このセクションでは、アナライザー、クエリプロファイリング、Nullable列の回避などの様々なパフォーマンスと最適化テクニックを使用して、ClickHouseのクエリパフォーマンスを向上させる方法を一般的なシナリオを通じて説明します。
パフォーマンス最適化について考える最適なタイミングは、ClickHouseに初めてデータを取り込む前にデータスキーマをセットアップする時です。
しかし正直なところ、データがどれだけ成長するか、どのようなタイプのクエリが実行されるかを予測するのは困難です。
改善したいクエリがいくつかある既存のデプロイメントがある場合、最初のステップは、それらのクエリがどのようにパフォーマンスを発揮し、なぜあるクエリは数ミリ秒で実行されるのに他のクエリはより長く時間がかかるのかを理解することです。
ClickHouseには、クエリがどのように実行されているか、実行のために消費されるリソースを理解するための豊富なツールセットがあります。
このセクションでは、これらのツールとその使い方を見ていきます。
一般的な考慮事項
クエリパフォーマンスを理解するために、クエリが実行される際にClickHouseで何が起こるかを見てみましょう。
以下の部分は意図的に簡略化されており、いくつかのショートカットを取っています。ここでの目的は、詳細で溺れさせることではなく、基本的な概念を素早く理解してもらうことです。詳細については、クエリアナライザーについて読むことができます。
非常に高レベルの観点から、ClickHouseがクエリを実行する際、次のようなことが起こります:
クエリが解析および分析され、一般的なクエリ実行計画が作成されます。
クエリ実行計画が最適化され、不要なデータが削除され、クエリプランからクエリパイプラインが構築されます。
データが並列に読み取られ、処理されます。これは、ClickHouseがフィルタリング、集計、ソートなどのクエリ操作を実際に実行する段階です。
結果がマージ、ソートされ、クライアントに送信される前に最終結果にフォーマットされます。
実際には、多くの最適化が行われており、このガイドでそれらについてもう少し詳しく説明しますが、今のところ、これらの主要な概念により、ClickHouseがクエリを実行する際に舞台裏で何が起こっているかについて良い理解が得られます。
このハイレベルな理解により、ClickHouseが提供するツールと、クエリパフォーマンスに影響を与えるメトリクスを追跡するためにそれらをどのように使用できるかを調べてみましょう。
データセット
クエリパフォーマンスへのアプローチを説明するために、実際の例を使用します。
NYC Taxiデータセットを使用しましょう。これには、NYCのタクシー乗車データが含まれています。まず、最適化なしでNYC taxiデータセットを取り込むことから始めます。
以下は、テーブルを作成し、S3バケットからデータを挿入するコマンドです。意図的に最適化されていないデータからスキーマを推論していることに注意してください。
-- Create table with inferred schema
CREATE TABLE trips_small_inferred
ORDER BY () EMPTY
AS SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
-- Insert data into table with inferred schema
INSERT INTO trips_small_inferred
SELECT *
FROM s3Cluster
('default','https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
データから自動的に推論されたテーブルスキーマを見てみましょう。
--- Display inferred table schema
SHOW CREATE TABLE trips_small_inferred
Query id: d97361fd-c050-478e-b831-369469f0784d
CREATE TABLE nyc_taxi.trips_small_inferred
(
`vendor_id` Nullable(String),
`pickup_datetime` Nullable(DateTime64(6, 'UTC')),
`dropoff_datetime` Nullable(DateTime64(6, 'UTC')),
`passenger_count` Nullable(Int64),
`trip_distance` Nullable(Float64),
`ratecode_id` Nullable(String),
`pickup_location_id` Nullable(String),
`dropoff_location_id` Nullable(String),
`payment_type` Nullable(Int64),
`fare_amount` Nullable(Float64),
`extra` Nullable(Float64),
`mta_tax` Nullable(Float64),
`tip_amount` Nullable(Float64),
`tolls_amount` Nullable(Float64),
`total_amount` Nullable(Float64)
)
ORDER BY tuple()
遅いクエリを見つける
クエリログ
デフォルトでは、ClickHouseはクエリログで実行された各クエリに関する情報を収集し、ログに記録します。このデータはsystem.query_logテーブルに保存されます。
実行された各クエリに対して、ClickHouseはクエリ実行時間、読み取られた行数、CPU、メモリ使用量、ファイルシステムキャッシュヒットなどのリソース使用量などの統計をログに記録します。
したがって、クエリログは遅いクエリを調査する際に開始するのに良い場所です。長時間実行されるクエリを簡単に見つけ、それぞれのリソース使用情報を表示できます。
NYC taxiデータセットで実行時間が長い上位5つのクエリを見つけましょう。
-- Find top 5 long running queries from nyc_taxi database in the last 1 hour
SELECT
type,
event_time,
query_duration_ms,
query,
read_rows,
