Managed Postgres のクイックスタート
Beta
ClickHouse Managed Postgres は、NVMe ストレージを基盤とするエンタープライズ向けの Postgres であり、EBS のようなネットワーク接続型ストレージと比べて、ディスクI/Oがボトルネックとなるワークロードで最大 10 倍高速なパフォーマンスを実現します。このクイックスタートは 2 つの部に分かれています。
- 第1部: NVMe Postgres を使い始め、その性能を体験する
- 第2部: ClickHouse と統合してリアルタイム分析を実現する
Managed Postgres は現在、AWS の複数のリージョンで利用でき、プライベートプレビュー期間中は無料です。
このクイックスタートで行うこと:
- NVMe による高性能を備えた Managed Postgres インスタンスを作成する
- 100 万件のサンプルイベントを読み込み、NVMe の速度を確認する
- クエリを実行し、低レイテンシのパフォーマンスを体験する
- リアルタイム分析のために ClickHouse にデータをレプリケートする
pg_clickhouse を使用して Postgres から ClickHouse に直接クエリする
第1部: NVMe Postgres の始め方
データベースを作成する
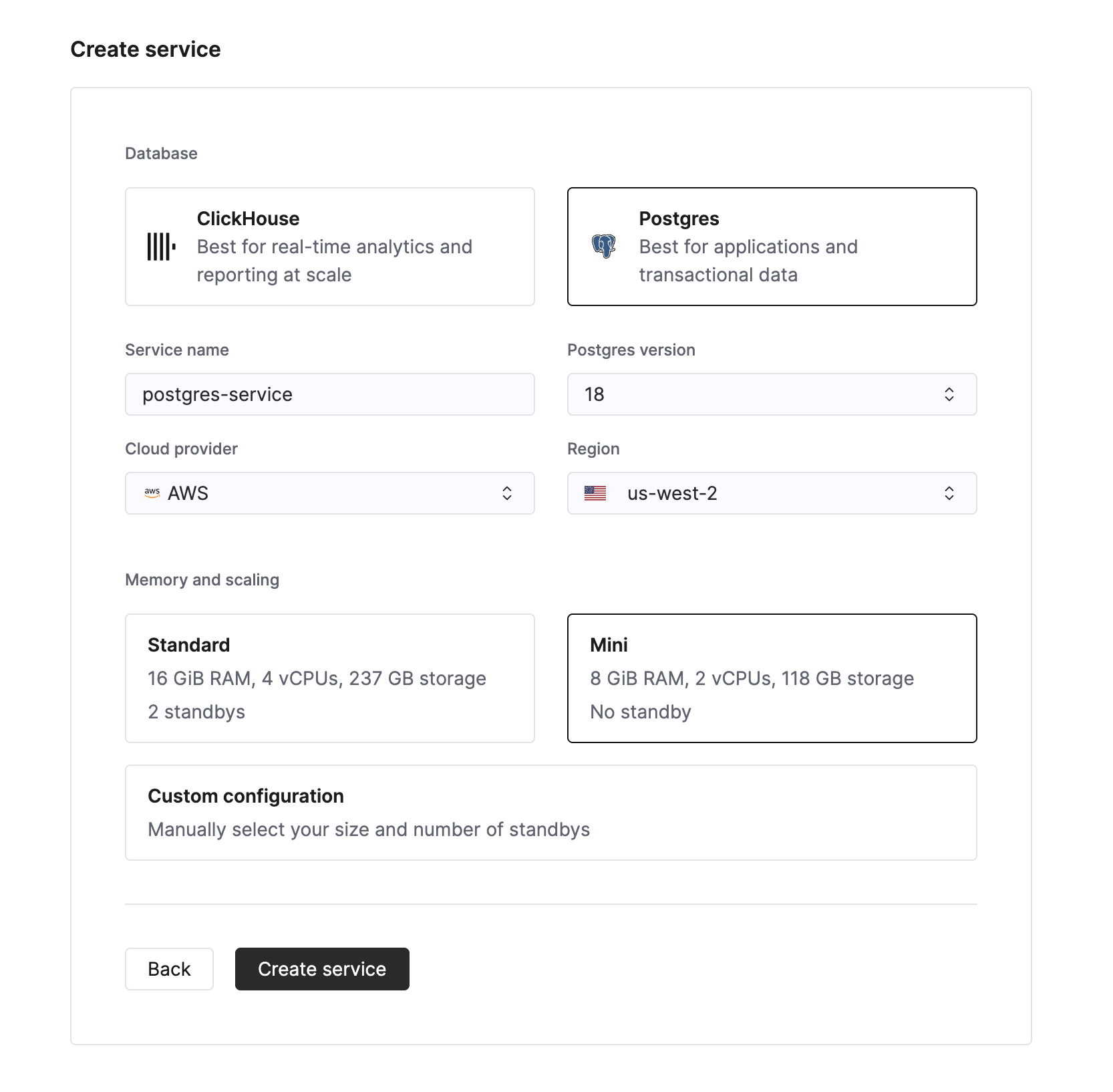
新しい Managed Postgres サービスを作成するには、Cloud コンソールのサービス一覧で New service ボタンをクリックします。次に、データベースタイプとして Postgres を選択できるようになります。
データベースインスタンスの名前を入力し、Create service ボタンをクリックします。概要ページに遷移します。
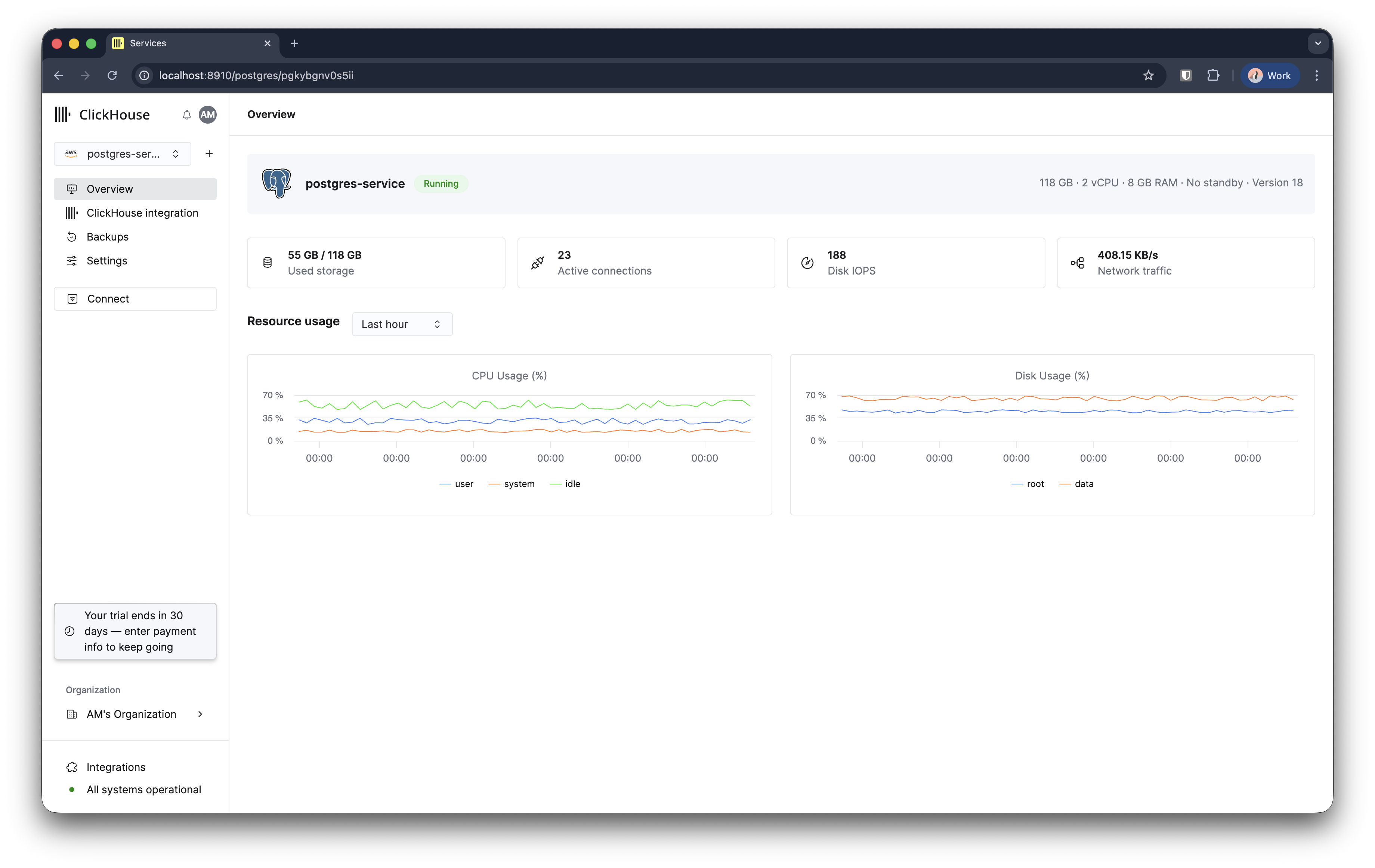
3〜5 分ほどで Managed Postgres インスタンスのプロビジョニングが完了し、利用可能になります。
データベースに接続する
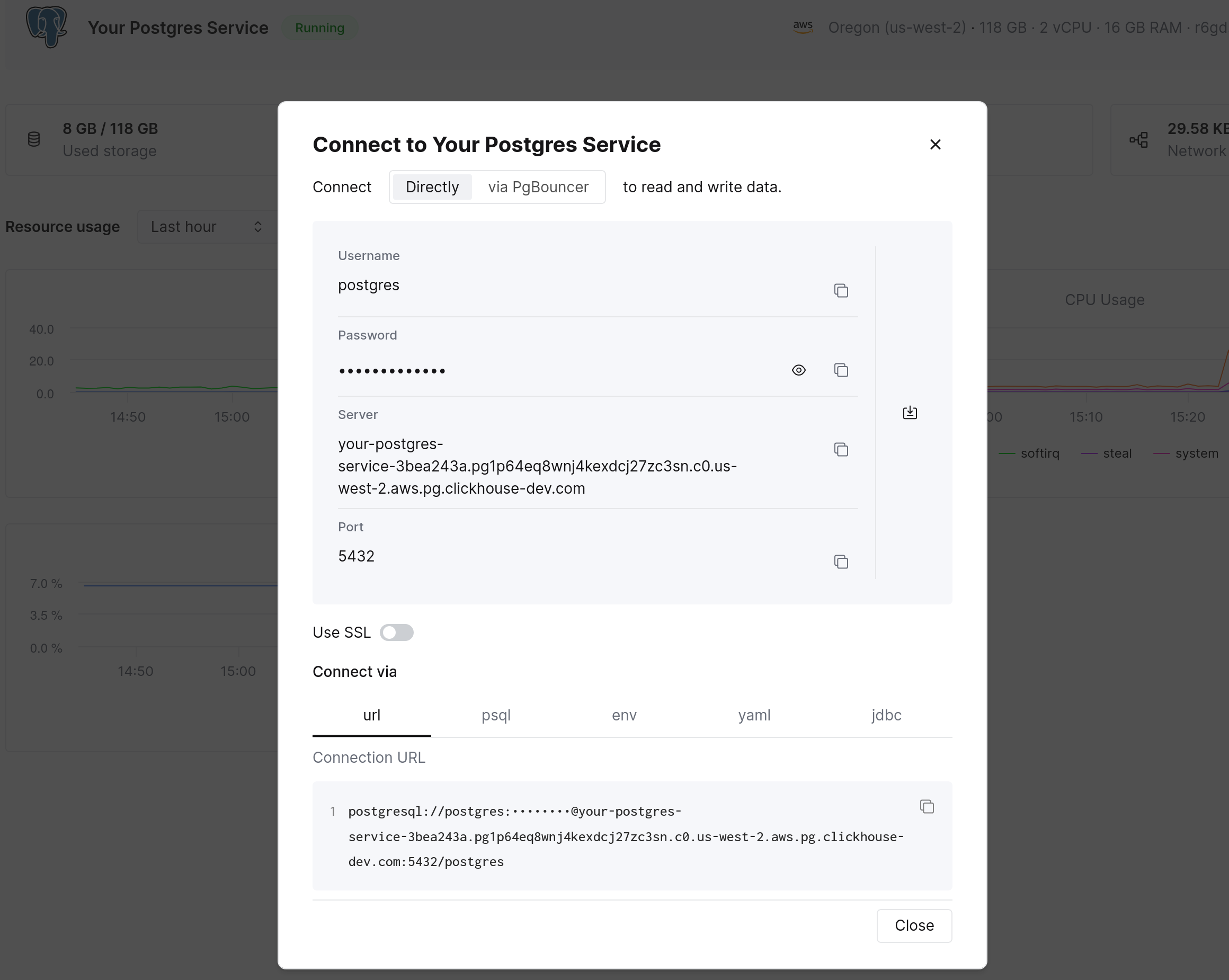
左側のサイドバーには Connect ボタン が表示されています。これをクリックして、さまざまな形式での接続情報と接続文字列を確認します。
psql の接続文字列をコピーしてデータベースに接続します。DBeaver などの Postgres 互換クライアントや任意のアプリケーションライブラリを使用することもできます。
NVMe で強化されたパフォーマンスを実際に確認してみましょう。まず、psql でタイミング計測を有効にしてクエリ実行時間を測定します。
