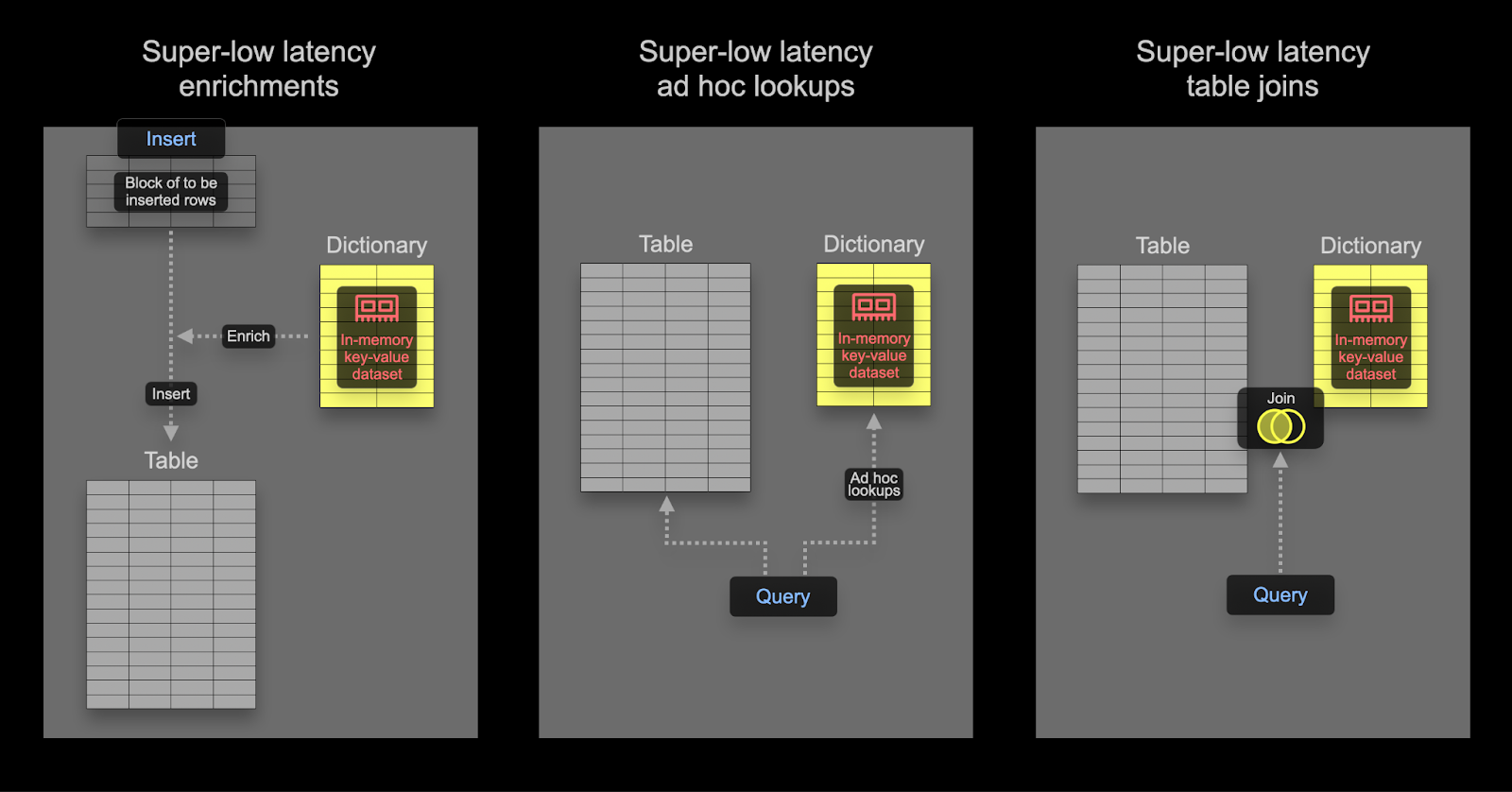
ClickHouse における Dictionary は、さまざまな内部および外部ソースからのデータをインメモリのキー・バリュー形式で表現し、超低レイテンシーなルックアップクエリのために最適化されたものです。
Dictionary は次の用途に有用です:
- 特に
JOIN を使用する場合に、クエリのパフォーマンスを向上させる
- インジェスト処理を低速化することなく、取り込むデータをオンザフライで拡充する
Dictionary を使用した結合の高速化
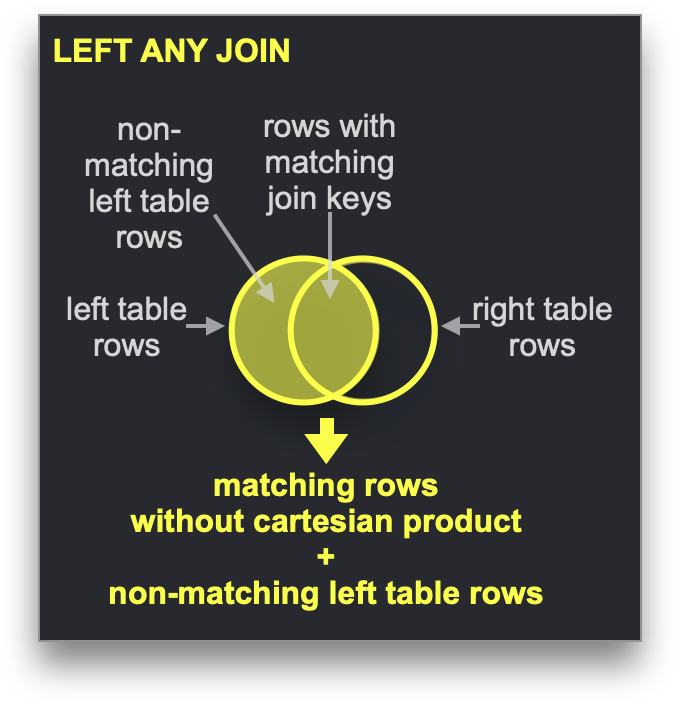
Dictionary は、特定の種類の JOIN、すなわち結合キーが基盤となるキー・バリュー型ストレージのキー属性と一致している必要がある LEFT ANY 型 を高速化するために利用できます。
この条件を満たす場合、ClickHouse は Dictionary を利用して Direct Join を実行できます。これは ClickHouse で最も高速な結合アルゴリズムであり、右側のテーブルの基盤となる table engine が低レイテンシーのキー・バリュー要求をサポートしている場合に適用可能です。ClickHouse にはこれを提供するテーブルエンジンが 3 つあります。Join(事前計算済みハッシュテーブルに相当)、EmbeddedRocksDB、および Dictionary です。ここでは Dictionary ベースのアプローチについて説明しますが、仕組みは 3 つのエンジンで共通です。
Direct Join アルゴリズムでは、右側のテーブルが Dictionary をバックエンドとして使用しており、そのテーブルから結合対象となるデータが、低レイテンシーのキー・バリュー型データ構造として、すでにメモリ上に存在している必要があります。
Stack Overflow データセットを使って、次の質問に答えてみましょう:
Hacker News 上で、SQL に関して最も物議を醸している投稿はどれか?
ここでは、賛成票と反対票の数が近い投稿を「物議を醸している」と定義します。この絶対差を計算し、値が 0 に近いほど物議の度合いが高いとみなします。また、投稿には少なくとも賛成票と反対票がそれぞれ 10 件以上あるものと仮定します — ほとんど投票されない投稿は、あまり物議を醸しているとは言えないためです。
データを正規化した状態では、このクエリでは現在、posts テーブルと votes テーブルを使った JOIN が必要です。
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT
Id,
Title,
UpVotes,
DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
INNER JOIN
(
SELECT
PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
WHERE PostId IN (PostIds)
GROUP BY PostId
HAVING (UpVotes > 10) AND (DownVotes > 10)
) AS votes ON posts.Id = votes.PostId
WHERE Id IN (PostIds)
ORDER BY Controversial_ratio ASC
LIMIT 1
行 1:
──────
Id: 25372161
Title: How to add exception handling to SqlDataSource.UpdateCommand
UpVotes: 13
DownVotes: 13
Controversial_ratio: 0
1 行が返されました。経過時間: 1.283秒。処理された行数: 4億1844万行、7.23 GB (3億2607万行/秒、5.63 GB/秒)
ピークメモリ使用量: 3.18 GiB。
JOIN の右側には小さいデータセットを使用する: このクエリでは、外側とサブクエリの両方で PostId によるフィルタリングを行っているため、必要以上に冗長に見えるかもしれません。これはクエリの応答時間を短く保つためのパフォーマンス最適化です。最適なパフォーマンスを得るには、常に JOIN の右側がより小さな集合となるようにし、可能な限り小さく保ってください。JOIN のパフォーマンス最適化のコツや利用可能なアルゴリズムの理解については、このブログ記事シリーズ を参照することをおすすめします。
このクエリは高速ですが、良好なパフォーマンスを得るには JOIN を慎重に記述する必要があります。本来であれば、「SQL」を含む投稿だけに単純にフィルタリングし、その投稿のサブセットに対して UpVote と DownVote のカウントを確認してメトリクスを計算できるのが理想的です。