tables
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (event_time >= (now() - toIntervalMinute(60))) AND type='QueryFinish'
ORDER BY query_duration_ms DESC
LIMIT 5
FORMAT VERTICAL
Query id: e3d48c9f-32bb-49a4-8303-080f59ed1835
Row 1:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:36
query_duration_ms: 2967
query: WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 2:
──────
type: QueryFinish
event_time: 2024-11-27 11:11:33
query_duration_ms: 2026
query: SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 3:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:17
query_duration_ms: 1860
query: SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 4:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:31
query_duration_ms: 690
query: SELECT avg(total_amount) FROM nyc_taxi.trips_small_inferred WHERE trip_distance > 5
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 5:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:44
query_duration_ms: 634
query: SELECT
vendor_id,
avg(total_amount),
avg(trip_distance),
FROM
nyc_taxi.trips_small_inferred
GROUP BY vendor_id
ORDER BY 1 DESC
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
query_duration_msフィールドは、その特定のクエリの実行にかかった時間を示します。クエリログからの結果を見ると、最初のクエリの実行に2967msかかっており、これは改善できる可能性があります。
また、最もメモリやCPUを消費しているクエリを調べることで、システムに負荷をかけているクエリを知りたい場合もあるでしょう。
-- Top queries by memory usage
SELECT
type,
event_time,
query_id,
formatReadableSize(memory_usage) AS memory,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')] AS userCPU,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')] AS systemCPU,
(ProfileEvents['CachedReadBufferReadFromCacheMicroseconds']) / 1000000 AS FromCacheSeconds,
(ProfileEvents['CachedReadBufferReadFromSourceMicroseconds']) / 1000000 AS FromSourceSeconds,
normalized_query_hash
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (type='QueryFinish') AND ((event_time >= (now() - toIntervalDay(2))) AND (event_time <= now())) AND (user NOT ILIKE '%internal%')
ORDER BY memory_usage DESC
LIMIT 30
見つけた実行時間の長いクエリを分離して、数回再実行してレスポンスタイムを理解しましょう。
この時点で、再現性を向上させるためにenable_filesystem_cache設定を0に設定してファイルシステムキャッシュをオフにすることが重要です。
-- Disable filesystem cache
set enable_filesystem_cache = 0;
-- Run query 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
----
1 row in set. Elapsed: 1.699 sec. Processed 329.04 million rows, 8.88 GB (193.72 million rows/s., 5.23 GB/s.)
Peak memory usage: 440.24 MiB.
-- Run query 2
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
---
4 rows in set. Elapsed: 1.419 sec. Processed 329.04 million rows, 5.72 GB (231.86 million rows/s., 4.03 GB/s.)
Peak memory usage: 546.75 MiB.
-- Run query 3
SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
---
1 row in set. Elapsed: 1.414 sec. Processed 329.04 million rows, 8.88 GB (232.63 million rows/s., 6.28 GB/s.)
Peak memory usage: 451.53 MiB.
