ClickHouse へのデータ挿入
ClickHouse への挿入と OLTP データベースへの挿入の違い
OLAP(Online Analytical Processing)データベースである ClickHouse は、高いパフォーマンスとスケーラビリティに最適化されており、最大で 1 秒間に数百万行のデータを挿入できます。 これは、高度に並列化されたアーキテクチャと効率的なカラム指向圧縮の組み合わせによって実現されていますが、その代償として即時一貫性をある程度犠牲にしています。 より具体的には、ClickHouse は追記専用の操作に最適化されており、最終的な一貫性のみを保証します。
対照的に、Postgres のような OLTP データベースは、トランザクション処理における挿入に特化して最適化されており、完全な ACID 準拠によって強い一貫性と信頼性の保証を提供します。 PostgreSQL は、複数バージョン同時実行制御(MVCC: Multi-Version Concurrency Control)を用いて同時トランザクションを処理しており、これはデータの複数バージョンを維持することを伴います。 これらのトランザクションは、一度に扱う行数は少ない場合が多い一方で、一貫性・信頼性の保証に起因するオーバーヘッドが大きく、挿入性能を制約します。
高い挿入性能を実現しつつ強い一貫性保証も維持するためには、ClickHouse にデータを挿入する際に、以下で説明するシンプルなルールに従う必要があります。 これらのルールに従うことで、ユーザーが初めて ClickHouse を利用する際に、OLTP データベースで有効だった挿入戦略をそのまま再現しようとして直面しがちな問題を回避できます。
Insert のベストプラクティス
大きなバッチサイズで Insert する
デフォルトでは、ClickHouse に送られた各 Insert は、Insert で送信されたデータと、保存する必要があるその他のメタデータを含むストレージのパーツを、ClickHouse が即座に作成します。 したがって、少数の Insert に多くのデータを含めて送信する方が、多数の Insert に少量のデータを含めて送信する場合と比べて、必要な書き込み回数を減らすことができます。 一般的には、一度に最低 1,000 行、理想的には 10,000〜100,000 行程度の十分に大きなバッチでデータを挿入することを推奨します。 (詳細はこちらを参照)。
大きなバッチが不可能な場合は、後述の非同期 Insert を使用してください。
冪等なリトライのために一貫したバッチを確保する
デフォルトでは、ClickHouse への Insert は同期的かつ冪等です(つまり同じ Insert 操作を複数回実行しても、1 回だけ実行した場合と結果が同じになります)。 MergeTree エンジンファミリーのテーブルでは、ClickHouse はデフォルトで Insert を自動的に重複排除します。
これは、次のようなケースでも Insert が堅牢であることを意味します:
-
- データを受信したノードに問題がある場合、Insert クエリはタイムアウト(またはより具体的なエラーを返し)、応答を得られません。
-
- ノードによってデータが書き込まれたものの、ネットワークの中断によりクエリ送信元へ応答を返せない場合、送信側はタイムアウトかネットワークエラーを受け取ります。
クライアントの観点からは、(i) と (ii) を区別するのは難しい場合があります。しかし、どちらの場合でも、応答を受け取れていない Insert はすぐに再試行できます。 リトライされた Insert クエリが、同じ順序で同じデータを含んでいる限り、(応答が返らなかった)元の Insert が成功していた場合、ClickHouse はリトライされた Insert を自動的に無視します。
