ClickHouse と Databricks の連携
ClickHouse Spark コネクタは Databricks とシームレスに連携します。このガイドでは、Databricks 向けのプラットフォーム固有のセットアップ、インストール、使用方法について説明します。
Databricks 向けの API 選択
デフォルトでは、Databricks は Unity Catalog を使用しており、これによって Spark カタログの登録がブロックされます。この場合は、必ず TableProvider API(フォーマットベースのアクセス)を使用する必要があります。
一方、No isolation shared アクセスモードでクラスターを作成して Unity Catalog を無効化した場合は、代わりに Catalog API を使用できます。Catalog API は集中管理された構成とネイティブな Spark SQL 連携を提供します。
| Unity Catalog の状態 | 推奨 API | 備考 |
|---|---|---|
| 有効(デフォルト) | TableProvider API(フォーマットベース) | Unity Catalog により Spark カタログの登録がブロックされる |
| 無効(No isolation shared) | Catalog API | "No isolation shared" アクセスモードのクラスターが必要 |
Databricks でのインストール
オプション 1: Databricks UI から JAR をアップロードする
-
ランタイム JAR をビルドするか、ダウンロード します:
-
Databricks ワークスペースに JAR をアップロードします:
- Workspace に移動し、目的のフォルダに移動します
- Upload をクリックし、JAR ファイルを選択します
- JAR はワークスペース内に保存されます
-
クラスターにライブラリをインストールします:
- Compute に移動し、対象のクラスターを選択します
- Libraries タブをクリックします
- Install New をクリックします
- DBFS または Workspace を選択し、アップロードした JAR ファイルを指定します
- Install をクリックします
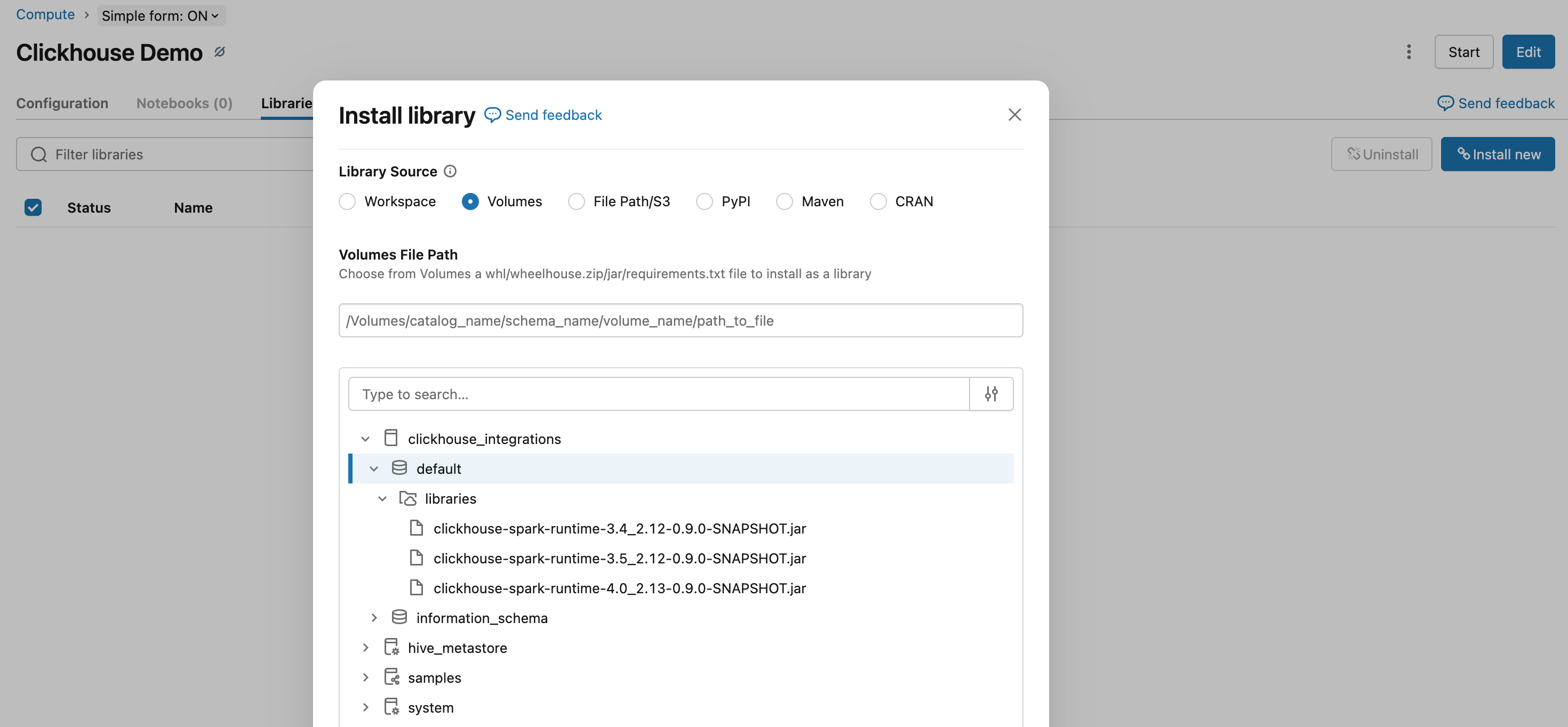
- ライブラリを読み込むためにクラスターを再起動します
オプション 2: Databricks CLI を使用してインストールする
オプション 3: Maven Coordinates(推奨)
-
Databricks ワークスペースに移動します:
- Compute を開き、クラスタを選択します
- Libraries タブをクリックします
- Install New をクリックします
- Maven タブを選択します
-
Maven の座標を追加します:
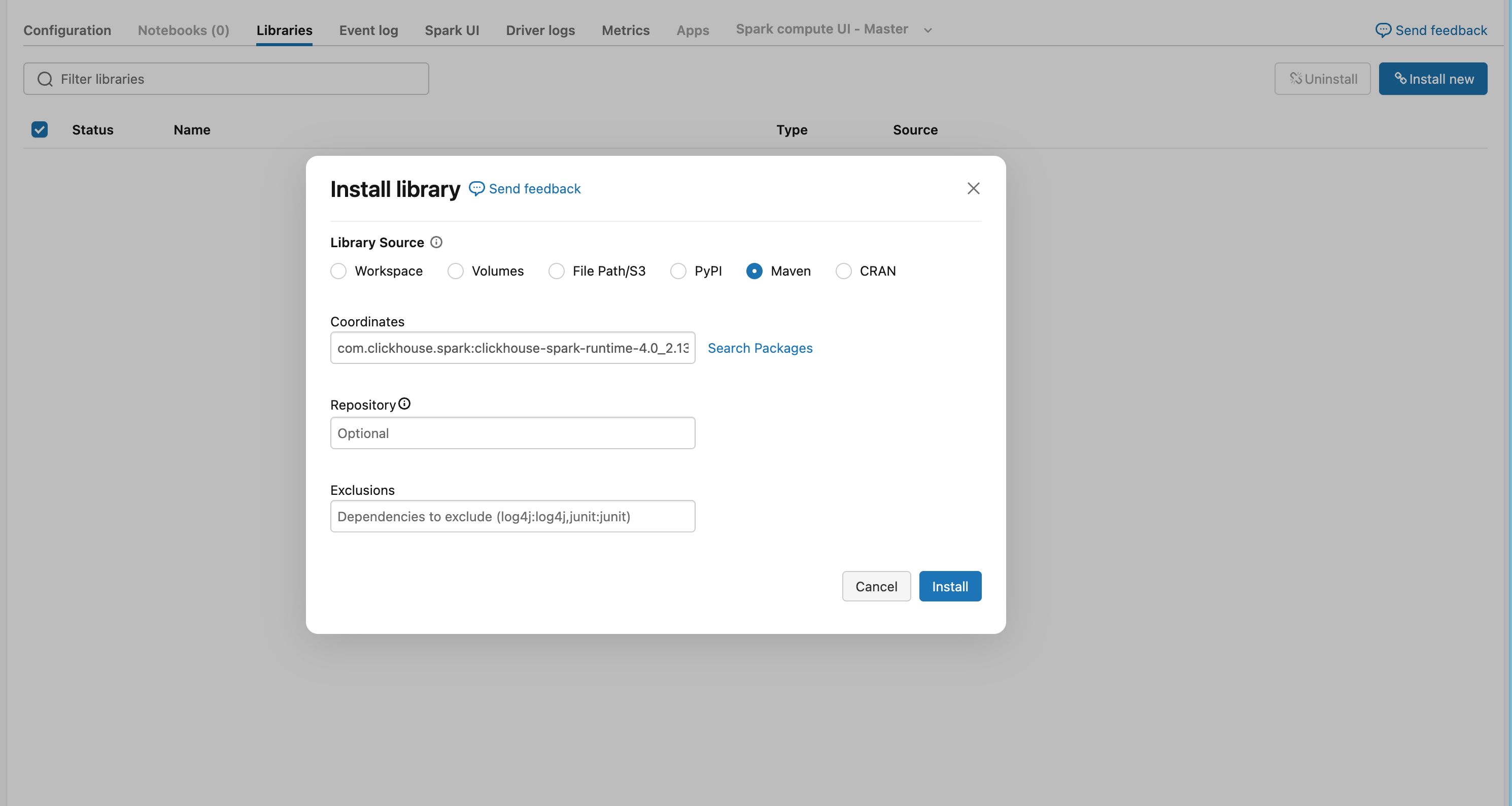
- Install をクリックし、ライブラリを有効にするためにクラスタを再起動します
TableProvider API を使用する
Unity Catalog が有効な場合(デフォルト)には、Unity Catalog によって Spark カタログへの登録がブロックされるため、必ず TableProvider API(フォーマットベースのアクセス)を使用する必要があります。クラスターで "No isolation shared" アクセスモードを使用して Unity Catalog を無効化している場合は、代わりに Catalog API を使用できます。
データの読み込み
- Python
- Scala
データの書き込み
- Python
- Scala
この例では、Databricks でシークレットスコープが事前に構成されていることを前提としています。セットアップ方法については、Databricks の Secret management documentation を参照してください。