読みやすくするためにテーブルにまとめます。
| 名前 | 経過時間 | 処理行数 | ピークメモリ |
|---|
| クエリ1 | 1.699 sec | 329.04 million | 440.24 MiB |
| クエリ2 | 1.419 sec | 329.04 million | 546.75 MiB |
| クエリ3 | 1.414 sec | 329.04 million | 451.53 MiB |
クエリが何を達成しているかを少し理解しましょう。
- クエリ1は、平均速度が時速30マイルを超える乗車の距離分布を計算します。
- クエリ2は、週ごとの乗車数と平均コストを見つけます。
- クエリ3は、データセット内の各乗車の平均時間を計算します。
これらのクエリはいずれも非常に複雑な処理を行っていませんが、クエリが実行されるたびにその場で乗車時間を計算する最初のクエリを除いて、各クエリの実行には1秒以上かかります。これは、ClickHouseの世界では非常に長い時間です。また、これらのクエリのメモリ使用量にも注目できます。各クエリで約400Mbはかなり多くのメモリです。また、各クエリが同じ行数(つまり329.04 million)を読み取っているように見えます。このテーブルに何行あるか簡単に確認しましょう。
-- Count number of rows in table
SELECT count()
FROM nyc_taxi.trips_small_inferred
Query id: 733372c5-deaf-4719-94e3-261540933b23
┌───count()─┐
1. │ 329044175 │ -- 329.04 million
└───────────┘
テーブルには3.2904億行が含まれているため、各クエリはテーブルをフルスキャンしています。
Explain文
実行時間の長いクエリがいくつか見つかったので、それらがどのように実行されるかを理解しましょう。このために、ClickHouseはEXPLAIN文コマンドをサポートしています。これは、実際にクエリを実行せずに、すべてのクエリ実行段階の非常に詳細なビューを提供する非常に便利なツールです。ClickHouseの専門家でない人にとっては圧倒されるかもしれませんが、クエリがどのように実行されるかについての洞察を得るための必須ツールです。
ドキュメントには、EXPLAIN文とは何か、そしてクエリ実行を分析するためにそれを使用する方法についての詳細なガイドがあります。このガイドで述べられていることを繰り返すのではなく、クエリ実行パフォーマンスのボトルネックを見つけるのに役立ついくつかのコマンドに焦点を当てましょう。
Explain indexes = 1
クエリプランを検査するためにEXPLAIN indexes = 1から始めましょう。クエリプランは、クエリがどのように実行されるかを示すツリーです。そこで、クエリの句がどの順序で実行されるかを確認できます。EXPLAIN文によって返されるクエリプランは、下から上に読むことができます。
実行時間の長いクエリの最初のものを使用してみましょう。
EXPLAIN indexes = 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: f35c412a-edda-4089-914b-fa1622d69868
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Filter (WHERE) │
5. │ ReadFromMergeTree (nyc_taxi.trips_small_inferred) │
└─────────────────────────────────────────────────────┘
出力は簡単です。クエリはnyc_taxi.trips_small_inferredテーブルからデータを読み取ることから始まります。次に、WHERE句が適用されて、計算された値に基づいて行がフィルタリングされます。フィルタリングされたデータは集計のために準備され、分位数が計算されます。最後に、結果がソートされて出力されます。
ここで、プライマリキーが使用されていないことに注意できます。これは、テーブルを作成した際に何も定義しなかったため、理にかなっています。その結果、ClickHouseはクエリのためにテーブルのフルスキャンを実行しています。
Explain Pipeline
