DynamoDB から ClickHouse への CDC
このページでは、ClickPipes を使用して DynamoDB から ClickHouse への CDC(変更データキャプチャ)を構成する方法について説明します。この連携は次の 2 つのコンポーネントから構成されます。
- S3 ClickPipes による初期スナップショット
- Kinesis ClickPipes によるリアルタイム更新
データは ReplacingMergeTree に取り込まれます。このテーブルエンジンは、更新操作を反映できるようにするため、CDC のシナリオで一般的に使用されます。このパターンの詳細については、次のブログ記事を参照してください。
- Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 1
- Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 2
1. Kinesis ストリームをセットアップする
まず、DynamoDB テーブルで Kinesis ストリームを有効にして、変更をリアルタイムで取り込めるようにします。スナップショットを作成する前にこの設定を行うことで、データの取りこぼしを防ぎます。 AWS のガイドはこちらを参照してください。

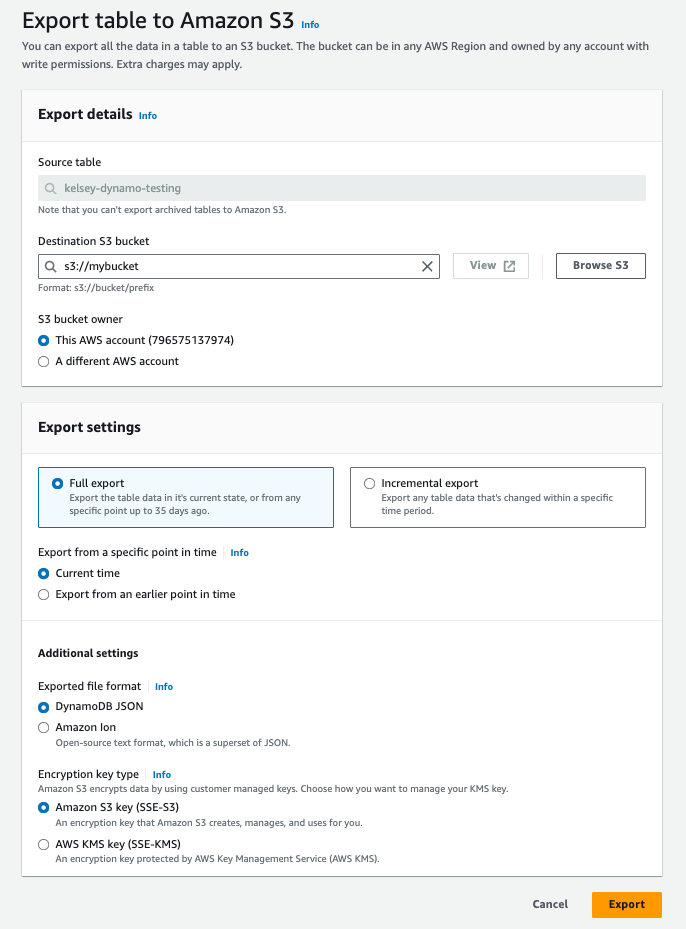
2. スナップショットを作成する
次に、DynamoDB テーブルのスナップショットを作成します。これは、AWS から S3 へのエクスポートで実行できます。AWS のガイドはこちらを参照してください。 DynamoDB JSON 形式で「Full export(フルエクスポート)」を実行してください。
3. スナップショットを ClickHouse に読み込む
必要なテーブルを作成する
DynamoDB からのスナップショットデータは次のような形式になります:
データがネストされた形式になっていることがわかります。このデータを ClickHouse にロードする前にフラット化する必要があります。これは、ClickHouse の JSONExtract 関数を materialized view 内で使用することで実現できます。
ここでは次の 3 つのテーブルを作成します。
- DynamoDB からの生データを保存するテーブル
- フラット化後の最終データを保存するテーブル(宛先テーブル)
- データをフラット化するための materialized view
上記の DynamoDB データの例では、ClickHouse のテーブルは次のようになります。
宛先テーブルには、いくつかの要件を満たす必要があります。
- このテーブルは
ReplacingMergeTreeテーブルである必要があります - テーブルには
versionカラムが必要です- 後続の手順で、Kinesis ストリームの
ApproximateCreationDateTimeフィールドをversionカラムにマッピングします。
- 後続の手順で、Kinesis ストリームの
- テーブルは、パーティションキーをソートキー(
ORDER BYで指定)として使用する必要があります- 同じソートキーを持つ行は、
versionカラムに基づいて重複排除されます。
- 同じソートキーを持つ行は、
スナップショット ClickPipe を作成する
これで、S3 から ClickHouse にスナップショットデータをロードするための ClickPipe を作成できます。S3 ClickPipe ガイドはこちらを参照し、次の設定を使用してください。
- Ingest path: S3 内でエクスポートされた JSON ファイルが存在するパスを特定する必要があります。パスは次のような形式になります。
- Format: JSONEachRow
- Table: スナップショットテーブル(例: 上記の
default.snapshot)
CREATE が完了すると、スナップショットテーブルと転送先テーブルへのデータ投入が始まります。次の手順に進む前にスナップショットの読み込み完了を待つ必要はありません。
4. Kinesis ClickPipe を作成する
ここでは、Kinesis ストリームからのリアルタイムでの変更をキャプチャするための Kinesis ClickPipe をセットアップします。Kinesis ClickPipe ガイドはこちらに従いますが、次の設定を使用してください。
- Stream: ステップ 1 で使用した Kinesis ストリーム
- Table: 宛先テーブル(例: 上記の例では
default.destination) - Flatten object: true
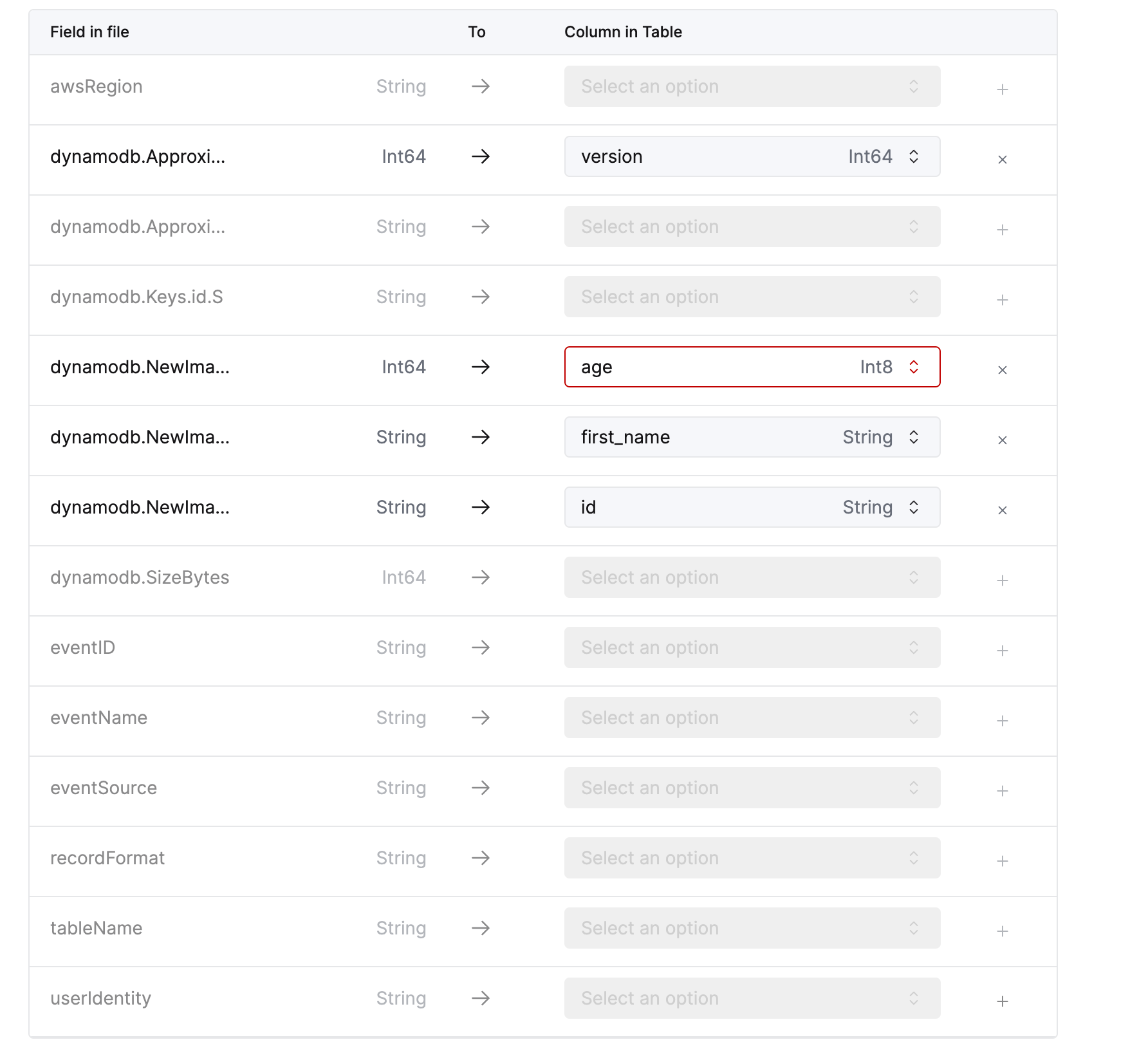
- Column mappings:
ApproximateCreationDateTime:version- 他のフィールドは、以下に示すように適切な宛先カラムにマッピングします
5. クリーンアップ(任意)
スナップショット ClickPipe の処理が完了したら、スナップショットテーブルと materialized view を削除して構いません。
