ClickHouse における JOIN の使い方
ClickHouse は完全な JOIN サポートを提供しており、幅広い結合アルゴリズムを利用できます。パフォーマンスを最大化するために、本ガイドで挙げる結合最適化の推奨事項に従うことをお勧めします。
- 最適なパフォーマンスを得るには、特にミリ秒単位の応答が要求されるリアルタイム分析ワークロードにおいて、クエリ内の
JOINの数を減らすことを目標にしてください。1 つのクエリでの JOIN の数は最大 3〜4 個を目安とします。データモデリングのセクションでは、非正規化、辞書、マテリアライズドビューなど、JOIN を最小限に抑えるためのいくつかの工夫について詳しく説明しています。 - ClickHouse 24.12 以降では、クエリプランナーが 2 つのテーブル間の JOIN を自動的に並べ替え、小さいテーブルを右側に配置してパフォーマンスを最適化します。バージョン 25.9 では、3 つ以上のテーブルを結合するクエリに対して JOIN の順序を最適化できるように拡張されました。
- クエリで、以下に示す
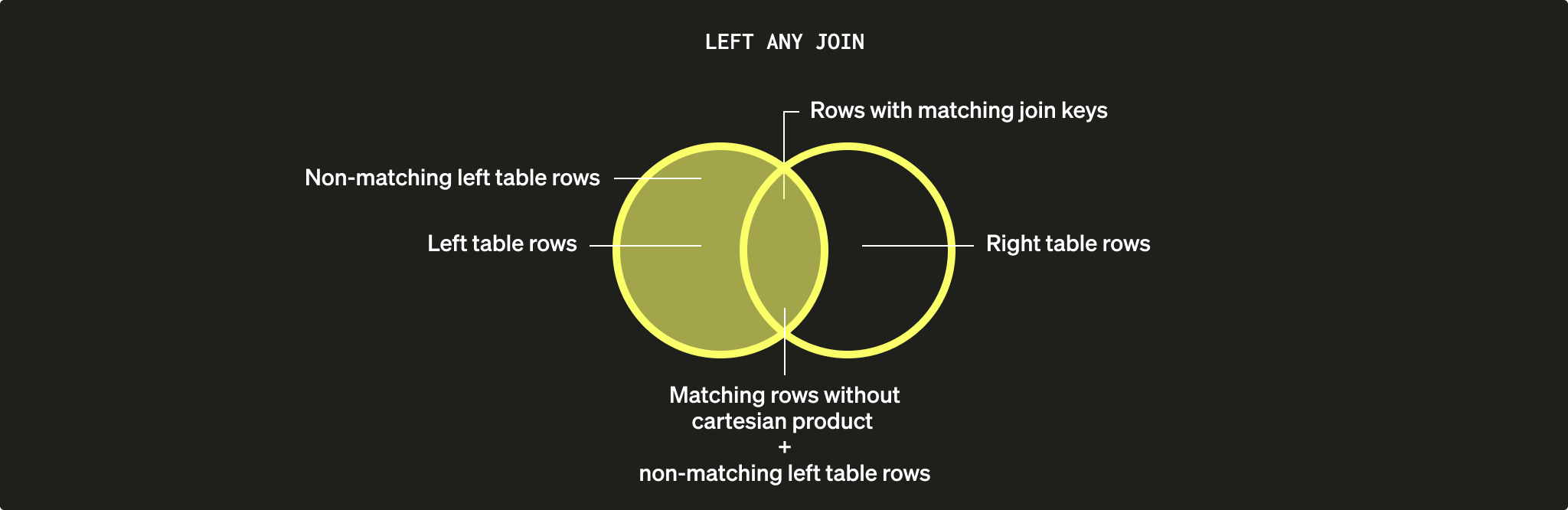
LEFT ANY JOINのような直接結合が必要な場合は、可能な限り Dictionaries を使用することをお勧めします。
- 内部結合を実行する場合、多くの場合は
IN句を使用したサブクエリとして記述した方がより効率的です。次のクエリを考えてみてください。これらは機能的には同等であり、いずれも質問本文には ClickHouse が含まれていないがcommentsには含まれているpostsの件数を取得します。