EXPLAIN Pipelineは、クエリの具体的な実行戦略を示します。そこで、ClickHouseが以前に見た一般的なクエリプランを実際にどのように実行したかを確認できます。
EXPLAIN PIPELINE
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: c7e11e7b-d970-4e35-936c-ecfc24e3b879
┌─explain─────────────────────────────────────────────────────────────────────────────┐
1. │ (Expression) │
2. │ ExpressionTransform × 59 │
3. │ (Aggregating) │
4. │ Resize 59 → 59 │
5. │ AggregatingTransform × 59 │
6. │ StrictResize 59 → 59 │
7. │ (Expression) │
8. │ ExpressionTransform × 59 │
9. │ (Filter) │
10. │ FilterTransform × 59 │
11. │ (ReadFromMergeTree) │
12. │ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) × 59 0 → 1 │
ここでは、クエリの実行に 59 個のスレッドが使用されていることが分かります。これは高い並列度を示しており、より小さなマシンであればより長い時間がかかるクエリの実行を高速化します。多数のスレッドが並列に実行されていることが、クエリによるメモリ消費量の多さを説明できます。
理想的には、すべての低速なクエリについて同様の調査を行い、不要に複雑なクエリプランを特定するとともに、各クエリが読み取る行数と消費するリソースを把握するべきです。
方法論
本番環境のデプロイメントで問題のあるクエリを特定するのは難しい場合があります。おそらく、ClickHouseデプロイメントで任意の時点で多数のクエリが実行されているためです。
どのユーザー、データベース、またはテーブルに問題があるかわかっている場合は、system.query_logsのuser、tables、またはdatabasesフィールドを使用して検索を絞り込むことができます。
最適化したいクエリを特定したら、それらを最適化するための作業を開始できます。この段階で開発者がよく犯す間違いは、複数のことを同時に変更し、アドホック実験を実行して、通常は混合結果に終わるが、より重要なことに、クエリを速くした原因についての良い理解を逃してしまうことです。
クエリの最適化には構造が必要です。高度なベンチマークについて話しているのではありませんが、変更がクエリパフォーマンスにどのように影響するかを理解するための簡単なプロセスを用意することは大いに役立ちます。
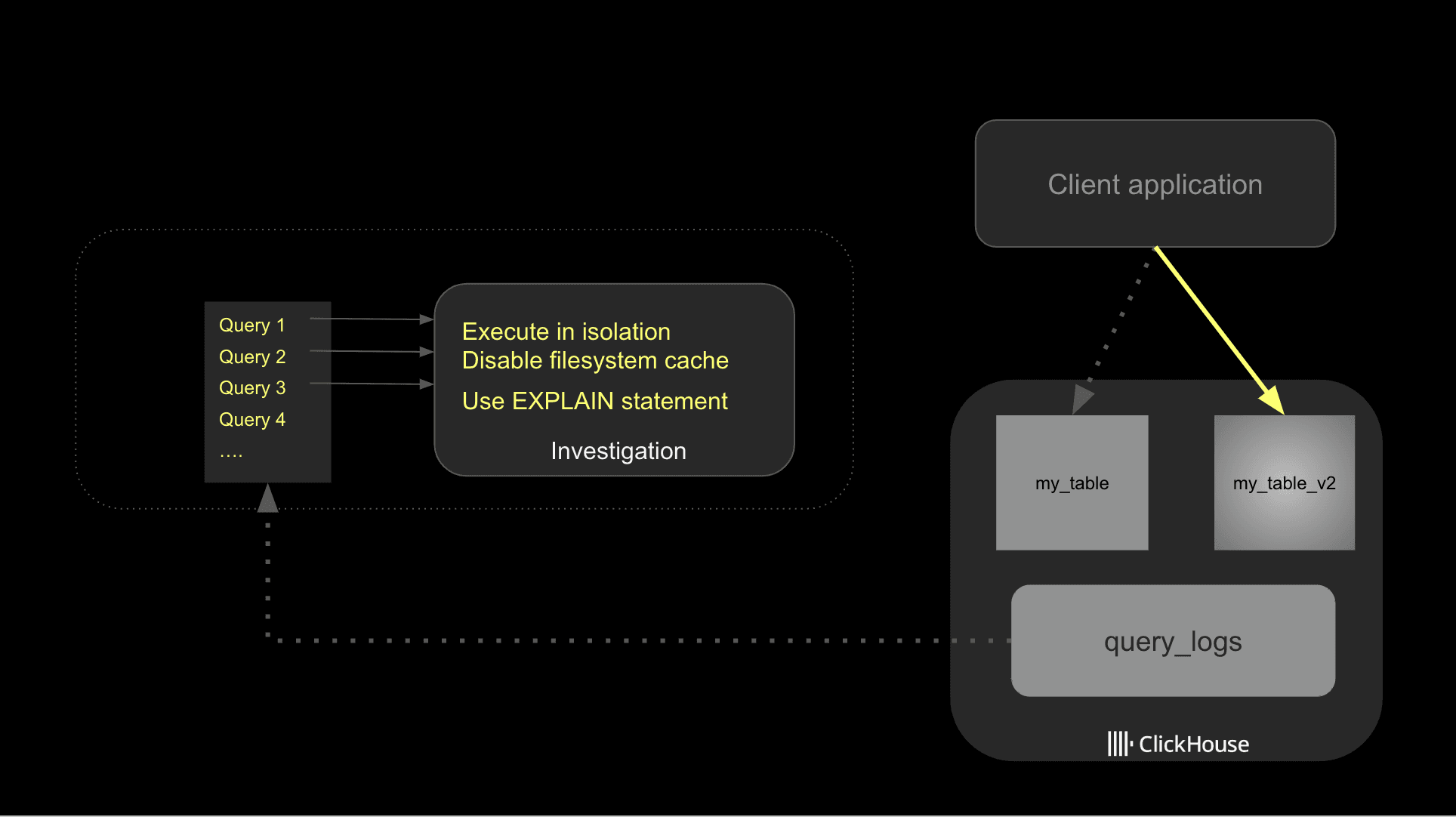
まず、クエリログから遅いクエリを特定し、次に潜在的な改善を分離して調査します。クエリをテストする際は、必ずファイルシステムキャッシュを無効にしてください。
ClickHouseは、さまざまな段階でクエリパフォーマンスを高速化するためにキャッシングを活用します。これはクエリパフォーマンスには良いですが、トラブルシューティング中には、潜在的なI/Oボトルネックや不適切なテーブルスキーマを隠す可能性があります。このため、テスト中はファイルシステムキャッシュをオフにすることをお勧めします。本番環境のセットアップでは必ず有効にしてください。
潜在的な最適化を特定したら、パフォーマンスへの影響をより適切に追跡するために、それらを1つずつ実装することをお勧めします。以下は、一般的なアプローチを説明する図です。
最後に、外れ値には注意してください。ユーザーがアドホックで高価なクエリを試したか、別の理由でシステムがストレス下にあったために、クエリが遅く実行されることは非常に一般的です。normalized_query_hashフィールドでグループ化して、定期的に実行されている高価なクエリを特定できます。これらはおそらく調査したいものです。
基本的な最適化
テストするフレームワークができたので、最適化を開始できます。
開始するのに最適な場所は、データがどのように保存されているかを調べることです。どのデータベースでも同様に、読み取るデータが少ないほど、クエリは速く実行されます。
