プロジェクション
はじめに
ClickHouse は、リアルタイムなシナリオで大規模なデータに対する分析クエリを高速化するための、さまざまなメカニズムを提供します。その 1 つが、Projection を利用してクエリを高速化する方法です。Projection は、関心のある属性でデータを並べ替えることでクエリを最適化します。これは次のような形を取ることができます。
- テーブル全体の並べ替え
- 元のテーブルの一部を、異なる順序で保持したもの
- 事前計算された集計(マテリアライズドビューに類似)であり、集計に合わせた並び順を持つもの
Projection はどのように動作しますか?
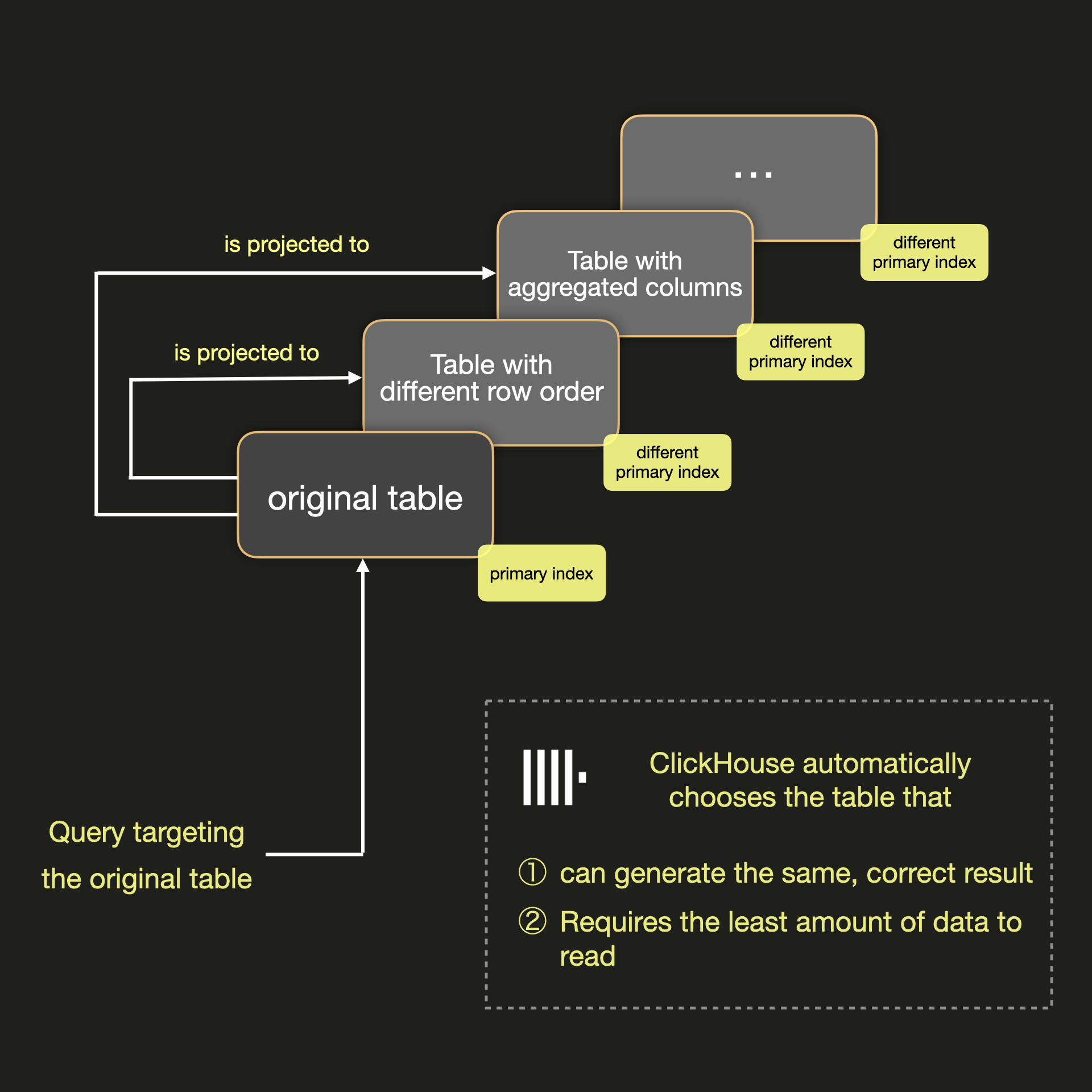
実際には、Projection は元のテーブルに付随する追加の「不可視なテーブル」のようなものと考えることができます。Projection は元のテーブルとは異なる行の順序を持つことができ、その結果として異なるプライマリインデックスを持つことができ、さらに集約値を自動的かつインクリメンタルに事前計算できます。その結果、Projection を使用すると、クエリ実行を高速化するための 2 つの「チューニング手段」を得られます:
- プライマリインデックスを適切に活用すること
- 集約を事前計算すること
Projection は、複数の行順序を持ち、挿入時に集約を事前計算できるという点で Materialized Views (マテリアライズドビュー)と似ています。 Projection は自動的に更新され、元のテーブルと同期が維持されますが、マテリアライズドビューは明示的に更新する必要があります。クエリが元のテーブルを対象とする場合、 ClickHouse はプライマリキーを自動的にサンプリングし、同じ正しい結果を生成でき、かつ読み取る必要があるデータ量が最も少ないテーブルを、以下の図のように選択します:
_part_offset を用いたよりスマートなストレージ
バージョン 25.5 以降、ClickHouse はプロジェクション内で仮想カラム _part_offset を
サポートしており、プロジェクションの新しい定義方法を提供します。
現在、プロジェクションを定義する方法は 2 通りあります。
-
全カラムを保存する(従来の動作): プロジェクションには完全なデータが含まれ、 プロジェクションのソート順とフィルタが一致する場合は、プロジェクションから直接読み取ることで 高速に処理できます。
-
ソートキー +
_part_offsetのみを保存する: プロジェクションはインデックスのように動作します。 ClickHouse はプロジェクションのプライマリインデックスを使って一致する行を特定しますが、 実際のデータはベーステーブルから読み取ります。これにより、クエリ時の I/O がやや増える 代わりにストレージのオーバーヘッドを削減できます。
上記のアプローチは組み合わせることもでき、プロジェクションに一部のカラムを直接保存し、
その他のカラムを _part_offset を介して間接的に保存できます。
プロジェクションを使用するタイミング
