ReplacingMergeTree エンジンの使用
トランザクションデータベースは更新および削除を伴うトランザクションワークロードに最適化されていますが、OLAP データベースはそのような操作に対する保証は相対的に弱くなります。その代わりに、分析クエリを大幅に高速化するために、バッチで insert される不変データ向けに最適化されています。ClickHouse はミューテーションによる更新操作と、行を削除する軽量な手段の両方を提供しますが、前述のとおりカラム指向の構造であるため、これらの操作は慎重にスケジュールする必要があります。これらの操作は非同期で処理され、単一スレッドで実行され、 (更新の場合) ディスク上のデータを書き換える必要があります。そのため、多数の細かな変更には使用すべきではありません。 上記のような使用パターンを避けつつ更新および削除対象の行ストリームを処理するために、ClickHouse のテーブルエンジンである ReplacingMergeTree を使用できます。
挿入行の自動アップサート
ReplacingMergeTree テーブルエンジン を使用すると、ユーザーが同一行を複数回挿入し、そのうち 1 つを最新バージョンとして指定できるため、非効率な ALTER や DELETE 文を使用せずに行を更新できます。バックグラウンドプロセスによって、同じ行の古いバージョンが非同期に削除され、不変な挿入のみを用いて更新操作を効率的に模倣します。
これは、テーブルエンジンが重複行を識別できることに依存しています。これは ORDER BY 句を使用して一意性を判定することで実現されます。すなわち、ORDER BY で指定された列について 2 行が同じ値を持つ場合、それらは重複と見なされます。テーブル定義時に指定される version 列により、2 行が重複と識別された際に、行の最新バージョンを保持できます。すなわち、バージョン値が最大の行が保持されます。
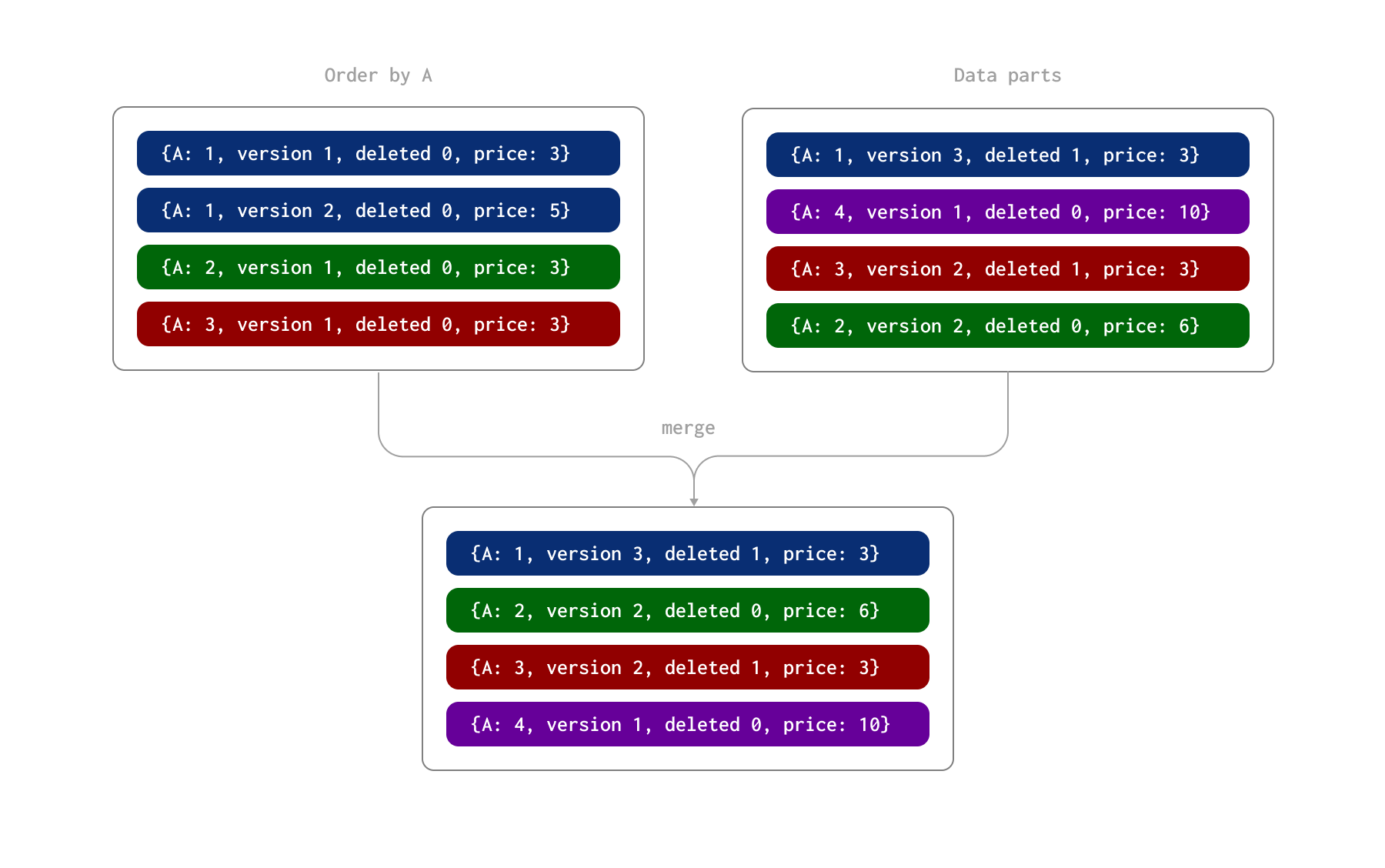
このプロセスを以下の例で示します。ここでは、行は A 列(テーブルの ORDER BY)によって一意に識別されます。これらの行は 2 つのバッチで挿入され、その結果としてディスク上に 2 つのデータパーツが形成されたと仮定します。その後、非同期のバックグラウンドプロセスによって、これらのパーツがマージされます。
ReplacingMergeTree では、さらに deleted 列を指定することもできます。これは 0 または 1 を取り、値が 1 の場合はその行(およびその重複行)が削除されたことを示し、それ以外の場合は 0 が使用されます。注: 削除された行はマージ時には削除されません。
このプロセス中、パーツのマージ時に以下が発生します。
- 列 A の値が 1 の行には、version 2 の更新行と version 3 の削除行(
deleted列の値が 1)が存在します。最新の行は削除済みとしてマークされているため、その行が保持されます。 - 列 A の値が 2 の行には 2 つの更新行があります。後の行が保持され、price 列の値は 6 になります。
- 列 A の値が 3 の行には version 1 の行と version 2 の削除行があります。この削除行が保持されます。
このマージプロセスの結果として、最終状態を表す 4 行が得られます。
削除された行は決して自動的には削除されないことに注意してください。OPTIMIZE table FINAL CLEANUP を使用して強制的に削除できます。これには実験的設定 allow_experimental_replacing_merge_with_cleanup=1 が必要です。これは次の条件を満たす場合にのみ発行する必要があります。
- クリーンアップによって削除される行について、その後に古いバージョンの行が挿入されないことを確信できる場合。もし挿入された場合、削除済みの行がもはや存在しないため、それらは誤って保持されてしまいます。
- クリーンアップを発行する前に、すべてのレプリカが同期していることを確認してください。これは次のコマンドで実行できます。
(1) が満たされていることが保証されてからインサート処理を一時停止し、このコマンドとその後のクリーンアップが完了するまで継続することを推奨します。