Dictionary の適用
これらの概念を示すために、投票データに対して Dictionary を使用します。Dictionary は通常メモリ上に保持されるため(ssd_cache は例外)、データサイズに留意しておく必要があります。ここで votes テーブルのサイズを確認します:
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE table IN ('votes')
GROUP BY table
┌─table───────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ votes │ 1.25 GiB │ 3.79 GiB │ 3.04 │
└─────────────────┴─────────────────┴───────────────────┴───────┘
データは Dictionary 内で非圧縮のまま保存されるため、すべてのカラム(実際にはそうしません)を Dictionary に保存すると仮定すると、少なくとも 4GB のメモリが必要になります。Dictionary はクラスター全体でレプリケートされるため、このメモリ量は ノードごとに 確保しておく必要があります。
以下の例では、Dictionary 用のデータは ClickHouse テーブルを起点としています。これは最も一般的な Dictionary のソースですが、ファイル、HTTP、さらには Postgres を含むデータベースなど、複数のソース がサポートされています。後ほど示すように、Dictionary は自動更新が可能であり、頻繁に変更が発生する小規模なデータセットをダイレクトに JOIN で参照可能にする理想的な手段です。
Dictionary には、ルックアップを行うためのプライマリキーが必要です。これは概念的にはトランザクションデータベースのプライマリキーと同じで、一意である必要があります。上記のクエリでは、JOIN キーである PostId に対してルックアップを行います。Dictionary には、votes テーブルから PostId ごとの賛成票と反対票の合計が格納されている必要があります。以下は、この Dictionary 用データを取得するクエリです。
SELECT PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY PostId
Dictionary を作成するには、以下の DDL を実行します。上記のクエリが使われている点に注目してください。
CREATE DICTIONARY votes_dict
(
`PostId` UInt64,
`UpVotes` UInt32,
`DownVotes` UInt32
)
PRIMARY KEY PostId
SOURCE(CLICKHOUSE(QUERY 'SELECT PostId, countIf(VoteTypeId = 2) AS UpVotes, countIf(VoteTypeId = 3) AS DownVotes FROM votes GROUP BY PostId'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
0 rows in set. Elapsed: 36.063 sec.
セルフマネージドの OSS では、上記のコマンドをすべてのノードで実行する必要があります。ClickHouse Cloud では、Dictionary はすべてのノードに自動的にレプリケートされます。上記は 64GB の RAM を搭載した ClickHouse Cloud ノード上で実行しており、ロードには 36 秒かかりました。
Dictionary によって消費されているメモリを確認するには:
SELECT formatReadableSize(bytes_allocated) AS size
FROM system.dictionaries
WHERE name = 'votes_dict'
┌─size─────┐
│ 4.00 GiB │
└──────────┘
特定の PostId に対する賛成票数と反対票数は、シンプルな dictGet 関数で取得できるようになりました。以下の例では、投稿 11227902 の値を取得しています。
SELECT dictGet('votes_dict', ('UpVotes', 'DownVotes'), '11227902') AS votes
┌─votes──────┐
│ (34999,32) │
└────────────┘
これを先ほどのクエリに適用することで、JOINを削除できます:
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT Id, Title,