プロジェクションは、新しいユーザーにとって魅力的な機能です。というのも、データ挿入時に自動的に 維持されるためです。さらに、クエリは 1 つのテーブルに対して送信するだけでよく、可能な場合には プロジェクションが利用されて応答時間が短縮されます。
これはマテリアライズドビューとは対照的であり、マテリアライズドビューでは、ユーザーはフィルタに 応じて適切に最適化されたターゲットテーブルを選択するか、クエリを書き換える必要があります。 これにより、ユーザーアプリケーションへの依存度が高まり、クライアント側の複雑さが増します。
これらの利点にもかかわらず、プロジェクションには本質的な制約がいくつか存在するため、 その点を理解したうえで、必要最小限の利用にとどめるべきです。
- プロジェクションでは、ソーステーブルと(非表示の)ターゲットテーブルで異なる TTL を 使用することはできませんが、マテリアライズドビューでは異なる TTL を使用できます。
- プロジェクションを持つテーブルでは、論理更新および削除はサポートされていません。
- マテリアライズドビューはチェーン化できます。1 つのマテリアライズドビューのターゲットテーブルを、 別のマテリアライズドビューのソーステーブルとして利用することができます。このようなことは プロジェクションでは不可能です。
- プロジェクション定義では JOIN はサポートされませんが、マテリアライズドビューではサポートされます。 ただし、プロジェクションを持つテーブルに対するクエリでは、自由に JOIN を使用できます。
- プロジェクション定義ではフィルタ(
WHERE句)はサポートされませんが、マテリアライズドビューでは サポートされます。とはいえ、プロジェクションを持つテーブルに対するクエリでは、自由にフィルタできます。
プロジェクションの使用を推奨するのは、次のような場合です。
- データの完全な並べ替えが必要な場合。理論上は、プロジェクション内の式で
GROUP BYを 使用することも可能ですが、集計の維持にはマテリアライズドビューの方が効果的です。 クエリオプティマイザも、単純な並べ替え、すなわちSELECT * ORDER BY xを使用する プロジェクションの方をより活用しやすくなります。 この式内で列のサブセットを選択することで、ストレージフットプリントを削減できます。 - ストレージフットプリントの増加や、データを書き込む処理が 2 回になることに伴うオーバーヘッドを 許容できる場合。挿入速度への影響をテストし、 ストレージオーバーヘッドを評価してください。
例
プライマリキーに含まれないカラムでのフィルタリング
この例では、テーブルに Projection を追加する方法を説明します。 また、この Projection を使用して、テーブルのプライマリキーに含まれない カラムでフィルタリングを行うクエリを高速化する方法も見ていきます。
この例では、pickup_datetime で並べ替えられている、
sql.clickhouse.com で利用可能な New York Taxi Data
データセットを使用します。
乗客が運転手に 200 ドルを超える額のチップを支払った すべてのトリップ ID を検索する、簡単なクエリを書いてみましょう。