データの取り込み方法によっては、ClickHouseの機能を活用して、取り込まれたデータに基づいてテーブルスキーマを推論した可能性があります。これは開始するには非常に実用的ですが、クエリパフォーマンスを最適化したい場合は、ユースケースに最適に適合するようにデータスキーマを確認する必要があります。
Nullable
ベストプラクティスドキュメントで説明されているように、可能な限りnullable列を避けてください。データ取り込みメカニズムがより柔軟になるため、頻繁に使用したくなりますが、追加の列を毎回処理する必要があるため、パフォーマンスに悪影響を及ぼします。
NULL値を持つ行をカウントするSQLクエリを実行すると、実際にNullable値が必要なテーブルの列を簡単に明らかにできます。
-- Find non-null values columns
SELECT
countIf(vendor_id IS NULL) AS vendor_id_nulls,
countIf(pickup_datetime IS NULL) AS pickup_datetime_nulls,
countIf(dropoff_datetime IS NULL) AS dropoff_datetime_nulls,
countIf(passenger_count IS NULL) AS passenger_count_nulls,
countIf(trip_distance IS NULL) AS trip_distance_nulls,
countIf(fare_amount IS NULL) AS fare_amount_nulls,
countIf(mta_tax IS NULL) AS mta_tax_nulls,
countIf(tip_amount IS NULL) AS tip_amount_nulls,
countIf(tolls_amount IS NULL) AS tolls_amount_nulls,
countIf(total_amount IS NULL) AS total_amount_nulls,
countIf(payment_type IS NULL) AS payment_type_nulls,
countIf(pickup_location_id IS NULL) AS pickup_location_id_nulls,
countIf(dropoff_location_id IS NULL) AS dropoff_location_id_nulls
FROM trips_small_inferred
FORMAT VERTICAL
Query id: 4a70fc5b-2501-41c8-813c-45ce241d85ae
Row 1:
──────
vendor_id_nulls: 0
pickup_datetime_nulls: 0
dropoff_datetime_nulls: 0
passenger_count_nulls: 0
trip_distance_nulls: 0
fare_amount_nulls: 0
mta_tax_nulls: 137946731
tip_amount_nulls: 0
tolls_amount_nulls: 0
total_amount_nulls: 0
payment_type_nulls: 69305
pickup_location_id_nulls: 0
dropoff_location_id_nulls: 0
null値を持つ列はmta_taxとpayment_typeの2つだけです。残りのフィールドはNullable列を使用すべきではありません。
Low cardinality
文字列に適用する簡単な最適化は、LowCardinalityデータ型を最大限に活用することです。lowcardinalityドキュメントで説明されているように、ClickHouseはLowCardinality列に辞書コーディングを適用し、クエリパフォーマンスを大幅に向上させます。
LowCardinalityの良い候補である列を決定するための簡単な経験則は、10,000未満のユニーク値を持つ列は完璧な候補であるということです。
次のSQLクエリを使用して、ユニーク値の数が少ない列を見つけることができます。
-- Identify low cardinality columns
SELECT
uniq(ratecode_id),