events と users 用のサンプルテーブルを 2 つ作成します:
CREATE TABLE events (
event_id SERIAL PRIMARY KEY,
event_name VARCHAR(255) NOT NULL,
event_type VARCHAR(100),
event_timestamp TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
event_data JSONB,
user_id INT,
user_ip INET,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name VARCHAR(100),
country VARCHAR(50),
platform VARCHAR(50)
);
では、events テーブルに 100 万件のイベントを挿入して、NVMe の速度を確認してみましょう:
INSERT INTO events (event_name, event_type, event_timestamp, event_data, user_id, user_ip)
SELECT
'Event ' || gs::text AS event_name,
CASE
WHEN random() < 0.5 THEN 'click'
WHEN random() < 0.75 THEN 'view'
WHEN random() < 0.9 THEN 'purchase'
WHEN random() < 0.98 THEN 'signup'
ELSE 'logout'
END AS event_type,
NOW() - INTERVAL '1 day' * (gs % 365) AS event_timestamp,
jsonb_build_object('key', 'value' || gs::text, 'additional_info', 'info_' || (gs % 100)::text) AS event_data,
GREATEST(1, LEAST(1000, FLOOR(POWER(random(), 2) * 1000) + 1)) AS user_id,
('192.168.1.' || ((gs % 254) + 1))::inet AS user_ip
FROM
generate_series(1, 1000000) gs;
INSERT 0 1000000
Time: 3596.542 ms (00:03.597)
NVMe のパフォーマンス