ReplacingMergeTree を用いた削除の処理は、上記の条件でクリーンアップのための期間をスケジュールできる場合を除き、削除件数が少量から中程度(10% 未満)のテーブルにのみ推奨されます。
ヒント: 変更が発生しなくなった特定のパーティションに対して
OPTIMIZE FINAL CLEANUPを実行することもできます。
プライマリキー/重複排除キーの選択
前述のとおり、ReplacingMergeTree の場合には、追加で満たすべき重要な制約があります。それは、ORDER BY の列の値が、変更をまたいでも行を一意に識別できなければならない、というものです。Postgres のようなトランザクションデータベースから移行する場合、元の Postgres のプライマリキーを ClickHouse の ORDER BY 句に含める必要があります。
ClickHouse のユーザーであれば、テーブルの ORDER BY 句に指定する列をクエリパフォーマンスを最適化するために選択することには慣れているはずです。一般的に、これらの列は、頻出クエリに基づいて選択し、カーディナリティが低いものから高いものの順に並べるべきです。重要な点として、ReplacingMergeTree には追加の制約があります。これらの列は不変(immutable)でなければなりません。つまり、Postgres からレプリケーションする場合、基盤となる Postgres データで値が変化しない列だけをこの句に追加してください。他の列は変更されてもかまいませんが、一意な行を識別するために、これらの列は常に一貫している必要があります。
分析ワークロードにおいては、ユーザーがポイントルックアップ(特定行の直接参照)を行うことはまれなため、Postgres のプライマリキーは一般的にあまり役に立ちません。列をカーディナリティの低い順に並べることを推奨していること、また ORDER BY において前方に記載された列での一致のほうが通常は高速であるという事実を踏まえると、Postgres のプライマリキーは(分析的な価値がない限り)ORDER BY の末尾に付け足すべきです。Postgres 側で複数列から成るプライマリキーを使用している場合も、カーディナリティとクエリ上の価値の可能性を考慮しつつ、それらを ORDER BY の末尾に追加してください。ユーザーは、MATERIALIZED 列を使って値を連結し、一意なプライマリキーを生成することもできます。
Stack Overflow データセットに含まれる posts テーブルを考えてみましょう。
ORDER BY キーとして (PostTypeId, toDate(CreationDate), CreationDate, Id) を使用します。各投稿に対して一意な Id カラムによって、行の重複排除を行えるようにしています。要件に応じて、スキーマには Version カラムと Deleted カラムが追加されます。
ReplacingMergeTree でのクエリ実行
マージ時に、ReplacingMergeTree は ORDER BY 列の値を一意な識別子として使用して重複行を特定し、最新バージョンが削除を示している場合にはすべての重複を削除し、そうでなければ最も高いバージョンのみを保持します。ただし、これはあくまで最終的にのみ正しい状態に近づける仕組みであり、行が必ず重複排除されることは保証されないため、これに依存すべきではありません。更新行や削除行もクエリの対象となるため、クエリが誤った結果を返す可能性があります。
正しい結果を得るには、バックグラウンドマージに加えて、クエリ時の重複排除と削除行の除去を組み合わせる必要があります。これは FINAL 演算子を使用することで実現できます。
先ほどの posts テーブルを考えてみます。このデータセットを読み込む際には、通常の方法でロードしつつ、値を 0 とした deleted 列と version 列も指定します。例として、ここでは 10000 行のみをロードします。
行数を確認してみましょう:
ここで、投稿の回答に関する統計情報を更新します。これらの値を直接更新するのではなく、5000 行分のコピーを新たに挿入し、それらのバージョン番号を 1 つ増やします(つまり、テーブル内には 150 行が存在することになります)。これは、簡単な INSERT INTO SELECT でシミュレートできます。