uniq(pickup_location_id),
uniq(dropoff_location_id),
uniq(vendor_id)
FROM trips_small_inferred
FORMAT VERTICAL
Query id: d502c6a1-c9bc-4415-9d86-5de74dd6d932
Row 1:
──────
uniq(ratecode_id): 6
uniq(pickup_location_id): 260
uniq(dropoff_location_id): 260
uniq(vendor_id): 3
カーディナリティが低いため、これらの4つの列、ratecode_id、pickup_location_id、dropoff_location_id、vendor_idは、LowCardinalityフィールドタイプの良い候補です。
データ型の最適化
ClickHouse は多数のデータ型をサポートしています。パフォーマンスを最適化し、ディスク上のデータの保存容量を削減するために、ユースケースを満たす範囲で可能な限り小さいデータ型を選択してください。
数値型については、データセット内の min/max 値を確認し、現在の精度(桁数や範囲)がデータセットの実態に合っているかどうかを検証できます。
-- Find min/max values for the payment_type field
SELECT
min(payment_type),max(payment_type),
min(passenger_count), max(passenger_count)
FROM trips_small_inferred
Query id: 4306a8e1-2a9c-4b06-97b4-4d902d2233eb
┌─min(payment_type)─┬─max(payment_type)─┐
1. │ 1 │ 4 │
└───────────────────┴───────────────────┘
日付の場合、データセットに一致し、実行を計画しているクエリに最適な精度を選択する必要があります。
最適化の適用
最適化されたスキーマを使用する新しいテーブルを作成し、データを再取り込みしましょう。
-- Create table with optimized data
CREATE TABLE trips_small_no_pk
(
`vendor_id` LowCardinality(String),
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` LowCardinality(String),
`dropoff_location_id` LowCardinality(String),
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
ORDER BY tuple();
-- Insert the data
INSERT INTO trips_small_no_pk SELECT * FROM trips_small_inferred
改善を確認するために、新しいテーブルを使用して再度クエリを実行します。
| 名前 | 実行1 - 経過時間 | 経過時間 | 処理行数 | ピークメモリ |
|---|
| クエリ1 | 1.699 sec | 1.353 sec | 329.04 million | 337.12 MiB |
| クエリ2 | 1.419 sec | 1.171 sec | 329.04 million | 531.09 MiB |
| クエリ3 | 1.414 sec | 1.188 sec | 329.04 million | 265.05 MiB |
クエリ時間とメモリ使用量の両方でいくつかの改善が見られます。データスキーマの最適化のおかげで、データを表す総データ量を削減し、メモリ消費の改善と処理時間の短縮につながりました。
テーブルのサイズをチェックして違いを見てみましょう。
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
sum(rows) AS rows
FROM system.parts
WHERE (active = 1) AND ((`table` = 'trips_small_no_pk') OR (`table` = 'trips_small_inferred'))