INNER JOIN ではなく ANY INNER JOIN を使用しているのは、直積(cartesian product)を避けたい、つまり各 post につき 1 件だけマッチさせたいからです。
この結合はサブクエリを使って書き換えることで、パフォーマンスを大幅に向上させられます。
ClickHouse は、すべての JOIN 句およびサブクエリに対して条件のプッシュダウンを試みますが、可能な限りすべてのサブ句に条件を手動で適用することを常に推奨します。こうすることで、JOIN するデータ量を最小限に抑えられます。以下の例では、2020 年以降の Java 関連の投稿に対するアップボート数を計算したいものとします。
左側に大きなテーブルを置いた素朴なクエリは、完了までに 56 秒かかります。
この結合の順序を変更することで、パフォーマンスが1.5秒まで劇的に改善されます:
左側のテーブルにフィルターを追加すると、実行時間はさらに短縮され、0.5秒になります。
前述のとおり、INNER JOIN をサブクエリに移動し、外側と内側の両方のクエリでフィルターを保持することで、このクエリをさらに改善できます。
JOIN アルゴリズムの選択
ClickHouse は、いくつかのJOIN アルゴリズムをサポートしています。これらのアルゴリズムは、一般的にメモリ使用量とパフォーマンスの間にトレードオフの関係があります。以下では、ClickHouse の JOIN アルゴリズムを、相対的なメモリ消費量と実行時間に基づいて概観します。
