データの非正規化
データの非正規化は、フラット化されたテーブルを使用して JOIN を回避し、クエリのレイテンシーを最小限に抑えるために ClickHouse で用いられる手法です。
正規化スキーマと非正規化スキーマの比較
データの非正規化とは、特定のクエリパターンに対してデータベースのパフォーマンスを最適化するために、あえて正規化プロセスを意図的に元に戻すことを指します。正規化されたデータベースでは、冗長性を最小化しデータ整合性を確保するために、データは複数の関連テーブルに分割されます。非正規化では、テーブルを結合したりデータを重複させたり、計算済みフィールドを単一または少数のテーブルに取り込むことで冗長性を再導入し、実質的に JOIN をクエリ時から挿入時へと移すことになります。
このプロセスにより、クエリ時に複雑な結合が不要になり、読み取り処理を大幅に高速化できるため、読み取り要求が多くクエリも複雑なアプリケーションに適しています。ただし、重複データへの変更をすべてのインスタンスに伝播して一貫性を維持する必要があるため、書き込み処理や保守の複雑さが増す可能性があります。

NoSQL ソリューションによって一般的になった手法として、JOIN をサポートしない場合にデータを非正規化し、すべての統計情報や関連行を親行上の列およびネストされたオブジェクトとして保存する、というものがあります。例えばブログ用のサンプルスキーマでは、すべての Comments を、それぞれの投稿上のオブジェクトの Array として保存できます。
非正規化を使用するタイミング
一般的には、次のようなケースで非正規化を行うことを推奨します。
- 更新頻度が低いテーブル、または分析クエリでデータが利用可能になるまでの遅延を許容できるテーブル、すなわちデータをバッチで完全に再読み込みできるテーブルを非正規化する。
- 多対多関係の非正規化は避ける。これは、単一のソース行が変更された場合に、多数の行を更新する必要が生じる可能性があるためです。
- 高カーディナリティな関係の非正規化は避ける。テーブル内の各行が別のテーブル内の数千件の関連エントリを持つ場合、それらはプリミティブ型またはタプルの
Arrayとして表現する必要があります。一般的に、1000 を超えるタプルを持つ配列は推奨されません。 - すべての列をネストされたオブジェクトとして非正規化するのではなく、materialized view(後述)を使用して統計値だけを非正規化することを検討してください。
すべての情報を非正規化する必要はなく、頻繁にアクセスする必要がある重要な情報だけを非正規化すれば十分です。
非正規化の処理は、ClickHouse 内で行うことも、上流で、たとえば Apache Flink を使用して行うこともできます。
頻繁に更新されるデータでの非正規化は避ける
ClickHouse では、非正規化はクエリ性能を最適化するために利用できる選択肢のひとつですが、慎重に使用する必要があります。データが頻繁に更新され、ほぼリアルタイムに更新する必要がある場合、この手法は避けてください。メインテーブルがほぼ追記専用であるか、たとえば毎日などバッチとして定期的に再ロードできる場合にのみ、この手法を使用してください。
このアプローチには、本質的な課題がひとつあります。それは書き込み性能とデータ更新です。より具体的には、非正規化はデータ結合の責務をクエリ時点からインジェスト時点に事実上移すことになります。これはクエリ性能を大きく向上させられる一方で、インジェストを複雑にし、構成に使用された行のいずれかが変更された場合には、データパイプラインがその行を ClickHouse に再挿入する必要があることを意味します。これは、1つのソース行の変更が、場合によっては ClickHouse 内の多くの行を更新する必要があることを意味します。スキーマが複雑で、行が複雑な結合から構成されている場合、結合のネストされたコンポーネント内の1行の変更が、潜在的に数百万行の更新を必要とする可能性があります。
これをリアルタイムで実現するのは非現実的であることが多く、次の2つの課題により多大なエンジニアリング工数を要します。
- テーブル行が変更されたときに、正しい結合ステートメントをトリガーすること。理想的には、結合対象のすべてのオブジェクトを更新するのではなく、影響を受けたものだけを更新すべきです。結合を調整して、正しい行に効率的にフィルタしつつ、高スループット下でこれを実現するには、外部ツールやエンジニアリングが必要です。
- ClickHouse における行の更新は慎重に管理する必要があり、追加の複雑さをもたらします。
そのため、すべての非正規化済みオブジェクトを定期的に再ロードするバッチ更新プロセスのほうが一般的です。
非正規化の実用的なケース
非正規化が妥当となるいくつかの実用的な例と、別のアプローチのほうが望ましいケースを考えてみます。
AnswerCount や CommentCount といった統計情報を含むように、すでに非正規化された Posts テーブルがあるとします ― 元のデータはこの形式で提供されています。実際には、この情報は頻繁に変更される可能性が高いため、正規化したくなるかもしれません。これらの列の多くは、他のテーブルからも取得できます。たとえば、ある投稿に対するコメントは、PostId 列と Comments テーブルを通じて取得できます。例を簡単にするため、ここでは投稿はバッチ処理で再ロードされると仮定します。
また、分析におけるメインテーブルは Posts とみなすため、ここでは他のテーブルを Posts に対してのみ非正規化することを考えます。逆方向に非正規化することが適切なクエリもありますが、その場合も同様の検討事項が当てはまります。
以下の各例について、両方のテーブルを結合で使用する必要があるクエリが存在すると仮定してください。
Posts と Votes
投稿に対する Votes は別テーブルで表現されています。このために最適化されたスキーマを以下に示し、あわせてデータをロードするための INSERT コマンドも示します。
一見すると、これらは posts テーブルに非正規化して格納する候補に見えるかもしれません。このアプローチにはいくつかの課題があります。
posts には頻繁に投票が追加されます。時間の経過とともに投稿ごとの頻度は低下するかもしれませんが、次のクエリから、3万件超の投稿に対して 1 時間あたり約 4 万件の投票があることがわかります。
遅延を許容できるのであればバッチ処理で対処することも可能ですが、それでも更新を処理する必要がありますし、すべての投稿を定期的に再読み込みするようなことは(おそらく望ましくないため)現実的ではありません。
さらに厄介なのは、一部の投稿には投票が極端に多く集まっていることです。
ここでの主なポイントは、各投稿ごとの投票の集計統計があれば、ほとんどの分析には十分であり、すべての投票情報を非正規化する必要はないということです。たとえば、現在の Score 列はそのような統計量、すなわち賛成票の合計から反対票の合計を引いた値を表しています。理想的には、クエリ時に簡単なルックアップでこれらの統計を取得できるのが望ましいでしょう(dictionaries を参照)。
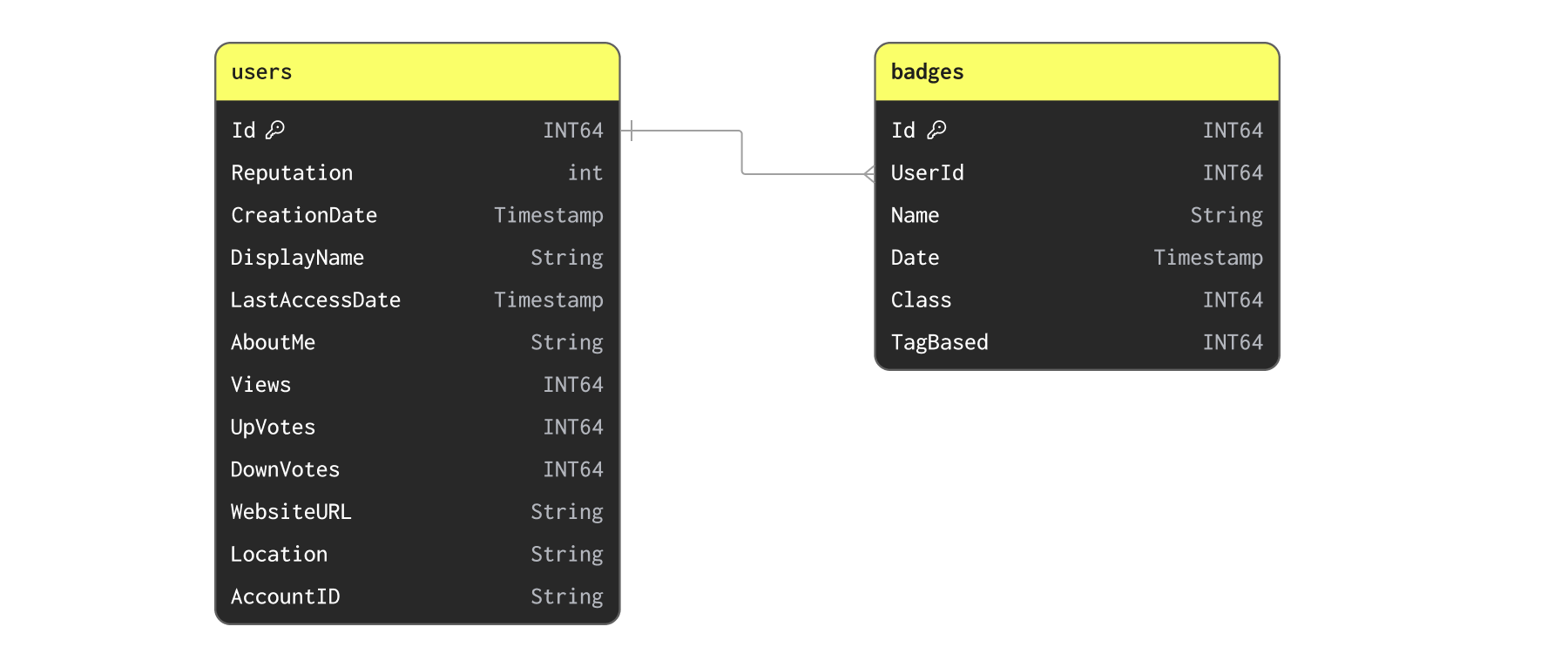
Users と Badges
ここでは Users と Badges について考えてみましょう。
まず、次のコマンドでデータを挿入します。
ユーザーは頻繁にバッジを獲得する可能性がありますが、このデータセットを1日に何度も更新する必要があるとは考えにくいです。バッジとユーザーの関係は一対多です。バッジをタプルのリストとしてユーザー側に単純に非正規化して持たせることはできるでしょうか? 可能ではあるものの、ユーザーごとの最大バッジ数をざっと確認すると、これは得策ではなさそうです。
1行に1万9千個のオブジェクトを非正規化して載せるのは現実的ではないでしょう。この関係は、テーブルを分けたままにするか、統計情報だけを非正規化して追加する形にしておくのが最適かもしれません。
たとえば、バッジからユーザーへ統計情報(バッジ数など)を非正規化して持たせたくなるかもしれません。このデータセットでは、挿入時に辞書を使用する例として、そのようなケースを取り上げます。
Posts と PostLinks
PostLinks は、ユーザーが関連しているまたは重複していると判断した Posts を関連付けます。次のクエリは、スキーマとロードコマンドを示しています。
どの投稿にも、非正規化の妨げとなるほど過剰な数のリンクは存在しないことが確認できます。
同様に、これらのリンクも過度に頻繁に起きるイベントではありません。