dictGet('votes_dict', 'UpVotes', Id) AS UpVotes,
dictGet('votes_dict', 'DownVotes', Id) AS DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
WHERE (Id IN (PostIds)) AND (UpVotes > 10) AND (DownVotes > 10)
ORDER BY Controversial_ratio ASC
LIMIT 3
3行のセット。経過時間:0.551秒。処理:1億1964万行、3.29 GB(2億1696万行/秒、5.97 GB/秒)
ピークメモリ使用量:552.26 MiB。
このクエリははるかに単純なだけでなく、実行速度も2倍以上速くなります。さらに、Dictionary には賛成票・反対票がそれぞれ 10 を超える投稿だけを読み込み、あらかじめ計算しておいた物議度の値だけを保持するようにすれば、より最適化できます。
クエリ時のエンリッチメント
Dictionary はクエリ実行時に値を参照するために使用できます。これらの値は結果として返したり、集約で利用したりできます。たとえば、ユーザー ID を所在地にマッピングする Dictionary を作成するとします。
CREATE DICTIONARY users_dict
(
`Id` Int32,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM stackoverflow.users'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
この Dictionary を使用して、投稿の結果を充実させることができます。
SELECT
Id,
Title,
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location
FROM posts
WHERE Title ILIKE '%clickhouse%'
LIMIT 5
FORMAT PrettyCompactMonoBlock
┌───────Id─┬─Title─────────────────────────────────────────────────────────┬─Location──────────────┐
│ 52296928 │ Comparison between two Strings in ClickHouse │ Spain │
│ 52345137 │ How to use a file to migrate data from mysql to a clickhouse? │ 中国江苏省Nanjing Shi │
│ 61452077 │ How to change PARTITION in clickhouse │ Guangzhou, 广东省中国 │
│ 55608325 │ Clickhouse select last record without max() on all table │ Moscow, Russia │
│ 55758594 │ ClickHouse create temporary table │ Perm', Russia │
└──────────┴───────────────────────────────────────────────────────────────┴───────────────────────┘
5行が返されました。経過時間: 0.033秒。処理された行数: 425万行、82.84 MB (1億3062万行/秒、2.55 GB/秒)
ピークメモリ使用量: 249.32 MiB。
上記の結合例と同様に、同じ Dictionary を使用して、ほとんどの投稿がどこから投稿されているのかを効率的に判定できます。
SELECT
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location,
count() AS c
FROM posts
WHERE location != ''
GROUP BY location
ORDER BY c DESC
LIMIT 5
┌─location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
│ United Kingdom │ 537699 │
└────────────────────────┴────────┘
5 rows in set. Elapsed: 0.763 sec. Processed 59.82 million rows, 239.28 MB (78.40 million rows/s., 313.60 MB/s.)