Databricks 特有の考慮事項
アクセスモードの要件
ClickHouse Spark Connector を使用するには、Dedicated(旧 Single User)アクセスモードが必須です。Unity Catalog が有効な場合、その構成では Databricks が外部の DataSource V2 コネクタをブロックするため、Standard(旧 Shared)アクセスモードはサポートされません。
| アクセスモード | Unity Catalog | サポート状況 |
|---|---|---|
| Dedicated (Single User) | 有効 | ✅ Yes |
| Dedicated (Single User) | 無効 | ✅ Yes |
| Standard (Shared) | 有効 | ❌ No |
| Standard (Shared) | 無効 | ✅ Yes |
シークレット管理
Databricks のシークレットスコープを利用して、ClickHouse の認証情報を安全に格納します。
セットアップ手順については、Databricks のシークレット管理に関するドキュメントを参照してください。
ClickHouse Cloud への接続
Databricks から ClickHouse Cloud に接続する場合には:
- HTTPS プロトコル を使用します(
protocol: https、http_port: 8443) - SSL を有効にします(
ssl: true)
例
ワークフロー全体の例
- Python
- Scala
関連ドキュメント
- Spark ネイティブコネクタ ガイド - コネクタに関する包括的なドキュメント
- TableProvider API ドキュメント - フォーマットベースのアクセス方法の詳細
- Catalog API ドキュメント - カタログベースのアクセス方法の詳細