100 万行の JSONB データを 4 秒未満で挿入できます。EBS のようなネットワーク接続ストレージを使用する従来のクラウドデータベースでは、ネットワーク往復遅延や IOPS のスロットリングにより、同じ処理に通常は 2~3 倍の時間がかかります。NVMe ストレージはストレージをコンピュートに物理的に直結することで、これらのボトルネックを排除します。
パフォーマンスはインスタンスサイズ、現在の負荷、データ特性によって変動します。
1,000 件のユーザーを挿入します:
INSERT INTO users (name, country, platform)
SELECT
first_names[first_idx] || ' ' || last_names[last_idx] AS name,
CASE
WHEN random() < 0.25 THEN 'India'
WHEN random() < 0.5 THEN 'USA'
WHEN random() < 0.7 THEN 'Germany'
WHEN random() < 0.85 THEN 'China'
ELSE 'Other'
END AS country,
CASE
WHEN random() < 0.2 THEN 'iOS'
WHEN random() < 0.4 THEN 'Android'
WHEN random() < 0.6 THEN 'Web'
WHEN random() < 0.75 THEN 'Windows'
WHEN random() < 0.9 THEN 'MacOS'
ELSE 'Linux'
END AS platform
FROM
generate_series(1, 1000) AS seq
CROSS JOIN LATERAL (
SELECT
array['Alice', 'Bob', 'Charlie', 'Diana', 'Eve', 'Frank', 'Grace', 'Hank', 'Ivy', 'Jack', 'Liam', 'Olivia', 'Noah', 'Emma', 'Sophia', 'Benjamin', 'Isabella', 'Lucas', 'Mia', 'Amelia', 'Aarav', 'Riya', 'Arjun', 'Ananya', 'Wei', 'Li', 'Huan', 'Mei', 'Hans', 'Klaus', 'Greta', 'Sofia'] AS first_names,
array['Smith', 'Johnson', 'Williams', 'Brown', 'Jones', 'Garcia', 'Miller', 'Davis', 'Martinez', 'Taylor', 'Anderson', 'Thomas', 'Jackson', 'White', 'Harris', 'Martin', 'Thompson', 'Moore', 'Lee', 'Perez', 'Sharma', 'Patel', 'Gupta', 'Reddy', 'Zhang', 'Wang', 'Chen', 'Liu', 'Schmidt', 'Müller', 'Weber', 'Fischer'] AS last_names,