Peak memory usage: 248.84 MiB.
インデックス時のエンリッチメント
上記の例では、クエリ時に Dictionary を使用して結合を回避しました。Dictionary は、挿入時に行をエンリッチするためにも使用できます。これは通常、エンリッチに用いる値が変化せず、Dictionary を埋めるために利用できる外部ソースに存在する場合に適しています。この場合、行を挿入時にエンリッチしておくことで、クエリ時に Dictionary を参照してルックアップする必要を回避できます。
Stack Overflow におけるユーザーの Location が決して変わらない(実際には変わりますが)と仮定してみましょう。具体的には、users テーブルの Location カラムです。posts テーブルに対して Location ごとの分析クエリを実行したいとします。このテーブルには UserId が含まれています。
Dictionary は、users テーブルをデータソースとして、ユーザー ID から Location へのマッピングを提供します。
CREATE DICTIONARY users_dict
(
`Id` UInt64,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM users WHERE Id >= 0'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
Hashed 型の Dictionary を使用できるようにするため、Id < 0 のユーザーを除外しています。Id < 0 のユーザーはシステムユーザーです。
posts テーブルの挿入時にこの Dictionary を活用するには、スキーマを変更する必要があります。
CREATE TABLE posts_with_location
(
`Id` UInt32,
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
...
`Location` MATERIALIZED dictGet(users_dict, 'Location', OwnerUserId::'UInt64')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
上記の例では、Location は MATERIALIZED カラムとして宣言されています。これは、値を INSERT クエリの一部として指定することもできますが、常に計算された値が使用されることを意味します。
ClickHouse は、DEFAULT columns(値を挿入することも、指定されていない場合に計算させることもできるカラム)もサポートしています。
テーブルにデータを投入するには、通常どおり S3 からの INSERT INTO SELECT を使用できます。
INSERT INTO posts_with_location SELECT Id, PostTypeId::UInt8, AcceptedAnswerId, CreationDate, Score, ViewCount, Body, OwnerUserId, OwnerDisplayName, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Title, Tags, AnswerCount, CommentCount, FavoriteCount, ContentLicense, ParentId, CommunityOwnedDate, ClosedDate FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 36.830 sec. Processed 238.98 million rows, 2.64 GB (6.49 million rows/s., 71.79 MB/s.)
これで、投稿の大半がどの場所から来ているか、その場所名を取得できるようになりました。
SELECT Location, count() AS c
FROM posts_with_location
WHERE Location != ''
GROUP BY Location
ORDER BY c DESC
LIMIT 4
┌─Location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
└────────────────────────┴────────┘
4 rows in set. Elapsed: 0.142 sec. Processed 59.82 million rows, 1.08 GB (420.73 million rows/s., 7.60 GB/s.)
Peak memory usage: 666.82 MiB.
Dictionary の高度なトピック
辞書レイアウトの選び方、辞書と JOIN のどちらを利用するタイミング、および辞書使用状況の監視に関する指針については、Dictionary のベストプラクティスを参照してください。
辞書の更新
LIFETIME を MIN 600 MAX 900 として辞書に指定しています。LIFETIME は辞書の更新間隔であり、ここでの値により 600~900 秒のランダムな間隔で定期的に再読み込みが行われます。このランダムな間隔は、多数のサーバーで更新を行う際に、辞書ソースへの負荷を分散するために必要です。更新中も辞書の旧バージョンには引き続きクエリでき、クエリがブロックされるのは初回ロード時のみです。(LIFETIME(0)) を設定すると、辞書が更新されなくなる点に注意してください。
辞書は SYSTEM RELOAD DICTIONARY コマンドを使用して強制的に再読み込みできます。
ClickHouse や Postgres のようなデータベースソースでは、定期的な間隔ではなく、実際に変更があった場合にのみ辞書を更新するクエリを設定できます(これを判定するのはクエリのレスポンスです)。詳細はこちらを参照してください。
その他の Dictionary タイプ
ClickHouse では、Hierarchical、Polygon、および Regular Expression の各 Dictionary もサポートしています。
参考情報