さらに、行を再挿入する際に Deleted 列の値を 1 に設定することで、ランダムな 1000 件の投稿を削除します。同様に、これは単純な INSERT INTO SELECT 文でシミュレートできます。
上記の操作の結果は 16,000 行、すなわち 10,000 + 5000 + 1000 行になります。ここでの本来の正しい合計は、元の合計から 1000 行を差し引いた値、すなわち 10,000 - 1000 = 9000 行となるはずです。
ここで得られる結果は、これまでに行われたマージ処理の内容によって変動します。重複した行が存在するため、ここで表示される合計値が本来と異なっていることがわかります。テーブルに FINAL を適用すると、正しい結果が得られます。
FINAL のパフォーマンス
FINAL 演算子は、クエリに対してわずかなパフォーマンス上のオーバーヘッドを伴います。
これは、クエリがプライマリキー列でフィルタしていない場合に最も顕著で、
より多くのデータを読み込むことになり、その結果、重複排除のオーバーヘッドが増加します。WHERE 条件でキー列をフィルタする場合、読み込まれて重複排除に渡されるデータ量は減少します。
WHERE 条件でキー列を使用していない場合、FINAL 使用時には現時点で ClickHouse は PREWHERE 最適化を利用しません。この最適化は、フィルタ対象外の列に対して読み取る行数を削減することを目的としています。この PREWHERE をエミュレートし、その結果としてパフォーマンスの向上につながる可能性がある例はこちらにあります。
ReplacingMergeTree でパーティションを活用する
ClickHouse におけるデータのマージ処理はパーティション単位で行われます。ReplacingMergeTree を使用する場合、行に対してこのパーティションキーが変更されない ことを保証できるのであれば、ベストプラクティスに従ってテーブルをパーティション分割することを推奨します。これにより、同じ行に対する更新が同じ ClickHouse パーティションに送信されるようになります。ここで説明するベストプラクティスに従う限り、Postgres と同じパーティションキーを再利用することもできます。
この前提が成り立つ場合、do_not_merge_across_partitions_select_final=1 設定を使用して FINAL クエリのパフォーマンスを向上させることができます。この設定により、FINAL を使用するときにパーティションが互いに独立してマージおよび処理されます。
次のような posts テーブルを考えます。ここではパーティション分割を行っていません。
FINAL が実際に処理を行う必要が生じるようにするため、100万行を更新します。これは、重複する行を挿入して AnswerCount をインクリメントすることで行います。
FINAL を使って年ごとの回答数を集計する:
年単位でパーティション分割したテーブルに対しても同じ手順を実行し、そのうえで do_not_merge_across_partitions_select_final=1 を指定して上記のクエリを再実行します。
示したように、このケースでは、パーティショニングによって重複排除処理をパーティション単位で並列に実行できるようになった結果、クエリのパフォーマンスが大幅に向上しました。
マージ動作に関する考慮事項
ClickHouse のマージ選択メカニズムは、単純にパーツをマージするだけのものではありません。以下では、ReplacingMergeTree の文脈でこの動作を取り上げ、古いデータに対してより積極的なマージを有効にするための設定オプションや、大きなパーツを扱う際の考慮事項について説明します。
マージ選択ロジック
マージの目的はパーツ数を最小限に抑えることですが、その一方で書き込み増幅によるコストとのバランスも考慮されます。その結果として、内部計算に基づき、過度な書き込み増幅を招くパーツの範囲はマージ対象から除外されます。この動作により、不要なリソース消費を防ぎ、ストレージコンポーネントの寿命を延ばすことができます。
大きなパーツに対するマージ動作
