ClickHouse の `azureBlobStorage` テーブル関数の使用
これは、Azure Blob Storage または Azure Data Lake Storage から ClickHouse へ データをコピーするための、最も効率的でシンプルな方法の 1 つです。この テーブル関数を使うことで、ClickHouse に Azure ストレージへ直接接続させ、 オンデマンドでデータを読み取るよう指示できます。
この関数は、テーブルに似たインターフェイスを提供し、ソースから直接
SELECT、INSERT、およびフィルタリングを行うことができます。この関数は
高度に最適化されており、CSV、JSON、Parquet、Arrow、TSV、ORC、
Avro など、広く利用されている多くのファイル形式をサポートします。サポート
している形式の網羅的な一覧は、"データ形式" を参照して
ください。
このセクションでは、Azure Blob Storage から ClickHouse へデータを転送する
ためのシンプルな入門ガイドと、この関数を効果的に使用するうえで重要な注意点に
ついて説明します。詳細および高度なオプションについては、公式ドキュメントを
参照してください:
azureBlobStorage テーブル関数ドキュメントページ
Azure Blob Storage アクセスキーの取得
ClickHouse から Azure Blob Storage にアクセスできるようにするには、アクセスキー付きの接続文字列が必要です。
-
Azure ポータルで、Storage Account に移動します。
-
左側のメニューで、Security + networking セクションの下にある Access keys を選択します。
-
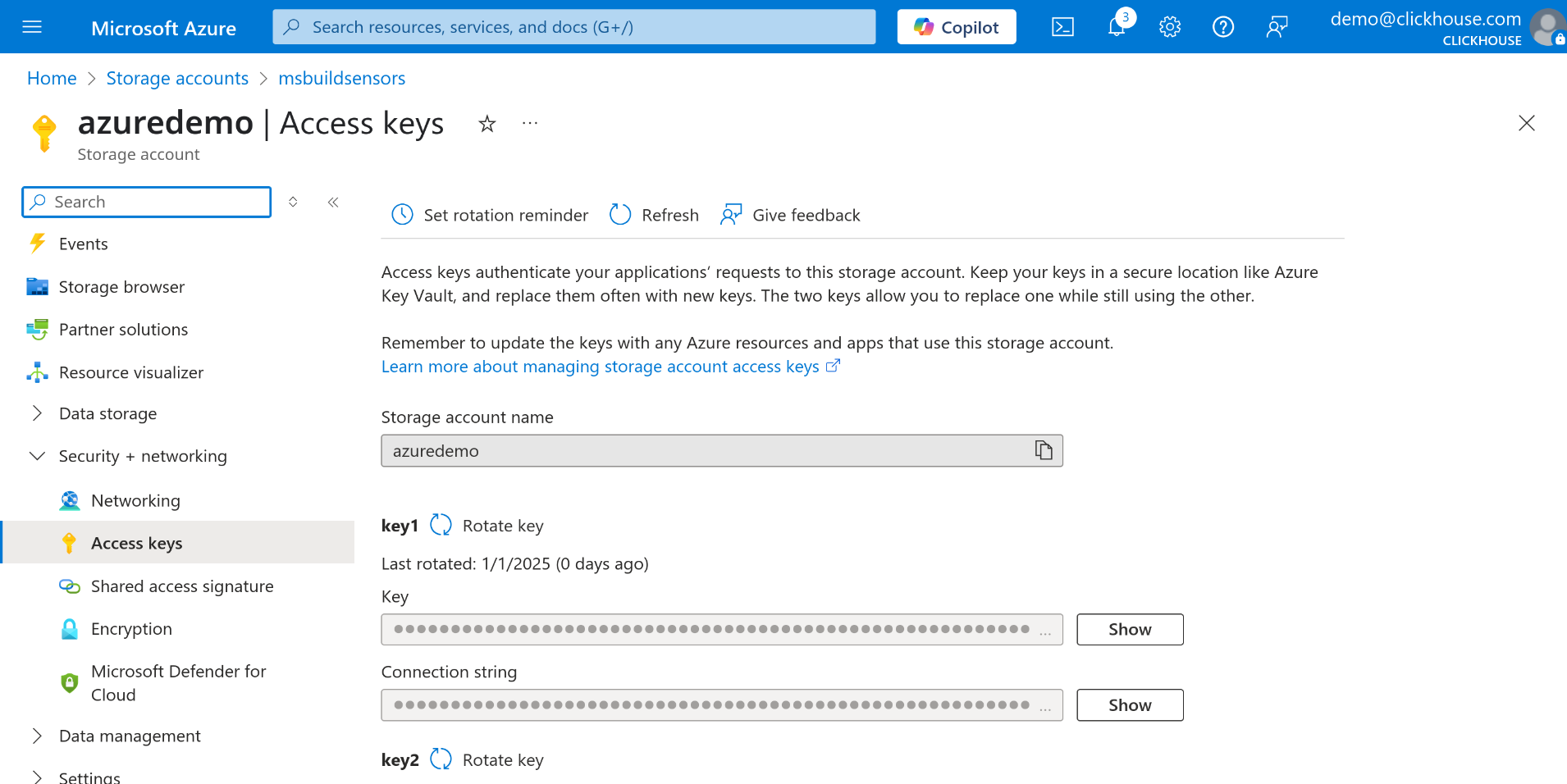
key1 または key2 のいずれかを選択し、Connection string フィールドの横にある Show ボタンをクリックします。
-
接続文字列をコピーします。この文字列は azureBlobStorage テーブル関数のパラメーターとして指定します。
Azure Blob Storage 上のデータをクエリする
利用している ClickHouse のクエリコンソールを開きます。これは ClickHouse Cloud の Web インターフェイス、ClickHouse CLI クライアント、またはクエリを実行するために使用しているその他のツールのいずれでも構いません。接続文字列と ClickHouse のクエリコンソールの両方が用意できたら、Azure Blob Storage 上のデータに対して直接クエリを実行できるようになります。