1 + (seq % 32) AS first_idx,
1 + ((seq / 32)::int % 32) AS last_idx
) AS names;
データに対してクエリを実行する
では、いくつかクエリを実行して、NVMe ストレージ上の Postgres がどれだけ高速に応答するかを確認してみましょう。
100 万件のイベントを種類ごとに集計する:
SELECT event_type, COUNT(*) as count
FROM events
GROUP BY event_type
ORDER BY count DESC;
event_type | count
------------+--------
click | 499523
view | 375644
purchase | 112473
signup | 12117
logout | 243
(5 rows)
Time: 114.883 ms
JSONB フィルタリングと日付範囲指定を行うクエリ:
SELECT COUNT(*)
FROM events
WHERE event_timestamp > NOW() - INTERVAL '30 days'
AND event_data->>'additional_info' LIKE 'info_5%';
count
-------
9042
(1 row)
Time: 109.294 ms
イベントをユーザーと結合する:
SELECT u.country, COUNT(*) as events, AVG(LENGTH(e.event_data::text))::int as avg_json_size
FROM events e
JOIN users u ON e.user_id = u.user_id
GROUP BY u.country
ORDER BY events DESC;
country | events | avg_json_size
---------+--------+---------------
USA | 383748 | 52
India | 255990 | 52
Germany | 223781 | 52
China | 127754 | 52
Other | 8727 | 52
(5 rows)
Time: 224.670 ms
Postgres の準備が整いました
この時点で、トランザクション・ワークロード向けの高性能な Postgres データベースが完全に稼働しています。
ネイティブな ClickHouse 連携で分析をさらに加速する方法を見るには、パート 2 に進んでください。
パート 2: ClickHouse を使ってリアルタイム分析を追加する
Postgres はトランザクション処理ワークロード (OLTP) に優れていますが、ClickHouse は大規模データセットに対する分析用クエリ (OLAP) に特化して設計されています。2つを連携させることで、双方の長所を活用できます:
- Postgres はアプリケーションのトランザクションデータ (inserts、updates、ポイント検索) を担当
- ClickHouse は数十億行に対するサブセカンドの分析処理を担当
このセクションでは、Postgres のデータを ClickHouse にレプリケートし、シームレスにクエリする方法を説明します。
ClickHouse との統合をセットアップする
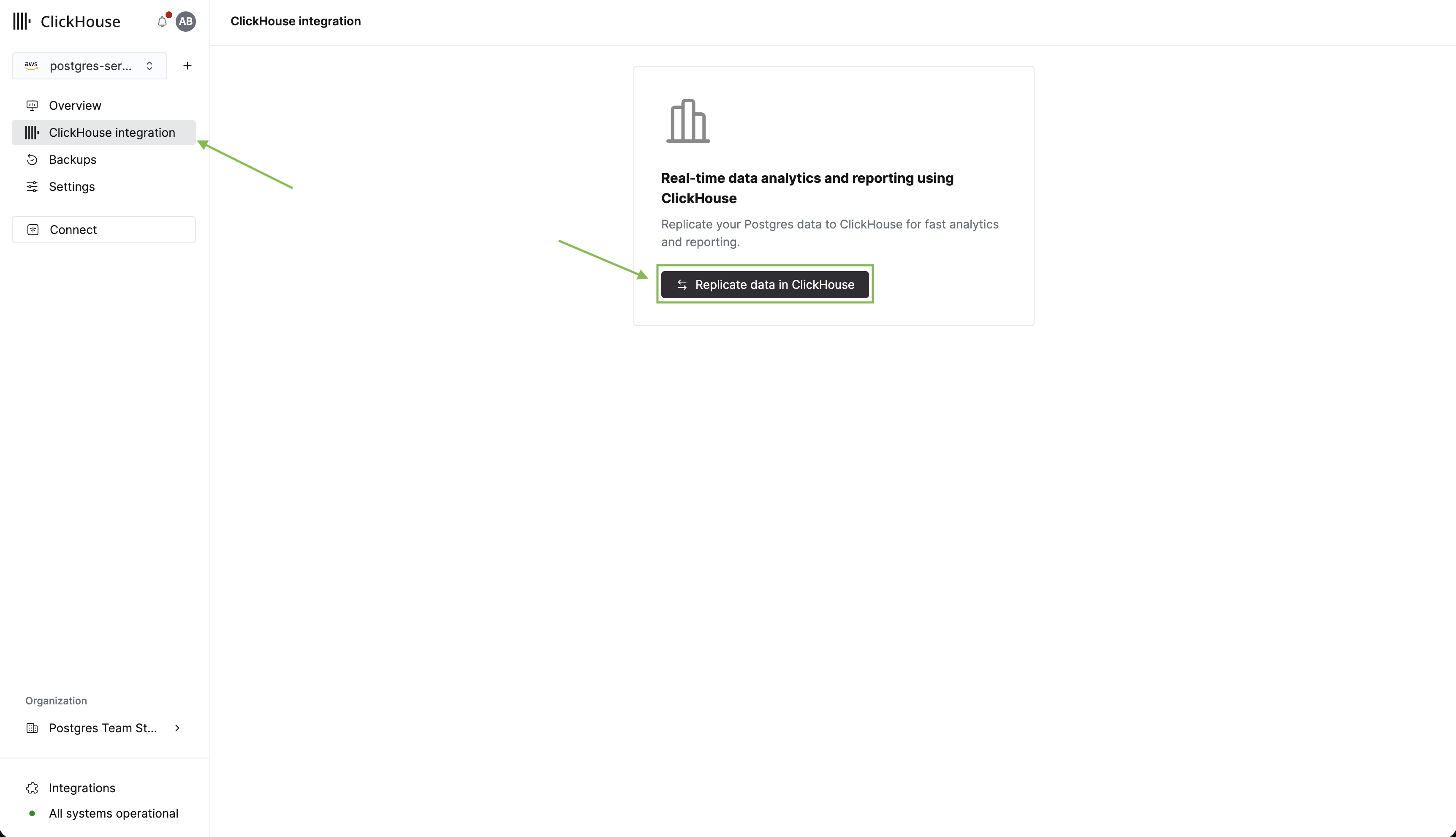
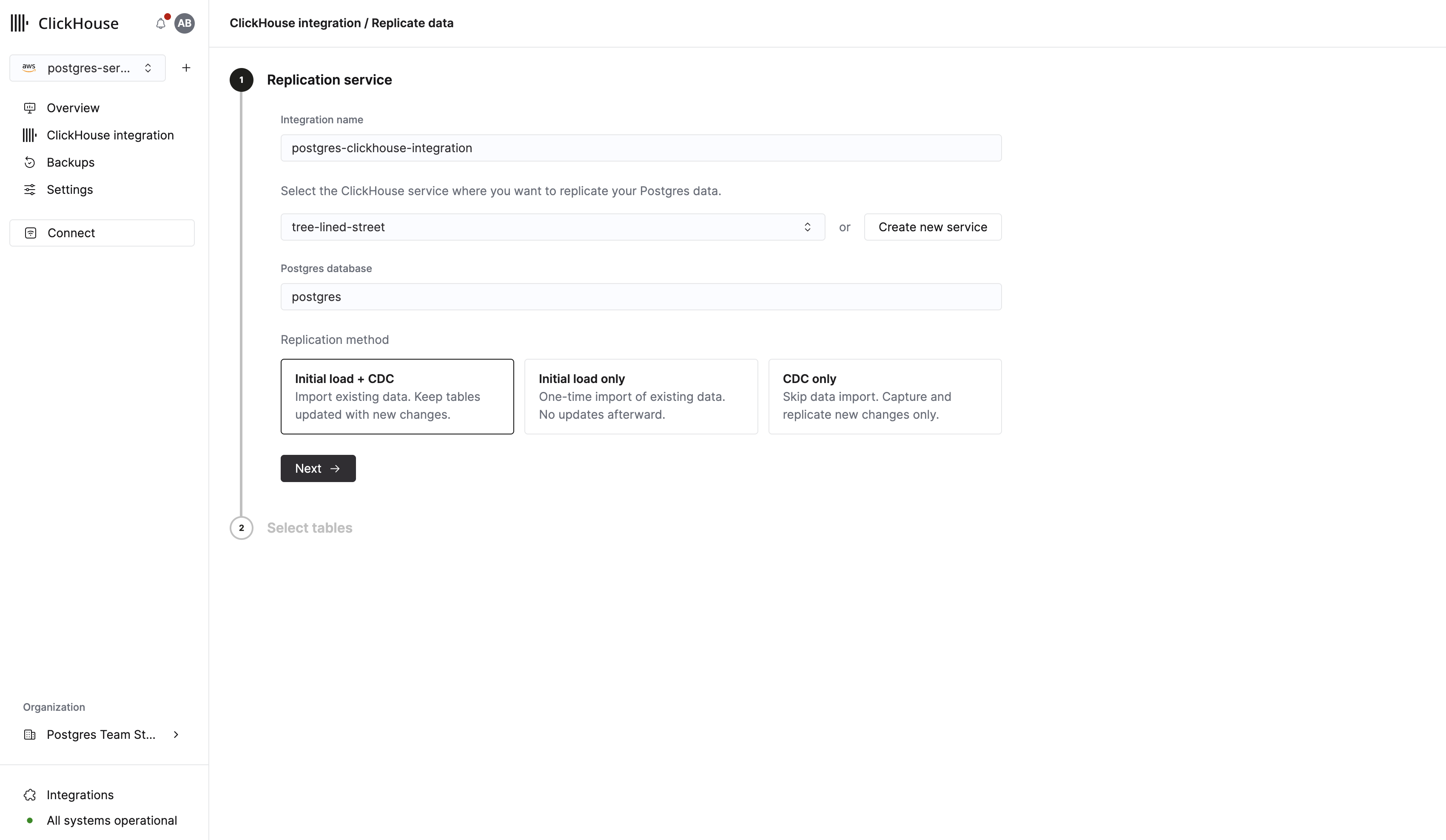
Postgres にテーブルとデータが用意できたので、分析用にテーブルを ClickHouse にレプリケートします。まずサイドバーの ClickHouse integration をクリックします。次に Replicate data in ClickHouse をクリックします。
表示されるフォームで、統合の名前を入力し、レプリケート先となる既存の ClickHouse インスタンスを選択できます。まだ ClickHouse インスタンスがない場合は、このフォームから直接作成できます。
Important
続行する前に、選択した ClickHouse サービスが Running 状態であることを確認してください。
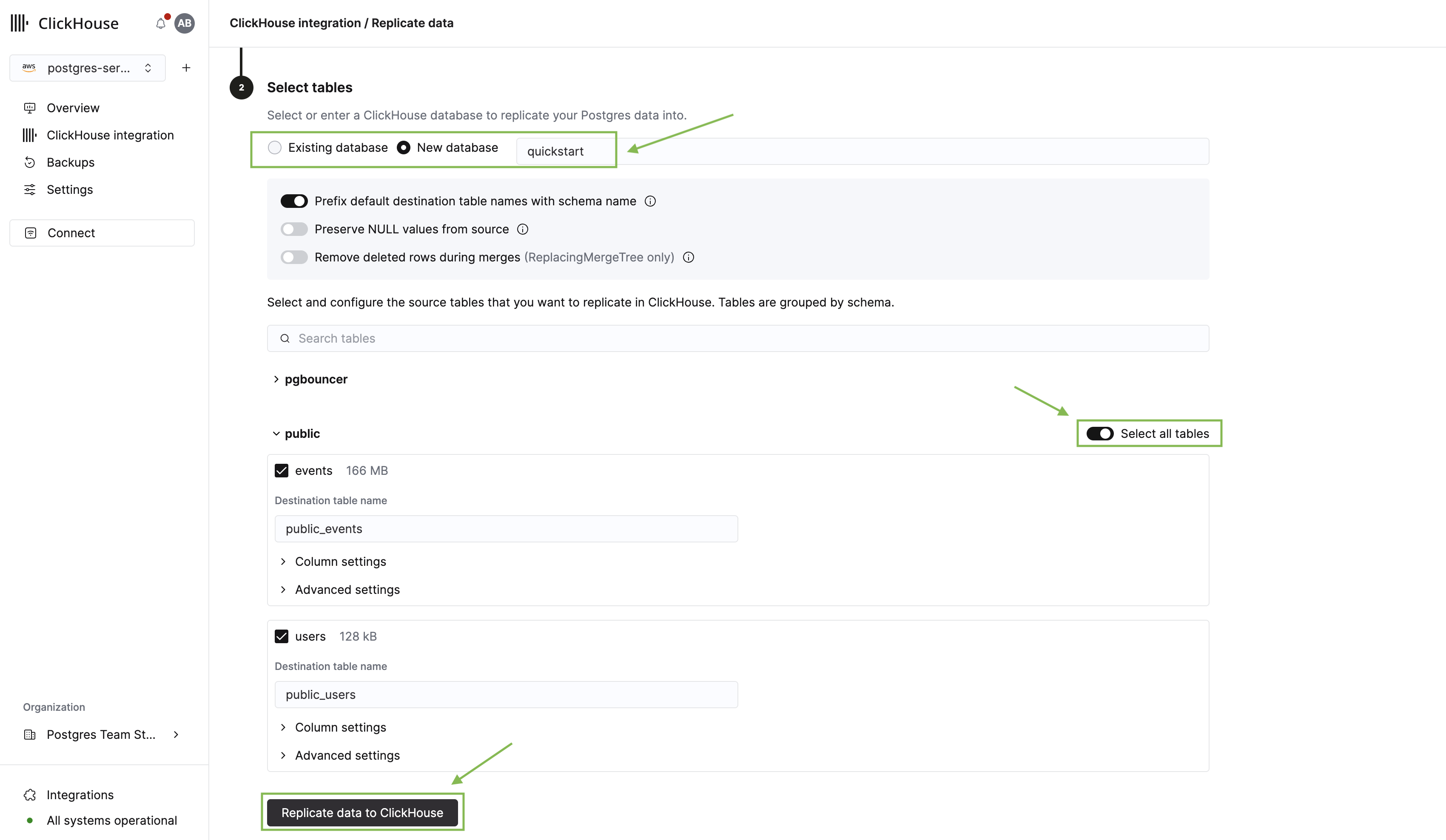
Next をクリックすると、テーブルピッカーが表示されます。ここで行うことは次のとおりです:
- レプリケート先の ClickHouse データベースを選択します。
- public スキーマを展開し、先ほど作成した users テーブルと events テーブルを選択します。
- Replicate data to ClickHouse をクリックします。
レプリケーション処理が開始され、統合の概要ページが表示されます。初回の統合では、初期インフラストラクチャのセットアップに 2~3 分かかることがあります。その間に、新しい pg_clickhouse 拡張機能を確認してみましょう。
Postgres から ClickHouse にクエリを実行する
pg_clickhouse 拡張機能を使うと、標準 SQL を使用して Postgres から直接 ClickHouse のデータにクエリを実行できます。つまり、アプリケーションはトランザクションデータと分析用データの両方に対して、Postgres を統合クエリレイヤーとして利用できます。詳細については、詳細なドキュメントを参照してください。
拡張機能を有効にします:
CREATE EXTENSION pg_clickhouse;
次に、ClickHouse への foreign server 接続を作成します。セキュアな接続には、ポート 8443 で http ドライバーを使用します。
CREATE SERVER ch FOREIGN DATA WRAPPER clickhouse_fdw
OPTIONS(driver 'http', host '<clickhouse_cloud_host>', dbname '<database_name>', port '8443');
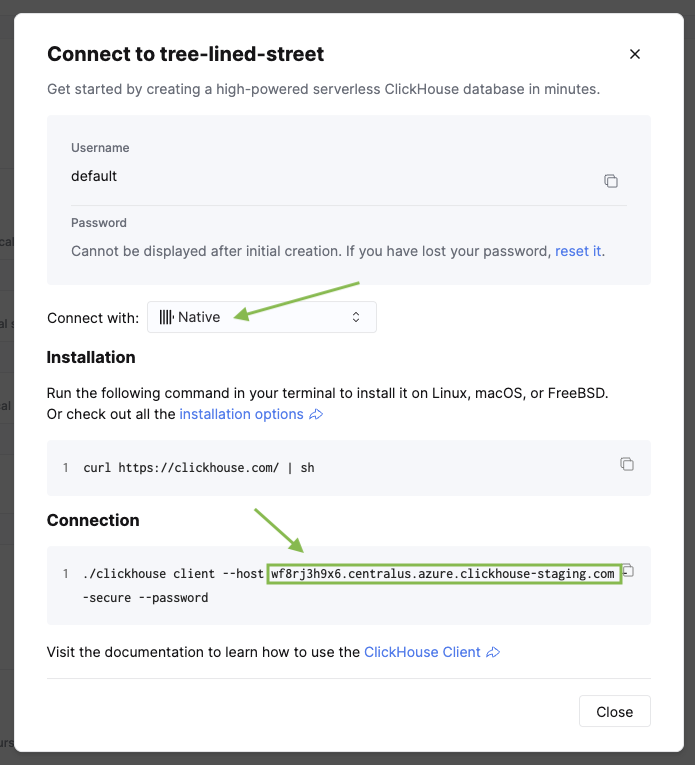
<clickhouse_cloud_host> を ClickHouse のホスト名に、<database_name> をレプリケーション設定時に選択したデータベース名に置き換えてください。ホスト名は、サイドバーの Connect をクリックすると ClickHouse サービス内で確認できます。
次に、Postgres のユーザーを ClickHouse サービスの認証情報にマッピングします:
CREATE USER MAPPING FOR CURRENT_USER SERVER ch
OPTIONS (user 'default', password '<clickhouse_password>');
次に、ClickHouse のテーブルを Postgres のスキーマにインポートします。
CREATE SCHEMA organization;
IMPORT FOREIGN SCHEMA "<database_name>" FROM SERVER ch INTO organization;
サーバーを作成したときと同じデータベース名で <database_name> を置き換えてください。
これで、Postgres クライアントからすべての ClickHouse テーブルを参照できるようになりました。
分析結果を確認する
統合ページに戻って状態を確認しましょう。初期レプリケーションが完了しているはずです。統合名をクリックすると、その詳細を確認できます。
サービス名をクリックすると、ClickHouse コンソールが開き、レプリケーションされたテーブルを確認できます。
ここでは、いくつかの分析用クエリを実行し、Postgres と ClickHouse 間のパフォーマンスを比較します。レプリケーションされたテーブルには、public_<table_name> という命名規則が使用されることに注意してください。
クエリ 1: アクティビティ別の上位ユーザー
このクエリは、複数の集計を行い、最もアクティブなユーザーを抽出します。
-- Via ClickHouse
SELECT
user_id,
COUNT(*) as total_events,
COUNT(DISTINCT event_type) as unique_event_types,
SUM(CASE WHEN event_type = 'purchase' THEN 1 ELSE 0 END) as purchases,
MIN(event_timestamp) as first_event,
MAX(event_timestamp) as last_event
FROM organization.public_events
GROUP BY user_id
ORDER BY total_events DESC
LIMIT 10;
user_id | total_events | unique_event_types | purchases | first_event | last_event
---------+--------------+--------------------+-----------+----------------------------+----------------------------
1 | 31439 | 5 | 3551 | 2025-01-22 22:40:45.612281 | 2026-01-21 22:40:45.612281
2 | 13235 | 4 | 1492 | 2025-01-22 22:40:45.612281 | 2026-01-21 22:40:45.612281
...
(10 rows)
Time: 163.898 ms -- ClickHouse
Time: 554.621 ms -- Same query on Postgres
クエリ 2: 国別およびプラットフォーム別のユーザーエンゲージメント
このクエリでは events と users を結合し、エンゲージメントに関する指標を算出します。
-- Via ClickHouse
SELECT
u.country,
u.platform,
COUNT(DISTINCT e.user_id) as users,
COUNT(*) as total_events,
ROUND(COUNT(*)::numeric / COUNT(DISTINCT e.user_id), 2) as events_per_user,
SUM(CASE WHEN e.event_type = 'purchase' THEN 1 ELSE 0 END) as purchases
FROM organization.public_events e
JOIN organization.public_users u ON e.user_id = u.user_id
GROUP BY u.country, u.platform
ORDER BY total_events DESC
LIMIT 10;
country | platform | users | total_events | events_per_user | purchases
---------+----------+-------+--------------+-----------------+-----------
USA | Android | 115 | 109977 | 956 | 12388
USA | Web | 108 | 105057 | 972 | 11847
USA | iOS | 83 | 84594 | 1019 | 9565
Germany | Android | 85 | 77966 | 917 | 8852
India | Android | 80 | 68095 | 851 | 7724
...
(10 rows)
Time: 170.353 ms -- ClickHouse
Time: 1245.560 ms -- Same query on Postgres
パフォーマンス比較:
| クエリ | Postgres (NVMe) | ClickHouse (pg_clickhouse 経由) | 高速化 |
|---|
| 上位ユーザー(5 種類の集計) | 555 ms | 164 ms | 3.4x |
| ユーザーエンゲージメント(JOIN + 集計) | 1,246 ms | 170 ms | 7.3x |
ClickHouse を選択するタイミング
この 1M 行のデータセットであっても、ClickHouse は JOIN と複数の集計を含む複雑な分析クエリに対して 3~7 倍高速なパフォーマンスを実現します。規模が(1 億行以上に)拡大すると、この差はさらに顕著になり、ClickHouse の列指向ストレージとベクトル化実行により 10~100 倍の高速化が得られる場合があります。
クエリの処理時間は、インスタンスのサイズ、サービス間のネットワーク遅延、データの特性、および現在の負荷によって変動します。
クリーンアップ
このクイックスタートで作成したリソースを削除するには、次の手順を実行します。
- まず、ClickHouse サービスから ClickPipe 連携を削除します。
- 次に、Cloud Console で Managed Postgres インスタンスを削除します。