ORDER BY に含まれていない tip_amount でフィルタリングしているため、ClickHouse
はテーブル全体をスキャンする必要がありました。このクエリを高速化していきましょう。
元のテーブルと結果を保持するために、新しいテーブルを作成し、INSERT INTO SELECT を使ってデータをコピーします。
プロジェクションを追加するには、ALTER TABLE 文と ADD PROJECTION 文を組み合わせて使用します。
プロジェクションを追加した後は、上記で指定したクエリに従って、その中のデータが物理的に並べ替えおよび再書き込みされるように、MATERIALIZE PROJECTION ステートメントを実行する必要があります。
プロジェクションを追加したので、クエリをもう一度実行してみましょう。
クエリ時間を大幅に短縮でき、スキャンが必要な行数も少なくなっていることに注目してください。
上記のクエリが実際に作成したプロジェクションを使用していたことは、
system.query_log テーブルを参照することで確認できます。
プロジェクションを使用してUK不動産価格データのクエリを高速化する
プロジェクションを使用してクエリパフォーマンスを高速化する方法を実証するため、実際のデータセットを使用した例を見ていきます。この例では、3,003万行を含むUK Property Price Paidチュートリアルのテーブルを使用します。このデータセットはsql.clickhouse.com環境でも利用可能です。
テーブルの作成方法とデータの挿入方法を確認する場合は、"英国不動産価格データセット"のページを参照してください。
このデータセットに対して2つの簡単なクエリを実行できます。1つ目はロンドンで最も高い支払価格を記録した郡を一覧表示し、2つ目は郡ごとの平均価格を計算します。
両方のクエリで全3,003万行のフルテーブルスキャンが発生したことに注意してください。非常に高速ではありますが、これはテーブル作成時の ORDER BY 句にtownもpriceも含まれていなかったためです:
プロジェクションを使用してこのクエリを高速化できるか見てみましょう。
元のテーブルと結果を保持するために、新しいテーブルを作成し、INSERT INTO SELECTを使用してデータをコピーします:
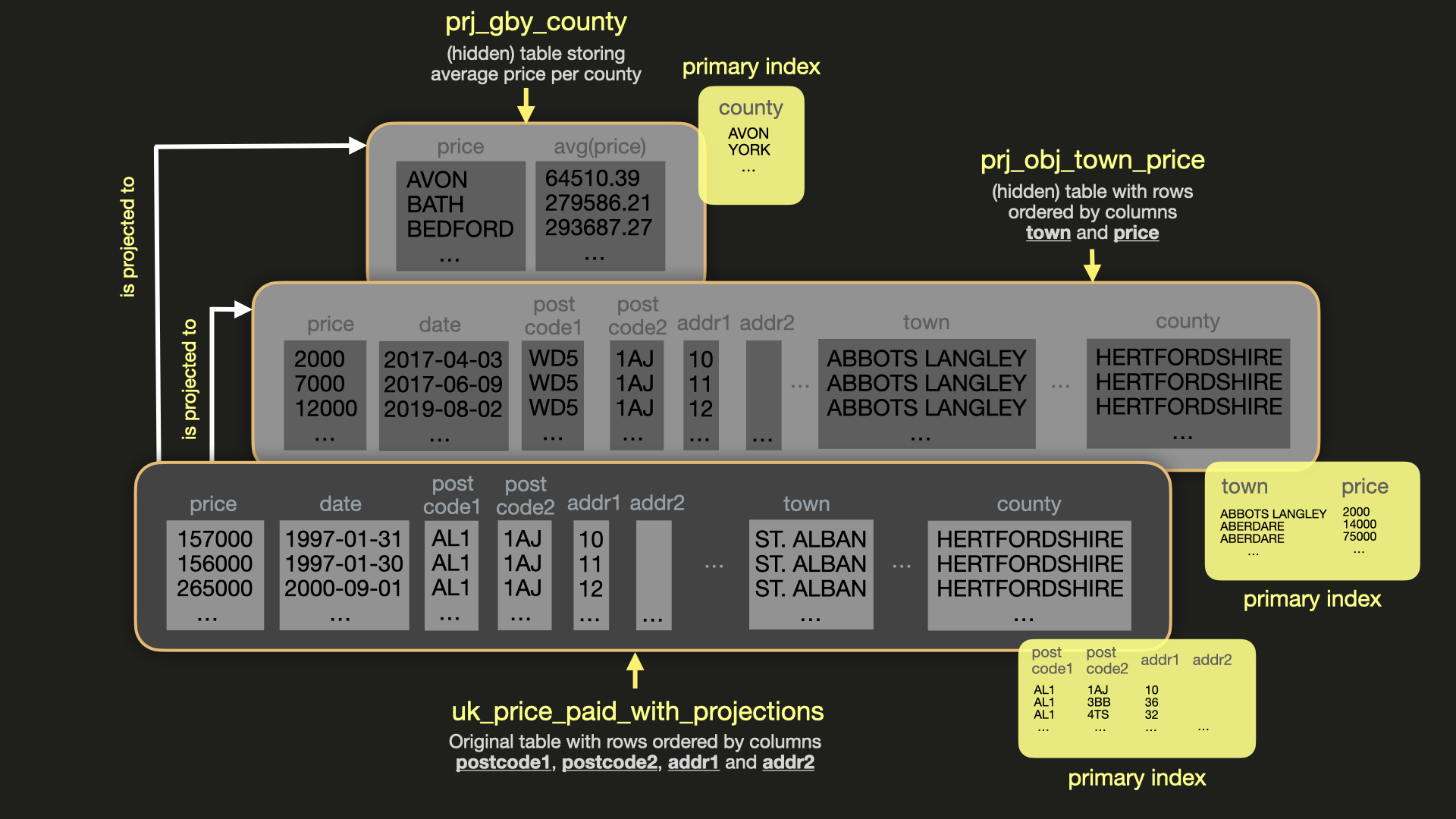
プロジェクション prj_oby_town_price を作成してデータを投入します。これにより、町と価格で順序付けされたプライマリインデックスを持つ追加の(非表示)テーブルが生成され、特定の町で最高価格が支払われた郡を一覧表示するクエリが最適化されます:
mutations_sync設定を使用して、同期実行を強制します。
プロジェクション prj_gby_county を作成して投入します。これは追加の(非表示の)テーブルであり、既存の英国130郡すべてについて avg(price) 集計値を段階的に事前計算します:
上記の prj_gby_county プロジェクションのように、プロジェクション内で GROUP BY 句が使用されている場合、(隠された)テーブルの基盤となるストレージエンジンは AggregatingMergeTree になり、すべての集約関数は AggregateFunction に変換されます。これにより、適切な増分データ集約が保証されます。
以下の図は、メインテーブル uk_price_paid_with_projections とその2つのプロジェクションの視覚化です:
ロンドンにおける上位3件の高額取引価格の郡を一覧表示するクエリを再実行すると、クエリパフォーマンスが向上していることが確認できます:
同様に、平均支払価格が最も高い上位3つの英国カウンティをリストするクエリの場合:
両方のクエリが元のテーブルを対象としており、2つのプロジェクションを作成する前は、両方のクエリでフルテーブルスキャン(全3,003万行がディスクから読み込まれる)が発生していたことに注意してください。
また、ロンドンの郡を支払価格が最も高い上位 3 件について列挙するクエリでは、2.17 百万行がストリーミングされている点にも注意してください。このクエリ向けに最適化された 2 つ目のテーブルを直接使用した場合、ディスクから読み出されたのは 8.192 万行だけでした。
この差が生じる理由は、上で述べた optimize_read_in_order 最適化が、現時点ではプロジェクションではサポートされていないためです。
system.query_log テーブルを確認すると、上記 2 つのクエリに対して ClickHouse が自動的に 2 つのプロジェクションを使用していることが分かります(下の projections 列を参照):
さらに例を示します
次の例では、同じ英国の価格データセットを使用し、プロジェクションを使用するクエリと使用しないクエリを比較します。
元のテーブル(とそのパフォーマンス)を維持するため、ここでも CREATE AS と INSERT INTO SELECT を使ってテーブルのコピーを作成します。
プロジェクションを作成する
toYear(date)、district、town をディメンションとする集約プロジェクションを作成します:
既存データに対してプロジェクションをマテリアライズします。(マテリアライズしない場合、プロジェクションは新たに挿入されるデータに対してのみ作成されます):
次のクエリでは、プロジェクションあり/なしの場合のパフォーマンスを比較します。プロジェクションの使用を無効にするには、デフォルトで有効になっている設定 optimize_use_projections を変更します。
クエリ 1. 年ごとの平均価格
結果は同じになるはずですが、後者の例のほうがパフォーマンスは良くなります。
クエリ 2. ロンドンにおける年ごとの平均価格
クエリ 3. 最も高価な地域
条件 (date >= '2020-01-01') を、プロジェクションのディメンション (toYear(date) >= 2020) と一致するように変更します。
今回も結果は同じですが、2 番目のクエリではクエリ性能が向上している点に注目してください。
1 つのクエリでプロジェクションを組み合わせる