ClickHouse の ReplacingMergeTree エンジンは、指定された一意キーに基づいて各行の最新バージョンのみを保持するようにデータパーツをマージし、重複行を管理するよう最適化されています。しかし、マージされたパーツが max_bytes_to_merge_at_max_space_in_pool のしきい値に達すると、min_age_to_force_merge_seconds が設定されていても、それ以上マージ対象として選択されなくなります。その結果、継続的なデータ挿入によって蓄積される重複を自動マージに頼って除去することはできなくなります。
これに対処するために、OPTIMIZE FINAL を実行してパーツを手動でマージし、重複を除去できます。自動マージとは異なり、OPTIMIZE FINAL は max_bytes_to_merge_at_max_space_in_pool のしきい値を無視し、主にディスク容量などの利用可能なリソースのみを基準として、各パーティションが 1 つのパーツになるまでマージを行います。ただし、この方法は大規模なテーブルではメモリ消費が大きくなり、新しいデータが追加されるたびに繰り返し実行が必要になる場合があります。
パフォーマンスを維持しつつ、より持続的な解決策とするには、テーブルのパーティション分割を推奨します。これにより、データパーツが最大マージサイズに達することを防ぎ、継続的な手動最適化の必要性を低減できます。
パーティション分割とパーティションをまたぐマージ
「Exploiting Partitions with ReplacingMergeTree」で説明しているとおり、ベストプラクティスとしてテーブルをパーティション分割することを推奨しています。パーティション分割によりデータが分離され、より効率的なマージが可能になり、とくにクエリ実行時にパーティションをまたぐマージを回避できます。この動作は 23.12 以降のバージョンでさらに強化されています。パーティションキーがソートキーのプレフィックスである場合、クエリ実行時にパーティションをまたぐマージは行われず、クエリ性能の向上につながります。
クエリ性能向上のためのマージ調整
デフォルトでは、min_age_to_force_merge_seconds と min_age_to_force_merge_on_partition_only はそれぞれ 0 と false に設定されており、これらの機能は無効になっています。この構成では、ClickHouse はパーティションの経過時間に基づいてマージを強制することなく、標準的なマージ動作を適用します。
min_age_to_force_merge_seconds に値を設定すると、ClickHouse は指定期間より古いパーツに対して通常のマージ用ヒューリスティクスを無視します。これは一般的には総パーツ数の最小化を目的とする場合にのみ有効ですが、クエリ時にマージが必要なパーツ数を減らすことで、ReplacingMergeTree におけるクエリ性能を向上させることができます。
さらに min_age_to_force_merge_on_partition_only=true を設定することで、この動作をより細かく調整できます。この場合、積極的なマージを行うには、パーティション内のすべてのパーツが min_age_to_force_merge_seconds より古い必要があります。この構成により、古いパーティションは時間の経過とともに 1 つのパーツにマージされ、データが集約されることでクエリ性能を維持できます。
推奨設定
マージ動作のチューニングは高度な操作です。本番ワークロードでこれらの設定を有効にする前に、ClickHouse サポートへ相談することを推奨します。
多くの場合、min_age_to_force_merge_seconds はパーティション期間よりも十分に短い低い値に設定するのが望ましいです。これによりパーツ数を最小限に抑え、FINAL 演算子を使用したクエリ実行時の不要なマージを防ぐことができます。
たとえば、すでに 1 つのパーツにマージ済みの月次パーティションを考えます。このパーティション内に小さな単発の挿入が行われ、新たなパーツが作成された場合、マージが完了するまで ClickHouse は複数のパーツを読み取る必要があるため、クエリ性能が低下する可能性があります。min_age_to_force_merge_seconds を設定しておくと、これらのパーツが積極的にマージされ、クエリ性能の劣化を防ぐことができます。
