Int8、Int16、Int32、Int64)に基づいてカラムを変換するため、ClickHouse では適切な整数サイズを設定することを推奨します。また、ClickHouse テーブルで符号なし整数型(UInt8、UInt16、UInt32、UInt64)が使用されている場合も、テンプレートはそれらにも変換します。 |
| 数値 - 浮動小数点型 | 浮動小数点型 | サポートされる ClickHouse 型は Float32 と Float64 です。 |
テンプレートの実行
BigQuery から ClickHouse へのテンプレートは、Google Cloud CLI を通じて実行できます。
本ドキュメント、とくに前述のセクションをよく確認し、テンプレートの構成要件と前提条件を十分に理解してください。
- Google Cloud Console
- Google Cloud CLI
Google Cloud Console にサインインし、Dataflow を検索します。
CREATE JOB FROM TEMPLATEボタンを押します
- テンプレートフォームが開いたら、ジョブ名を入力し、希望するリージョンを選択します。
Dataflow Template入力欄にClickHouseまたはBigQueryと入力し、BigQuery to ClickHouseテンプレートを選択します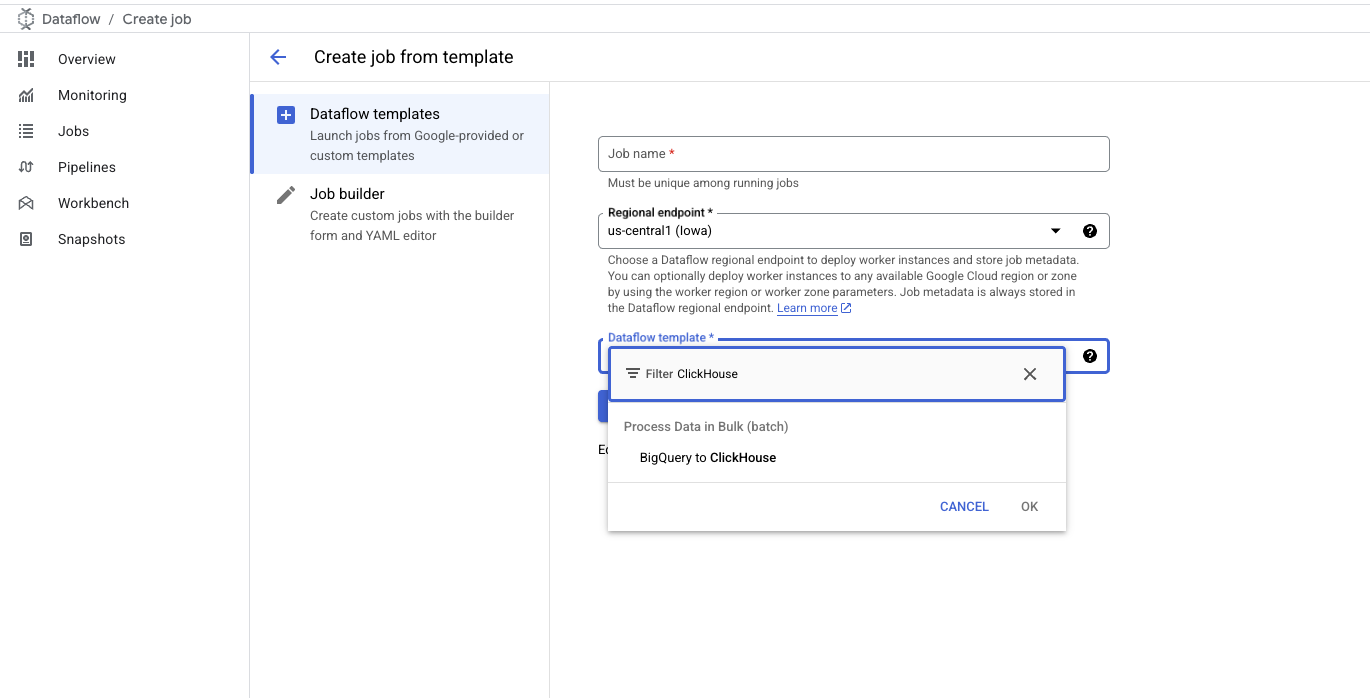
- テンプレートを選択すると、追加の詳細を入力できるようにフォームが展開されます:
- ClickHouse サーバーの JDBC URL(形式:
jdbc:clickhouse://host:port/schema)。 - ClickHouse のユーザー名。
- ClickHouse のターゲットテーブル名。
- ClickHouse サーバーの JDBC URL(形式:
ClickHouse のパスワードオプションは、パスワードが設定されていないユースケース向けに省略可能としてマークされています。
パスワードを追加するには、Password for ClickHouse Endpoint オプションまでスクロールしてください。
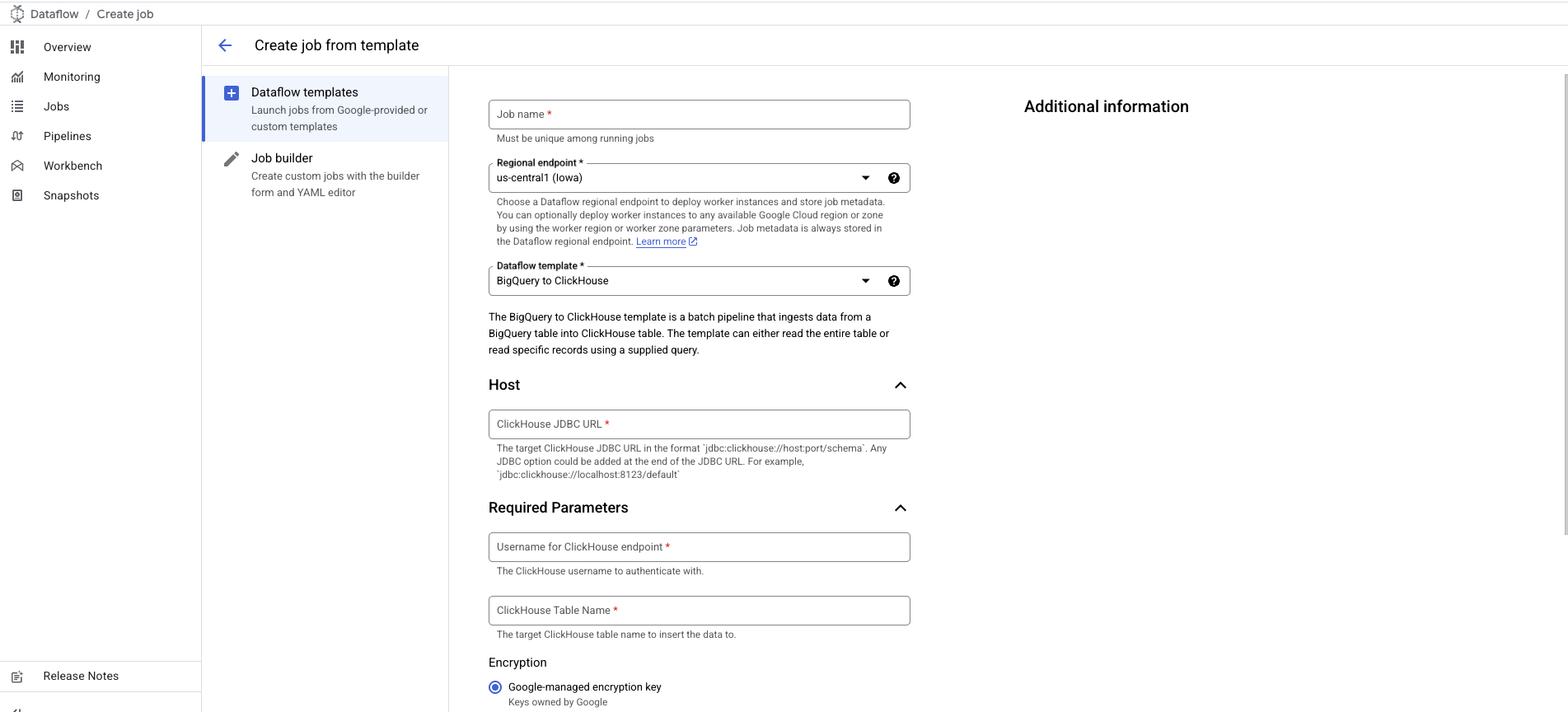
- テンプレートパラメータ セクションで説明されているとおりに、BigQuery/ClickHouseIO 関連の設定をカスタマイズして追加してください。
gcloud CLI のインストールと設定