MergeTree テーブルまたは Distributed テーブルに Insert する
データがシャーディングされている場合には、MergeTree(または Replicated テーブル)に直接 Insert し、ノード群全体にリクエストを分散させ、internal_replication=true を設定することを推奨します。
これにより、ClickHouse が利用可能なレプリカシャードへデータをレプリケーションし、データの最終的な整合性が保証されます。
クライアント側での負荷分散が不便な場合、ユーザーはdistributed テーブル経由で Insert できます。この場合、書き込みはノード間に分散されます。同様に internal_replication=true を設定することを推奨します。
ただし、このアプローチでは、Distributed テーブルを持つノード上で一度ローカルに書き込み、その後シャードへ送信する必要があるため、若干パフォーマンスが低下する点には注意してください。
小さなバッチには非同期 Insert を使用する
クライアント側でのバッチ処理が現実的でないシナリオも存在します。たとえば、数百〜数千の単一用途エージェントがログ、メトリクス、トレースなどを送信するオブザーバビリティのユースケースです。 このようなシナリオでは、問題や異常をできるだけ早く検知するために、そのデータをリアルタイムに転送することが重要です。 さらに、監視対象システムでイベントのスパイクが発生するリスクがあり、オブザーバビリティデータをクライアント側でバッファリングしようとすると、大きなメモリスパイクやそれに関連する問題を引き起こす可能性があります。 大きなバッチを Insert できない場合は、非同期 Insertを使用して、バッチ処理を ClickHouse に委譲できます。
非同期 Insert では、データはまずバッファに Insert され、その後、次の図に示す 3 つのステップでデータベースストレージに書き込まれます:
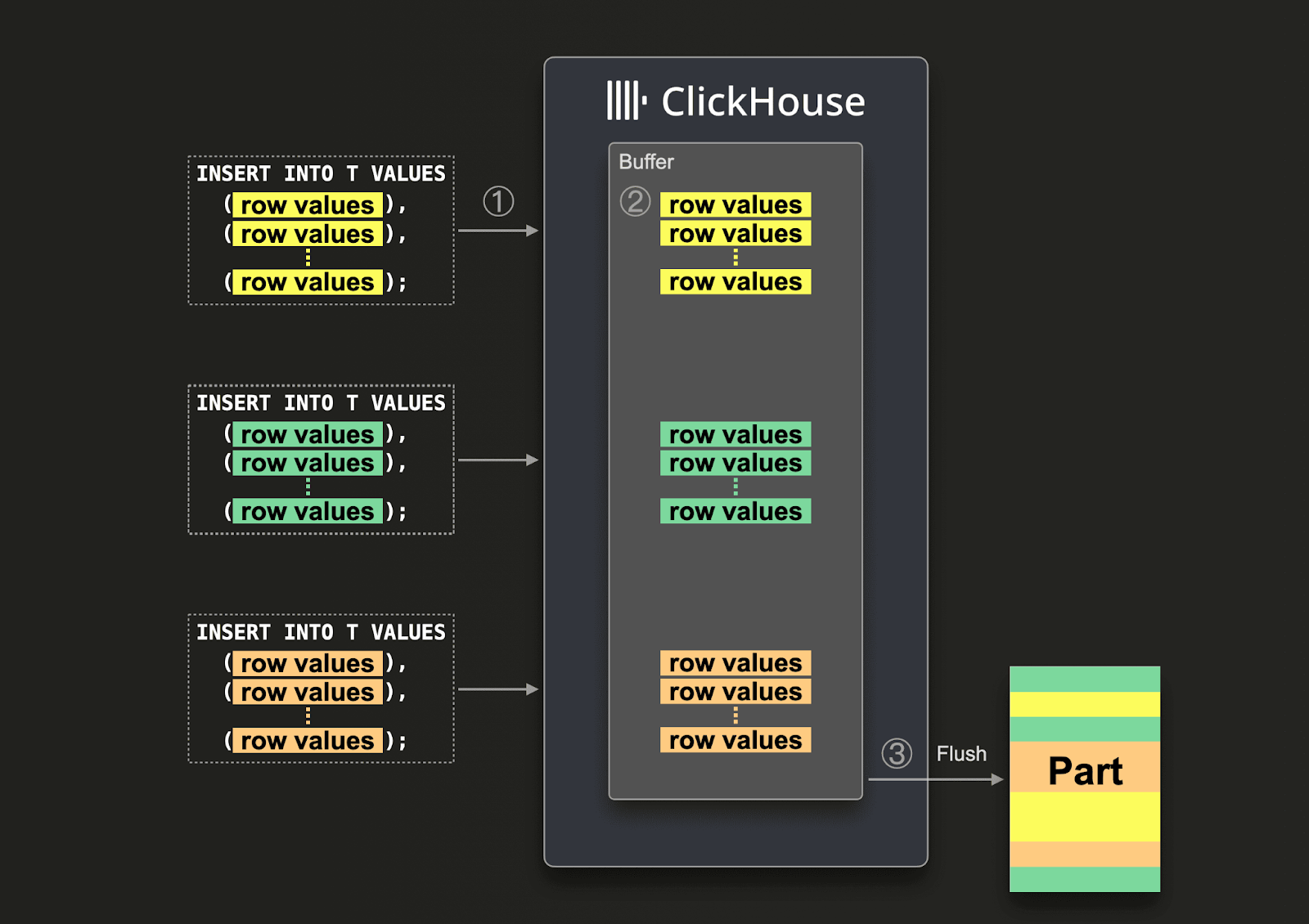
非同期 Insert が有効な場合、ClickHouse は次のように動作します:
(1) Insert クエリを非同期に受信します。
(2) クエリのデータを最初にインメモリバッファに書き込みます。
(3) 次回のバッファフラッシュが発生したタイミングでのみ、データをソートし、1 つのパーツとしてデータベースストレージに書き込みます。
バッファがフラッシュされる前であれば、同一または別のクライアントからの他の非同期 Insert クエリのデータもバッファに蓄積できます。 バッファフラッシュから作成されるパーツには、複数の非同期 Insert クエリのデータが含まれる可能性があります。 一般的に、これらの仕組みによって、データのバッチ処理はクライアント側からサーバー側(ClickHouse インスタンス)へと移されます。
公式の ClickHouse クライアントを使用する
ClickHouse には、主要なプログラミング言語向けのクライアントが用意されています。 これらはinsert が正しく実行されるよう最適化されており、非同期 Insert をネイティブにサポートします。たとえば Go クライアント のようにクライアント側で直接サポートする場合や、クエリ、ユーザー、接続レベルの設定で有効化した場合に間接的にサポートするケースがあります。
利用可能な ClickHouse クライアントおよびドライバの一覧は、Clients and Drivers を参照してください。
ネイティブフォーマットを優先する