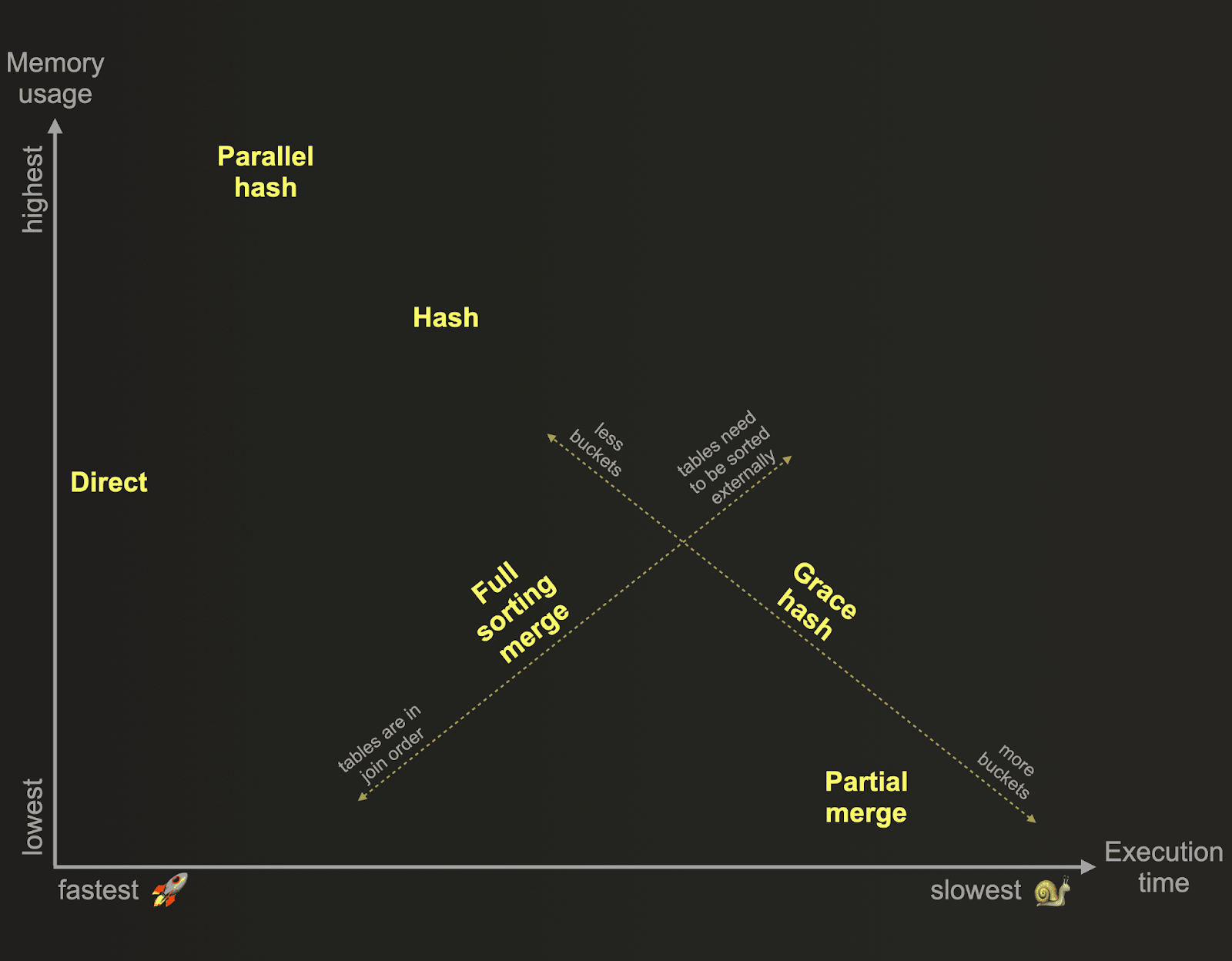
これらのアルゴリズムは、JOIN クエリがどのように計画および実行されるかを決定します。デフォルトでは、ClickHouse は使用される JOIN の種類と厳密さ、および結合対象テーブルのエンジンに基づいて、direct JOIN または hash JOIN アルゴリズムを使用します。また、ClickHouse を構成して、リソースの利用可能性と使用状況に応じて、実行時に使用する JOIN アルゴリズムを自動的に選択し動的に切り替えることもできます。join_algorithm=auto の場合、ClickHouse は最初に hash JOIN アルゴリズムを試し、そのアルゴリズムのメモリ制限を超えた場合には、その場でアルゴリズムを partial merge JOIN に切り替えます。どのアルゴリズムが選択されたかは、トレースログで確認できます。また ClickHouse では、join_algorithm 設定を通じて、ユーザーが希望する JOIN アルゴリズムを明示的に指定することも可能です。
各 JOIN アルゴリズムでサポートされる JOIN タイプを以下に示します。最適化を行う前に考慮してください。
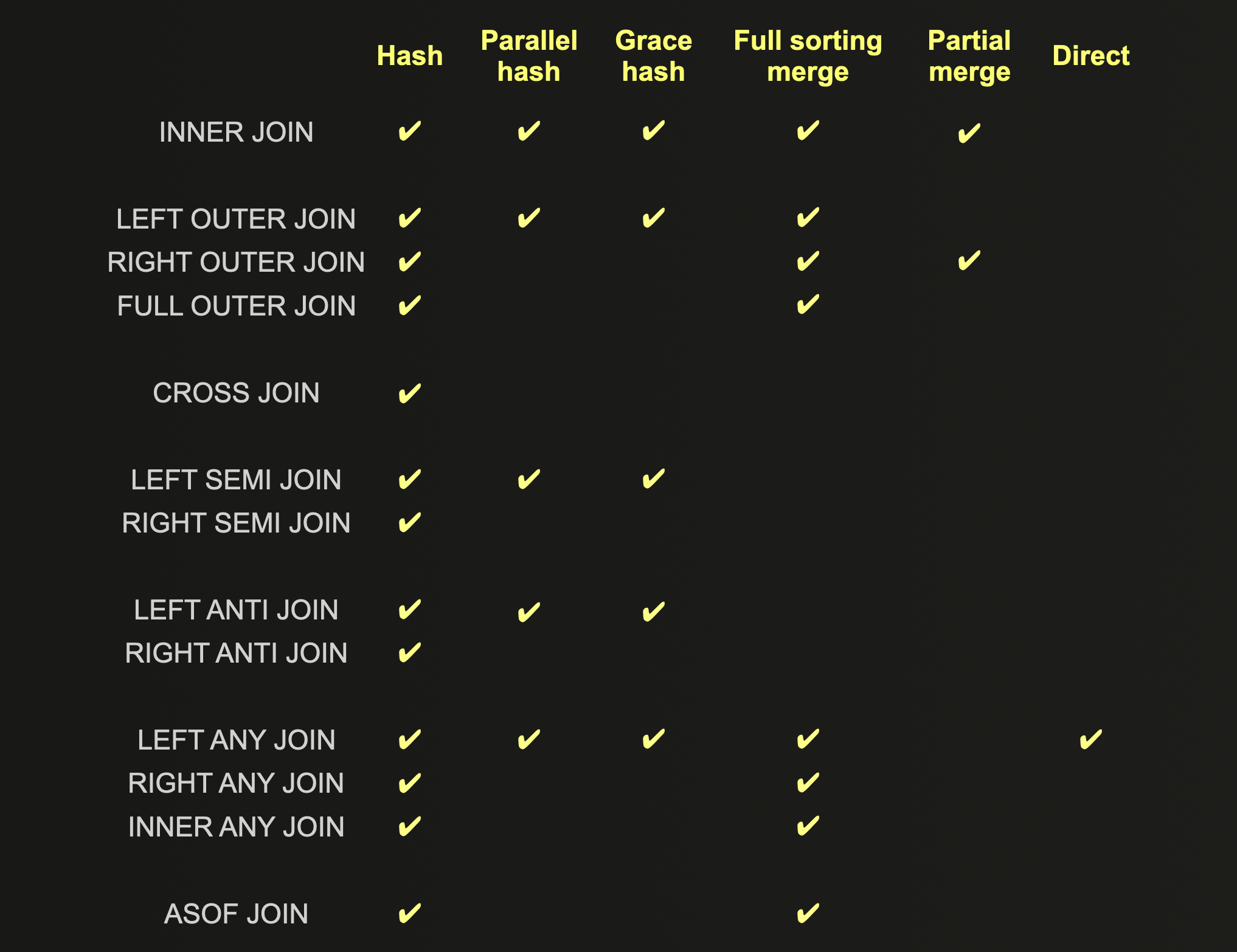
各 JOIN アルゴリズムの詳細な説明は、その長所・短所・スケーリング特性とともにこちらで確認できます。
適切な JOIN アルゴリズムの選択は、メモリ使用量とパフォーマンスのどちらを優先して最適化するかによって決まります。