以下では、このケースを非正規化の例として用います。
簡単な統計の例
ほとんどの場合、非正規化では、親行に単一のカラムまたは統計値を追加するだけで十分です。たとえば、投稿に重複投稿数の情報を付与したいだけであれば、カラムを 1 つ追加するだけで済みます。
このテーブルにデータを投入するには、重複投稿数の統計と投稿を結合する INSERT INTO ... SELECT 文を使用します。
一対多リレーションのための複合型の活用
非正規化を行うためには、複合型を活用する必要があることがよくあります。少数のカラムを持つ一対一リレーションを非正規化する場合は、上記のように元の型のまま行として追加すれば十分です。しかし、オブジェクトが大きい場合にはこれは望ましくないことが多く、一対多リレーションではそもそも不可能です。
複雑なオブジェクトや一対多リレーションの場合、次のものを使用できます。
- Named Tuple - 関連する構造を一連のカラムとして表現できます。
- Array(Tuple) または Nested - Named Tuple の配列で、Nested とも呼ばれ、各要素が 1 つのオブジェクトを表します。一対多リレーションに適用できます。
例として、以下では PostLinks を Posts に対して非正規化する方法を示します。
各投稿は、前述の PostLinks スキーマで示したように、他の投稿への複数のリンクを含むことができます。Nested 型として、これらのリンク先投稿および重複投稿を次のように表現できます。
設定
flatten_nested=0を使用していることに注意してください。ネストされたデータのフラット化は無効にすることを推奨します。
この非正規化は、OUTER JOIN を用いた INSERT INTO SELECT クエリで実行できます。
ここでは処理時間に注目してください。約 2 分で 6,600 万行を非正規化できました。後ほど説明するように、この処理はスケジュール実行が可能です。
結合を行う前に、PostId ごとに PostLinks を 1 つの配列にまとめるために groupArray 関数を使用している点に注目してください。この配列はその後、LinkedPosts と DuplicatePosts という 2 つのサブリストにフィルタリングされ、外部結合によって生じる空の結果も除外されます。
新しい非正規化済みの構造を確認するために、いくつかの行を選択してみましょう。
非正規化のオーケストレーションとスケジューリング
バッチ
非正規化を活用するには、それを実行し、その処理をオーケストレーションするための変換プロセスが必要です。
上で示したように、INSERT INTO SELECT を使用して、データのロード後にこの変換を実行するために ClickHouse を利用できます。これは、定期的なバッチ変換に適しています。
定期的なバッチロードプロセスが許容できると仮定すると、ユーザーには ClickHouse でこれをオーケストレーションするためのいくつかの選択肢があります。
- リフレッシャブルmaterialized view - リフレッシャブルmaterialized view を使用して、結果をターゲットテーブルに送信するクエリを定期的にスケジュールできます。クエリ実行時、ビューはターゲットテーブルがアトミックに更新されることを保証します。これにより、この作業をスケジューリングするための ClickHouse ネイティブの手段が提供されます。
- 外部ツール - dbt や Airflow などのツールを利用して、変換処理を定期的にスケジュールします。dbt 向け ClickHouse インテグレーション により、新しいバージョンのターゲットテーブルが作成され、その後、現在クエリを受け付けているバージョンとアトミックに入れ替えられることで(EXCHANGE コマンド経由)、この処理がアトミックに実行されることが保証されます。
ストリーミング
代わりに、ClickHouse の外部で、挿入前に Apache Flink などのストリーミング技術を使用してこの処理を実行したい場合もあります。あるいは、インクリメンタルmaterialized view を使用して、データの挿入と同時にこのプロセスを実行することもできます。