ClickHouse は、インサート時(およびクエリ時)に多くの入力フォーマットをサポートします。 これは OLTP データベースとの大きな違いであり、テーブル関数やディスク上のファイルからデータをロードする機能と組み合わせることで、外部ソースからのデータロードを大幅に容易にします。 これらのフォーマットは、アドホックなデータロードやデータエンジニアリング作業に理想的です。
最適なインサート性能を求めるアプリケーションでは、Native フォーマットでインサートすることを推奨します。 これはほとんどのクライアント(Go や Python など)でサポートされており、このフォーマットはすでにカラム指向であるため、サーバー側の処理量を最小限に抑えられます。 その結果、データをカラム指向フォーマットに変換する責務はクライアント側に置かれます。これはインサートを効率的にスケールさせるうえで重要です。
代わりに、行フォーマットを好む場合は RowBinary フォーマット(Java クライアントが使用)を利用できます。これは一般的に Native フォーマットより書きやすいフォーマットです。 これは、JSON などの他の行フォーマットと比べて、圧縮率、ネットワークオーバーヘッド、サーバー側での処理の観点から、より効率的です。 書き込みスループットがそれほど高くなく、迅速な統合を望むユーザーは、JSONEachRow フォーマットの利用を検討できます。ただし、このフォーマットでは ClickHouse 側でのパースに CPU オーバーヘッドが発生することに注意してください。
HTTP インターフェースを使用する
多くの従来型データベースとは異なり、ClickHouse は HTTP インターフェースをサポートしています。 ユーザーは、上記のいずれかのフォーマットを使用して、データのインサートとクエリの両方にこれを利用できます。 これは、トラフィックをロードバランサーで容易に切り替えられるため、ClickHouse のネイティブプロトコルより好まれることが多いです。 ネイティブプロトコルのほうがわずかにオーバーヘッドが少ないため、インサート性能に小さな差が生じることが予想されます。 既存のクライアントは、これらいずれかのプロトコル(場合によっては両方、例: Go クライアント)を使用します。 ネイティブプロトコルでは、クエリの進捗を容易に追跡できます。
詳細については HTTP Interface を参照してください。
基本例
ClickHouse では、おなじみの INSERT INTO TABLE コマンドを使用できます。入門ガイド「Creating Tables in ClickHouse」で作成したテーブルにデータを挿入してみましょう。
正常に動作したことを確認するため、次の SELECT クエリを実行します。
これにより、次の結果が返されます:
Postgres からのデータロード
Postgres からデータをロードするには、次の方法を利用できます。
ClickPipes。PostgreSQL データベースのレプリケーション専用に設計された ETL ツールです。次の両方の形態で利用できます。- ClickHouse Cloud - ClickPipes の マネージドインジェストサービス として利用できます。
- セルフマネージド - PeerDB オープンソースプロジェクト を利用します。
- PostgreSQL table engine を使用して、前の例で示したようにデータを直接読み取る方法。この方法は、既知のウォーターマーク(例: タイムスタンプ)に基づくバッチレプリケーションで十分な場合や、一度限りの移行の場合に一般的に適しています。このアプローチは、数千万行規模までスケールできます。より大きなデータセットを移行したい場合は、データをチャンクに分割し、それぞれを処理する複数のリクエストに分けることを検討してください。各チャンクについてステージングテーブルを用意し、そのパーティションを最終テーブルに移動する前にロードできます。これにより、失敗したリクエストを再試行しやすくなります。この一括ロード戦略の詳細については、こちらを参照してください。