バージョン 25.6 以降では、前のバージョンで導入された _part_offset のサポートに基づき、
ClickHouse は複数のプロジェクションを使用して、複数のフィルター条件を持つ
単一のクエリを高速化できるようになりました。
重要な点として、ClickHouse は依然として 1 つのプロジェクション(またはベーステーブル) からしかデータを読み取りませんが、読み取り前に不要なパーツを除外するために、 他のプロジェクションのプライマリインデックスを利用できます。 これは、複数の列でフィルタリングを行い、それぞれが異なるプロジェクションに マッチする可能性があるクエリに特に有用です。
現在、このメカニズムはパーツ全体のみをプルーニングします。 グラニュールレベルでのプルーニングはまだサポートされていません。
これを示すため、(_part_offset 列を使用するプロジェクションを持つ)テーブルを定義し、
上の図に対応する 5 行のサンプルデータを挿入します。
次にテーブルにデータを挿入します。
注意: このテーブルは説明のために、1 行ごとの granule や part のマージ無効化といったカスタム設定を使用していますが、これらは本番環境での利用には推奨されません。
このセットアップにより、次のような状態になります:
- 5 つの個別の part(挿入された各行につき 1 つ)
- ベーステーブルおよび各 projection で、行ごとに 1 つのプライマリインデックスエントリ
- 各 part にはちょうど 1 行のみが含まれる
この構成で、region と user_id の両方でフィルタするクエリを実行します。
ベーステーブルのプライマリインデックスは event_date と id から構築されているため
ここでは役に立たないため、ClickHouse は代わりに次を使用します:
region_projを用いて region に基づき part を絞り込むuser_id_projを用いてさらにuser_idによる絞り込みを行う
この挙動は EXPLAIN projections = 1 を使うことで確認できます。これにより、
ClickHouse が projection をどのように選択し適用するかを確認できます。
上に示した EXPLAIN の出力は、論理クエリプランを上から下へと順に表しています。
| 行番号 | 説明 |
|---|---|
| 3 | page_views ベーステーブルから読み取りを行う |
| 5-13 | region_proj を使用して region = 'us_west' である 3 つのパーツを特定し、5 つのパーツのうち 2 つを除外 |
| 14-22 | user_id_proj を使用して user_id = 107 である 1 つのパーツを特定し、残り 3 つのパーツのうちさらに 2 つを除外 |
最終的に、ベーステーブルから読み取られるのは 5 つのパーツのうち 1 つだけ です。 複数の Projection に対するインデックス解析を組み合わせることで、ClickHouse はスキャンするデータ量を大幅に削減し、 ストレージのオーバーヘッドを抑えつつパフォーマンスを向上させます。
