Azure Synapse と ClickHouse の連携
Azure Synapse は、ビッグデータ、データサイエンス、データウェアハウスを組み合わせることで、高速かつ大規模なデータ分析を可能にする統合分析サービスです。 Synapse では、Spark プールにより、オンデマンドでスケーラブルな Apache Spark クラスターを利用でき、複雑なデータ変換、機械学習、外部システムとの連携を実行できます。
この記事では、Azure Synapse で Apache Spark を使用する際に、ClickHouse Spark connector を統合する方法を説明します。
コネクタの依存関係を追加する
Azure Synapse では、パッケージ管理が次の 3 つのレベルでサポートされています。
- 既定のパッケージ
- Spark プール レベル
- セッション レベル
Apache Spark プールのライブラリを管理するガイドに従って、次の必須依存関係を Spark アプリケーションに追加してください。
clickhouse-spark-runtime-{spark_version}_{scala_version}-{connector_version}.jar- 公式 Mavenclickhouse-jdbc-{java_client_version}-all.jar- 公式 Maven
用途に適したバージョンを確認するには、Spark Connector Compatibility Matrix のドキュメントを参照してください。
ClickHouse をカタログとして追加する
Spark 設定をセッションに追加する方法はいくつかあります。
- セッションの読み込み時に使用するカスタム設定ファイル
- Azure Synapse UI から設定を追加する
- Synapse notebook で設定を追加する
次の Apache Spark 構成の管理 に従って、コネクタに必要な Spark 設定 を追加します。
たとえば、ノートブックで次の設定を使用して Spark セッションを構成できます。
次のように、最初のセルに配置されていることを確認してください。
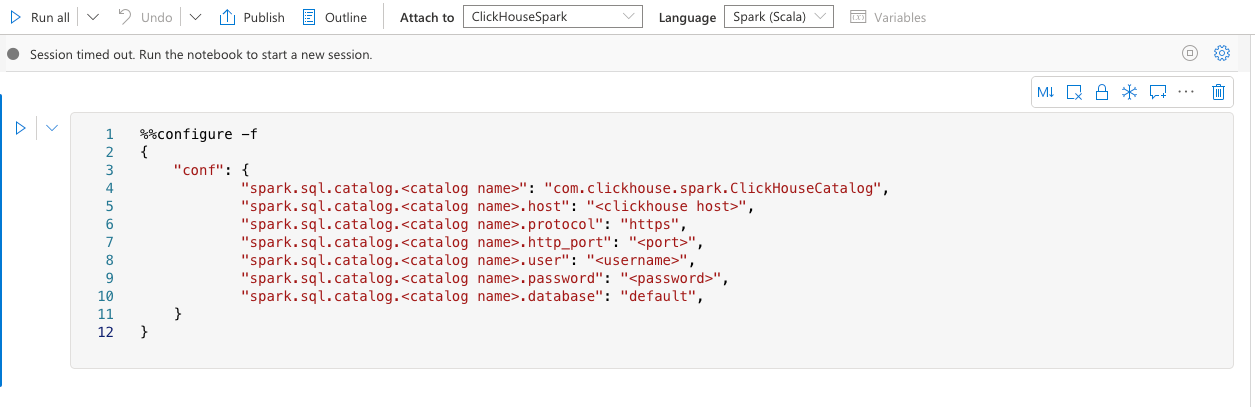
追加の設定については、ClickHouse Spark 設定ページを参照してください。
ClickHouse Cloud を使用する場合は、必ず必要な Spark 設定を設定してください。
セットアップの確認
依存関係と設定が正しく反映されていることを確認するには、セッションの Spark UI にアクセスし、Environment タブを開いてください。
そこで、ClickHouse 関連の設定を確認します。