GROUP BY
database,
`table`
ORDER BY size DESC
Query id: 72b5eb1c-ff33-4fdb-9d29-dd076ac6f532
┌─table────────────────┬─compressed─┬─uncompressed─┬──────rows─┐
1. │ trips_small_inferred │ 7.38 GiB │ 37.41 GiB │ 329044175 │
2. │ trips_small_no_pk │ 4.89 GiB │ 15.31 GiB │ 329044175 │
└──────────────────────┴────────────┴──────────────┴───────────┘
新しいテーブルは以前のテーブルよりもかなり小さくなっています。テーブルのディスクスペースが約34%削減されています(7.38 GiB vs 4.89 GiB)。
プライマリキーの重要性
ClickHouseのプライマリキーは、ほとんどの従来のデータベースシステムとは異なる働きをします。これらのシステムでは、プライマリキーは一意性とデータ整合性を強制します。重複するプライマリキー値を挿入しようとすると拒否され、通常、高速検索のためにB-treeまたはハッシュベースのインデックスが作成されます。
ClickHouseでは、プライマリキーの目的は異なります。一意性を強制したり、データ整合性を助けたりしません。代わりに、クエリパフォーマンスを最適化するように設計されています。プライマリキーは、データがディスク上に保存される順序を定義し、各グラニュールの最初の行へのポインタを保存するスパースインデックスとして実装されています。
ClickHouseのグラニュールは、クエリ実行中に読み取られるデータの最小単位です。これらには、index_granularityによって決定される固定数の行(デフォルト値は8192行)まで含まれます。グラニュールは連続して保存され、プライマリキーでソートされます。
良いプライマリキーのセットを選択することはパフォーマンスにとって重要であり、実際には、特定のクエリセットを高速化するために、異なるテーブルに同じデータを保存し、異なるプライマリキーのセットを使用することが一般的です。
ProjectionやMaterialized viewなど、ClickHouseがサポートする他のオプションを使用すると、同じデータに異なるプライマリキーのセットを使用できます。このブログシリーズの第2部では、これについて詳しく説明します。
プライマリキーの選択
正しいプライマリキーのセットを選択することは複雑なトピックであり、最適な組み合わせを見つけるためにはトレードオフと実験が必要になる場合があります。
今のところ、以下のシンプルなプラクティスに従います:
- ほとんどのクエリでフィルタリングに使用されるフィールドを使用する
- 最初にカーディナリティの低い列を選択する
- タイムスタンプデータセットで時刻でフィルタリングすることは非常に一般的であるため、プライマリキーに時間ベースのコンポーネントを検討する
私たちの場合、次のプライマリキーを実験します:passenger_count、pickup_datetime、dropoff_datetime。
passenger_countのカーディナリティは小さく(24のユニーク値)、遅いクエリで使用されています。また、タイムスタンプフィールド(pickup_datetimeとdropoff_datetime)を追加します。これらは頻繁にフィルタリングされる可能性があるためです。
プライマリキーを使用して新しいテーブルを作成し、データを再取り込みします。
CREATE TABLE trips_small_pk
(
`vendor_id` UInt8,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` UInt16,
`dropoff_location_id` UInt16,
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
PRIMARY KEY (passenger_count, pickup_datetime, dropoff_datetime);
-- Insert the data
INSERT INTO trips_small_pk SELECT * FROM trips_small_inferred