JOIN のパフォーマンス最適化
主な最適化指標がパフォーマンスであり、JOIN をできるだけ高速に実行したい場合は、適切な JOIN アルゴリズムを選択するために次の意思決定ツリーを使用できます。
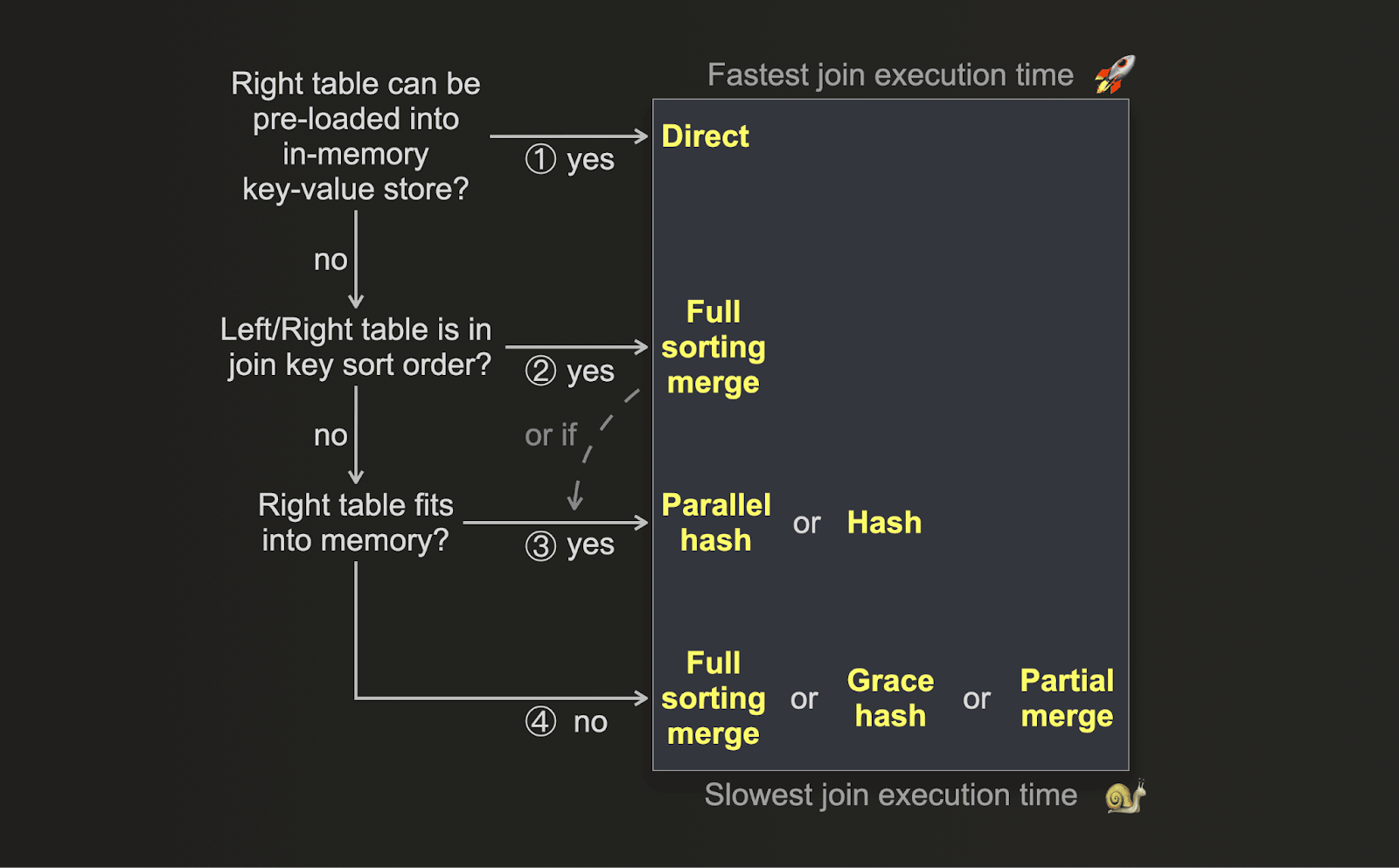
-
(1) 右側のテーブルのデータを、辞書などのインメモリ低レイテンシーなキー・バリュー型データ構造にあらかじめロードでき、JOIN キーが基盤となるキー・バリューストレージのキー属性と一致し、かつ
LEFT ANY JOINのセマンティクスで十分な場合は、direct join が適用可能で、最も高速なアプローチとなります。 -
(2) テーブルの 物理行順序 が JOIN キーのソート順序と一致している場合は、判断が分かれます。このケースでは、full sorting merge join はソートフェーズをスキップし、その結果、メモリ使用量が大幅に削減されるとともに、データサイズや JOIN キー値の分布によっては、いくつかのハッシュ JOIN アルゴリズムよりも高速に実行されます。
-
(3) 右側のテーブルが、parallel hash join の追加のメモリ使用量オーバーヘッドを考慮してもメモリに収まる場合は、このアルゴリズム、もしくは hash join のほうが高速になることがあります。これは、データサイズ、データ型、および JOIN キーカラムの値分布に依存します。
-