- まだインストールしていない場合は、
gcloudCLI をインストールします。 - Dataflow テンプレートを実行するために必要な設定・構成・権限を準備するには、
このガイド の
Before you beginセクションに従ってください。
コマンドの実行
gcloud dataflow flex-template run
コマンドを使用して、Flex Template を利用する Dataflow ジョブを実行します。
以下はコマンドの例です:
コマンドの詳細
- ジョブ名:
runキーワードの後に続く文字列が一意のジョブ名です。 - テンプレートファイル:
--template-file-gcs-locationで指定された JSON ファイルには、テンプレートの構造および 受け付けるパラメータに関する詳細が定義されています。記載されているファイルパスは公開されており、すぐに利用できます。 - パラメータ: パラメータはカンマで区切ります。文字列型のパラメータ値は、ダブルクォートで囲んでください。
想定されるレスポンス
コマンドを実行すると、次のようなレスポンスが表示されます:
ジョブの監視
Google Cloud Console の Dataflow Jobs タブ に移動し、 ジョブのステータスを監視します。進捗状況やエラーなどのジョブの詳細を確認できます:

トラブルシューティング
メモリ制限(合計)超過エラー(コード 241)
このエラーは、大きなバッチのデータを処理している際に ClickHouse のメモリが不足した場合に発生します。これを解決するには、次の対応を行います。
- インスタンスのリソースを増やす: データ処理負荷に対応できるよう、より多くのメモリを持つ大きなインスタンスに ClickHouse サーバーをアップグレードします。
- バッチサイズを減らす: Dataflow ジョブ設定でバッチサイズを調整し、より小さなデータチャンクを ClickHouse に送信することで、バッチごとのメモリ消費を抑えます。これらの変更により、データインジェスト時のリソース使用をバランスさせることができます。
テンプレートのソースコード
このテンプレートのソースコードは、以下で公開されています。
GoogleCloudPlatform/DataflowTemplates— アップストリームの Google Cloud Platform リポジトリ。ClickHouse/DataflowTemplates— ClickHouse のフォーク。