次の例では、data-container という名前のコンテナ内にある JSON ファイルに保存されたすべてのデータをクエリします。
そのデータをローカルの ClickHouse テーブル(例: my_table)にコピーするには、
INSERT INTO ... SELECT 文を使用できます。
これにより、ETL の中間処理を挟むことなく、外部データを ClickHouse に効率的に取り込めます。
Environmental Sensors データセットを使った簡単な例
例として、Environmental Sensors データセットから 1 つのファイルをダウンロードします。
-
Environmental Sensors データセット から サンプルファイル をダウンロードします。
-
Azure ポータルで、まだストレージ アカウントを持っていない場合は、新しいストレージ アカウントを作成します。
ストレージ アカウントで Allow storage account key access が有効になっていることを確認してください。 無効になっている場合、アカウント キーを使用してデータにアクセスできません。
-
ストレージ アカウントに新しいコンテナーを作成します。この例では、コンテナー名を sensors とします。 既存のコンテナーを使用する場合は、この手順をスキップできます。
-
先ほどダウンロードした
2019-06_bmp180.csv.zstファイルをコンテナーにアップロードします。 -
前の手順で説明したとおりに、Azure Blob Storage の接続文字列を取得します。
ここまでの設定が完了したら、Azure Blob Storage からデータに対して直接クエリを実行できます。
- データをテーブルに読み込むには、元のデータセットで使用されているスキーマの簡略版を作成します:
Azure Blob Storage のような外部ソースに対してクエリを実行する際の構成オプションやスキーマ推論の詳細については、入力データからの自動スキーマ推論を参照してください。
- 次に、Azure Blob Storage から sensors テーブルにデータを挿入します:
これで、Azure Blob Storage に保存されている 2019-06_bmp180.csv.zst ファイルからのデータが sensors テーブルに読み込まれました。
参考資料
ここでは、azureBlobStorage テーブル関数の基本的な使い方のみを紹介しました。より高度なオプションや設定の詳細については、公式ドキュメントを参照してください。