(4) 右側のテーブルがメモリに収まらない場合も、やはり状況により変わります。ClickHouse には、メモリ制約を受けない 3 つの JOIN アルゴリズムが用意されています。これら 3 つはいずれも一時的にデータをディスクにスピルします。full sorting merge join と partial merge join は、事前にデータをソートする必要があります。grace hash join は代わりにデータからハッシュテーブルを構築します。データ量、データ型、および JOIN キーカラムの値分布に応じて、データからハッシュテーブルを構築するほうがデータをソートするより高速となるシナリオもあれば、その逆もあります。
partial merge join は、大規模なテーブルを結合する際のメモリ使用量を最小化するよう最適化されていますが、その代償として JOIN の速度はかなり遅くなります。特に、左側テーブルの物理行順序が JOIN キーのソート順序と一致しない場合に顕著です。
grace hash join は、3 つのメモリ制約非依存 JOIN アルゴリズムの中で最も柔軟であり、grace_hash_join_initial_buckets 設定によってメモリ使用量と JOIN 速度のトレードオフをうまく制御できます。データ量に応じて、バケットの数が両アルゴリズムのメモリ使用量がおおむね揃うように選択されている場合には、grace hash が partial merge アルゴリズムより高速になることもあれば、遅くなることもあります。grace hash join のメモリ使用量が full sorting merge のメモリ使用量とおおむね揃うように設定されている場合、われわれのテストでは常に full sorting merge のほうが高速でした。
3 つのメモリ制約非依存アルゴリズムのうちどれが最速かは、データ量、データ型、および JOIN キーカラムの値分布によって決まります。どのアルゴリズムが最速かを判断するには、現実的なデータ量・データでベンチマークを実行するのが最善です。
メモリ使用量の最適化
最速の実行時間ではなくメモリ使用量の最小化を目的に結合を最適化したい場合は、代わりに次の決定木を使用できます。
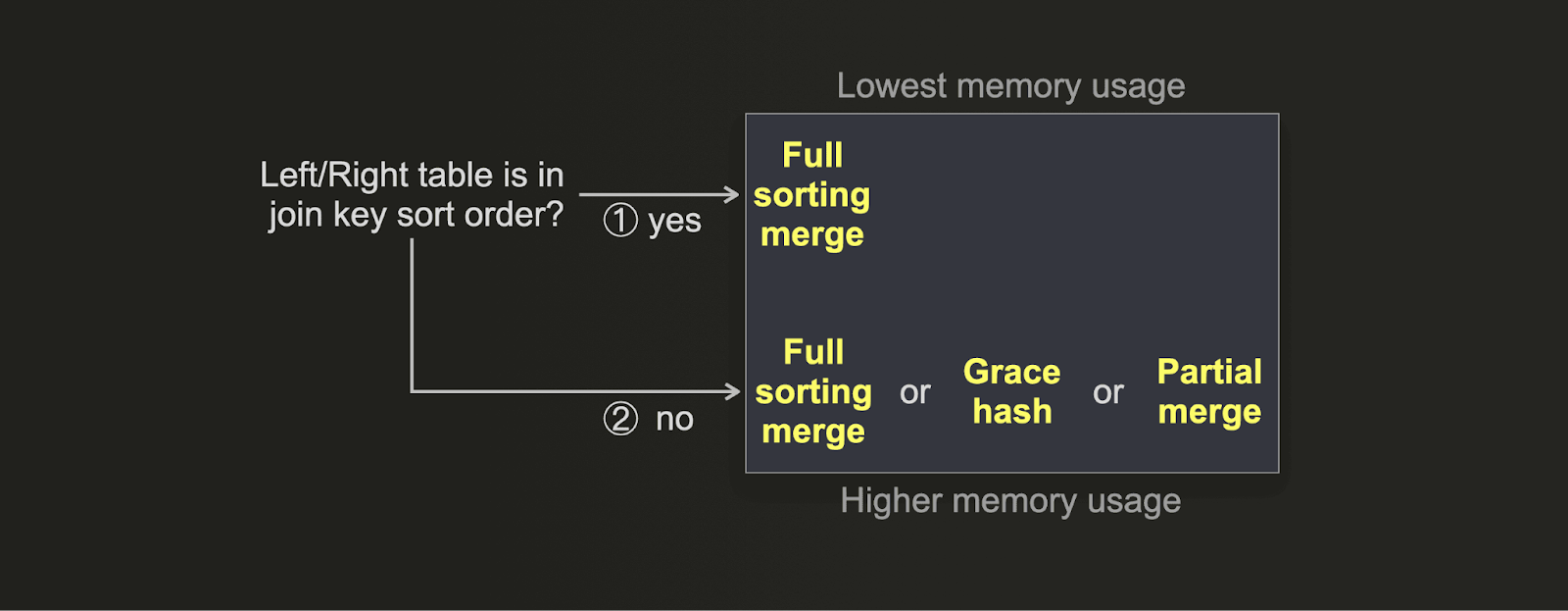
- (1) テーブルの物理行順序が結合キーのソート順序と一致している場合、full sorting merge join のメモリ使用量はこれ以上ないほど低く抑えられます。さらに、ソートフェーズが無効化されることで、結合速度も良好になります。
- (2) grace hash join は、結合速度を犠牲にして多数の bucket を設定することで、非常に低いメモリ使用量になるようにチューニングできます。partial merge join は、意図的に少量のメインメモリしか使用しません。外部ソートを有効にした full sorting merge join は(行順序がキーのソート順序と一致していないと仮定すると)、一般的に partial merge join より多くのメモリを使用しますが、その代わりに結合の実行時間が大幅に向上します。
上記の内容についてさらに詳しい情報が必要なユーザーには、次の ブログシリーズをお勧めします。