次に、クエリを再実行します。3つの実験からの結果をまとめて、経過時間、処理行数、メモリ消費の改善を確認します。
| クエリ1 |
|---|
| 実行1 | 実行2 | 実行3 |
|---|
| 経過時間 | 1.699 sec | 1.353 sec | 0.765 sec |
| 処理行数 | 329.04 million | 329.04 million | 329.04 million |
| ピークメモリ | 440.24 MiB | 337.12 MiB | 444.19 MiB |
| クエリ2 |
|---|
| 実行1 | 実行2 | 実行3 |
|---|
| 経過時間 | 1.419 sec | 1.171 sec | 0.248 sec |
| 処理行数 | 329.04 million | 329.04 million | 41.46 million |
| ピークメモリ | 546.75 MiB | 531.09 MiB | 173.50 MiB |
| クエリ3 |
|---|
| 実行1 | 実行2 | 実行3 |
|---|
| 経過時間 | 1.414 sec | 1.188 sec | 0.431 sec |
| 処理行数 | 329.04 million | 329.04 million | 276.99 million |
| ピークメモリ | 451.53 MiB | 265.05 MiB | 197.38 MiB |
実行時間と使用メモリの両方で、全体的に大幅な改善が見られます。
クエリ2はプライマリキーから最も恩恵を受けています。生成されたクエリプランが以前とどのように異なるか見てみましょう。
EXPLAIN indexes = 1
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM nyc_taxi.trips_small_pk
WHERE (pickup_datetime >= '2009-01-01') AND (pickup_datetime < '2009-04-01')
GROUP BY payment_type
ORDER BY trip_count DESC
Query id: 30116a77-ba86-4e9f-a9a2-a01670ad2e15
┌─explain──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY [lifted up part])) │
2. │ Sorting (Sorting for ORDER BY) │
3. │ Expression (Before ORDER BY) │
4. │ Aggregating │
5. │ Expression (Before GROUP BY) │
6. │ Expression │
7. │ ReadFromMergeTree (nyc_taxi.trips_small_pk) │
8. │ Indexes: │
9. │ PrimaryKey │
10. │ Keys: │
11. │ pickup_datetime │
12. │ Condition: and((pickup_datetime in (-Inf, 1238543999]), (pickup_datetime in [1230768000, +Inf))) │
13. │ Parts: 9/9 │
14. │ Granules: 5061/40167 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
プライマリキーのおかげで、テーブルグラニュールのサブセットのみが選択されました。ClickHouseが処理する必要のあるデータが大幅に少なくなるため、これだけでクエリパフォーマンスが大幅に向上します。
次のステップ
このガイドが、ClickHouseで遅いクエリを調査し、それらを高速化する方法について良い理解を得るのに役立つことを願っています。このトピックをさらに探求するには、クエリアナライザーとプロファイリングについて詳しく読んで、ClickHouseがクエリを正確にどのように実行しているかをより良く理解することをお勧めします。
ClickHouseの特性にもっと慣れてきたら、パーティショニングキーとデータスキッピングインデックスについて読んで、クエリを加速するために使用できるより高度なテクニックについて学ぶことをお勧めします。