- PostgreSQL からデータを CSV 形式でエクスポートすることもできます。エクスポートした CSV は、ローカルファイルから、またはテーブル関数を使ってオブジェクトストレージ経由で ClickHouse に挿入できます。
大きなデータセットの挿入について支援が必要な場合や、ClickHouse Cloud にデータをインポートする際にエラーが発生した場合は、support@clickhouse.com までご連絡ください。サポートいたします。
コマンドラインからデータを挿入する
前提条件
- ClickHouse をインストール済みであること
clickhouse-serverが動作していることwget、zcat、curlが利用できるターミナルにアクセスできること
この例では、コマンドラインから clickhouse-client をバッチモードで使用して、CSV ファイルを ClickHouse に挿入する方法を説明します。clickhouse-client をバッチモードで使ってコマンドライン経由でデータを挿入する詳細および他の例については、"Batch mode" を参照してください。
この例では Hacker News データセット を使用します。このデータセットには Hacker News のデータが 2,800 万行含まれています。
CSV をダウンロードする
次のコマンドを実行して、パブリックな S3 バケットからデータセットの CSV 版をダウンロードします:
この圧縮ファイルは 4.6GB、2,800 万行あり、ダウンロードには 5〜10 分程度かかるはずです。
テーブルを作成する
clickhouse-server が動作していれば、次のスキーマを持つ空のテーブルを、clickhouse-client をバッチモードで使ってコマンドラインから直接作成できます:
エラーが出なければ、テーブルは正常に作成されています。上記のコマンドでは、ヒアドキュメントの区切り文字 (_EOF) をシングルクォートで囲むことで、変数展開などを防いでいます。シングルクォートがない場合、カラム名を囲んでいるバッククォートをエスケープする必要があります。
コマンドラインからデータを挿入する
次に、以下のコマンドを実行して、先ほどダウンロードしたファイルからテーブルにデータを挿入します:
データは圧縮されているため、まず gzip や zcat などのツールを使ってファイルを解凍し、その解凍済みデータを、適切な INSERT ステートメントと FORMAT を指定して clickhouse-client にパイプする必要があります。
clickhouse-client を対話モードで使ってデータを挿入する場合、COMPRESSION 句を使用して、挿入時の解凍処理を ClickHouse に任せることができます。ClickHouse はファイル拡張子から圧縮形式を自動検出できますが、明示的に指定することも可能です。
この場合、挿入クエリは次のようになります:
データの挿入が完了したら、次のコマンドを実行して hackernews テーブル内の行数を確認できます:
curl を用いてコマンドラインからデータを挿入する
前の手順では、まず wget を使って CSV ファイルをローカルマシンにダウンロードしました。リモート URL から、単一のコマンドでデータを直接挿入することも可能です。
次のコマンドを実行して、ローカルマシンへのダウンロードという中間ステップなしに再度挿入できるよう、hackernews テーブルのデータを削除します:
次に、以下を実行します:
その後、先ほどと同じコマンドを実行して、データが再度挿入されたことを確認できます:
