ClickHouse Cloudを使用してManaged Postgresに移行する
ClickHouse Cloudには、外部のPostgreSQLデータベースをManaged Postgresサービスに移行するための組み込みインポートウィザードが用意されています。このウィザードは、ソース接続、schema のエクスポートとインポート、レプリケーション設定、テーブルの選択を、ガイド付きの5つのステップで処理します。
前提条件
- レプリケーション権限を持つユーザーで、移行元の PostgreSQL データベースにアクセスできること。
- 移行先として ClickHouse Managed Postgres サービスがあること。まだ利用していない場合は、クイックスタートを参照してください。
- ローカルマシンに
pg_dumpとpsqlがインストールされていること。どちらも標準の PostgreSQL クライアントツールに含まれています。
移行前の考慮事項
- DDL の伝播: 継続的レプリケーション (CDC) では、DML 操作と
ADD COLUMNが取り込まれます。DROP COLUMNやALTER COLUMNなどのその他の DDL 変更は伝播されないため、ターゲット側で手動で適用する必要があります。 - 外部キー制約: 外部キーのチェックによってインジェストが妨げられないように、ターゲットロールで一時的に
session_replication_role = replicaを設定します。これについては、以下のステップ 3 で説明します。
ステップ 1: ソースデータベースに接続する
ClickHouse Cloud コンソールを開き、Managed Postgres サービスを選択します。
左側のサイドバーで、Data sources をクリックします。
Start import をクリックします。
ソース PostgreSQL データベースの接続情報 (ホスト、ポート、ユーザー名、パスワード、データベース名) を入力します。必要に応じて、TLS を有効にします。
ソースデータベースへのプライベート接続が必要な場合は、SSH トンネリング を選択し、必要な SSH 情報を入力できます。これにより、公開されていないデータベースにも移行プロセスから安全に接続できます。
インジェスト方法を選択します。
- 初期ロード + CDC — 既存データをコピーした後、継続的な変更に合わせてターゲットを同期し続けます。
- 初期ロード only — 一回限りのコピーで、継続的なレプリケーションは行いません。
- CDC only — 初回コピーをスキップし、この時点以降の新しい変更のみをレプリケートします。
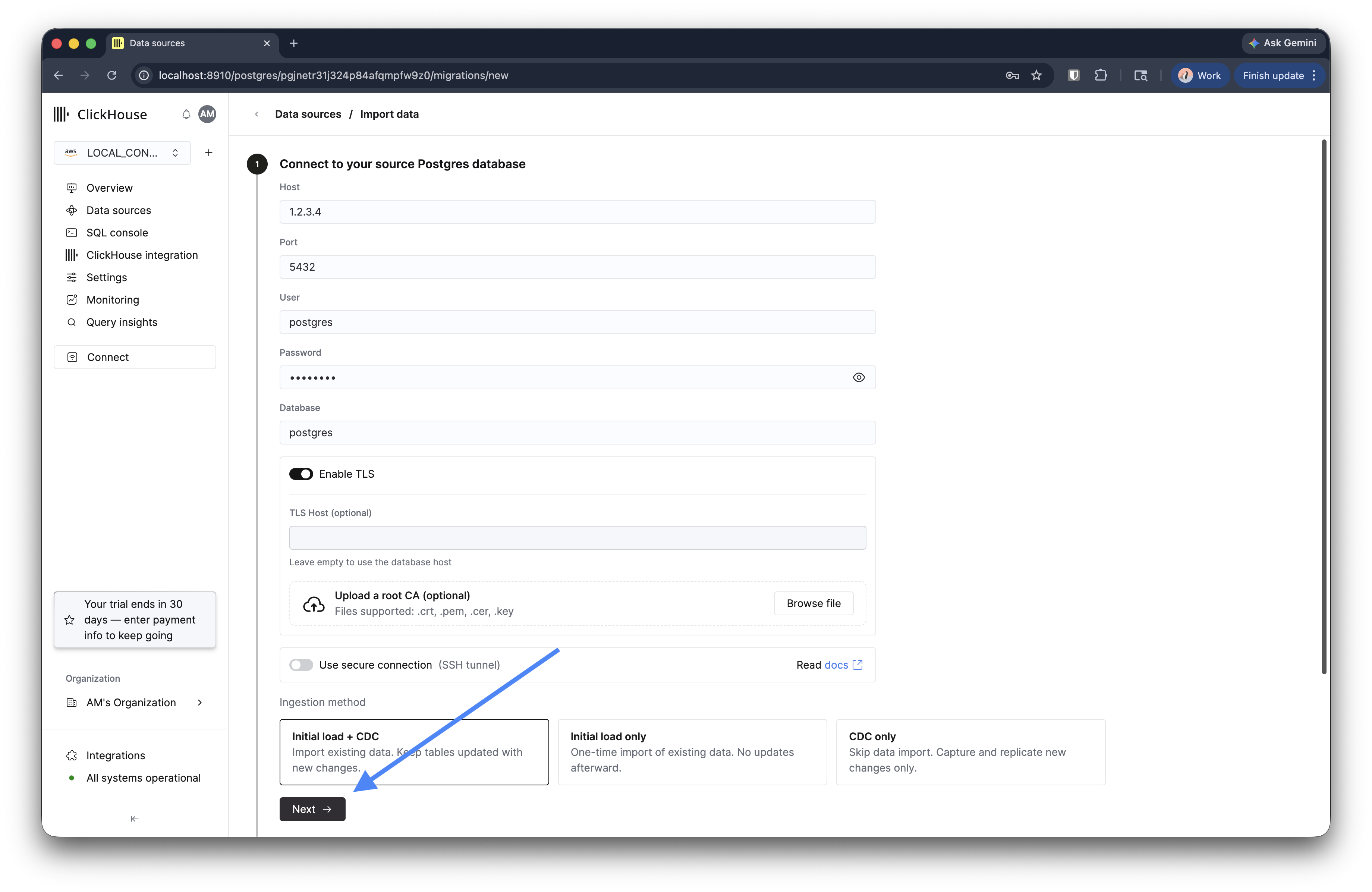
Next をクリックします。
ステップ 2: データベース schema をエクスポートする
ウィザードには、ソース接続の詳細があらかじめ入力された pg_dump 命令語が表示されます。これをターミナルで実行します。
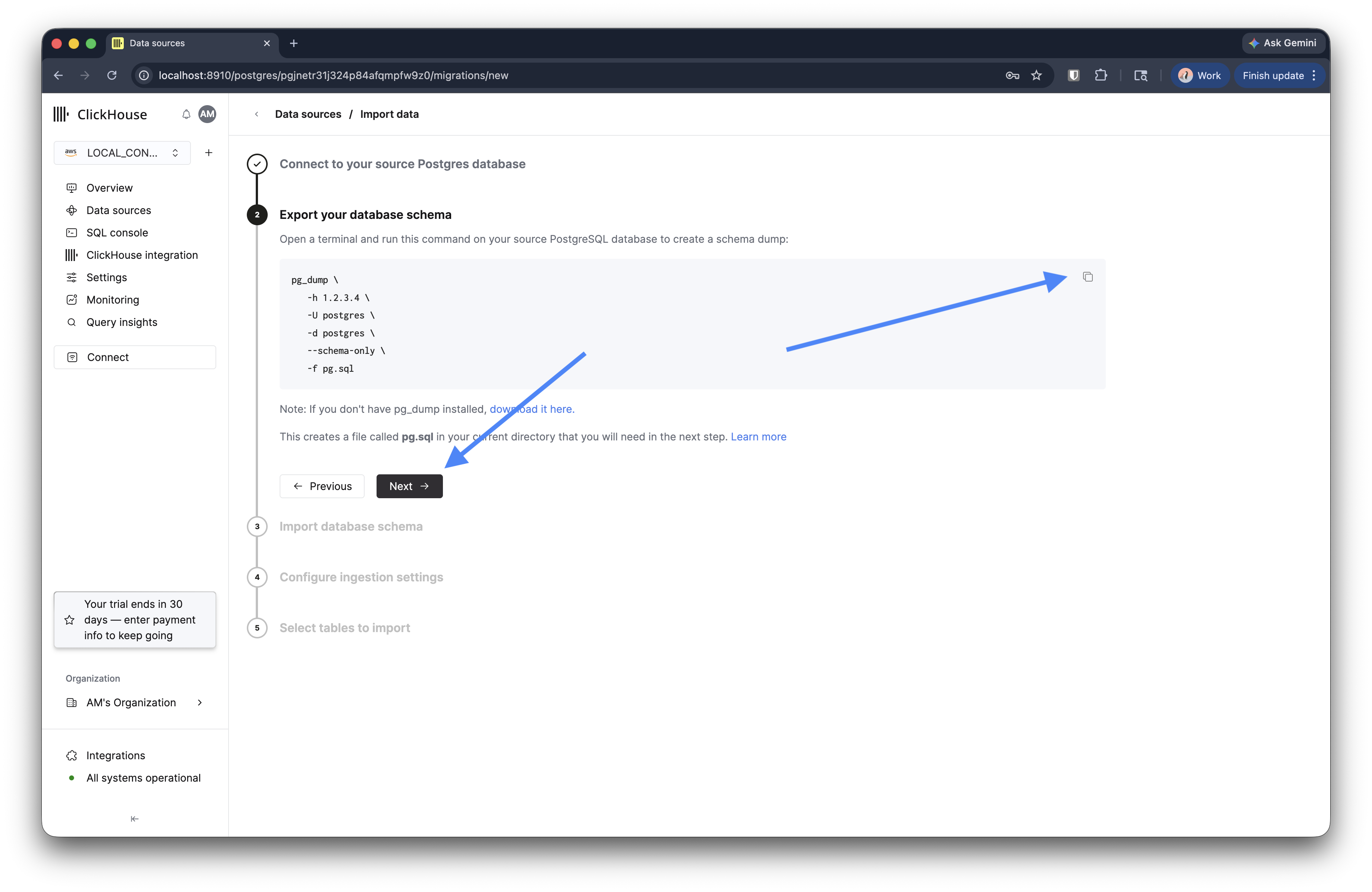
これにより、現在のディレクトリに pg.sql が作成されます。
Next をクリックします。
ステップ 3: Managed Postgres サービスに schema をインポートする
ドロップダウンから宛先データベースを選択するか、Create a new database をクリックして新しく作成します。
ウィザードに、schema ダンプを Managed Postgres サービスに適用するための psql 命令語が表示されます。これをターミナルで実行します。
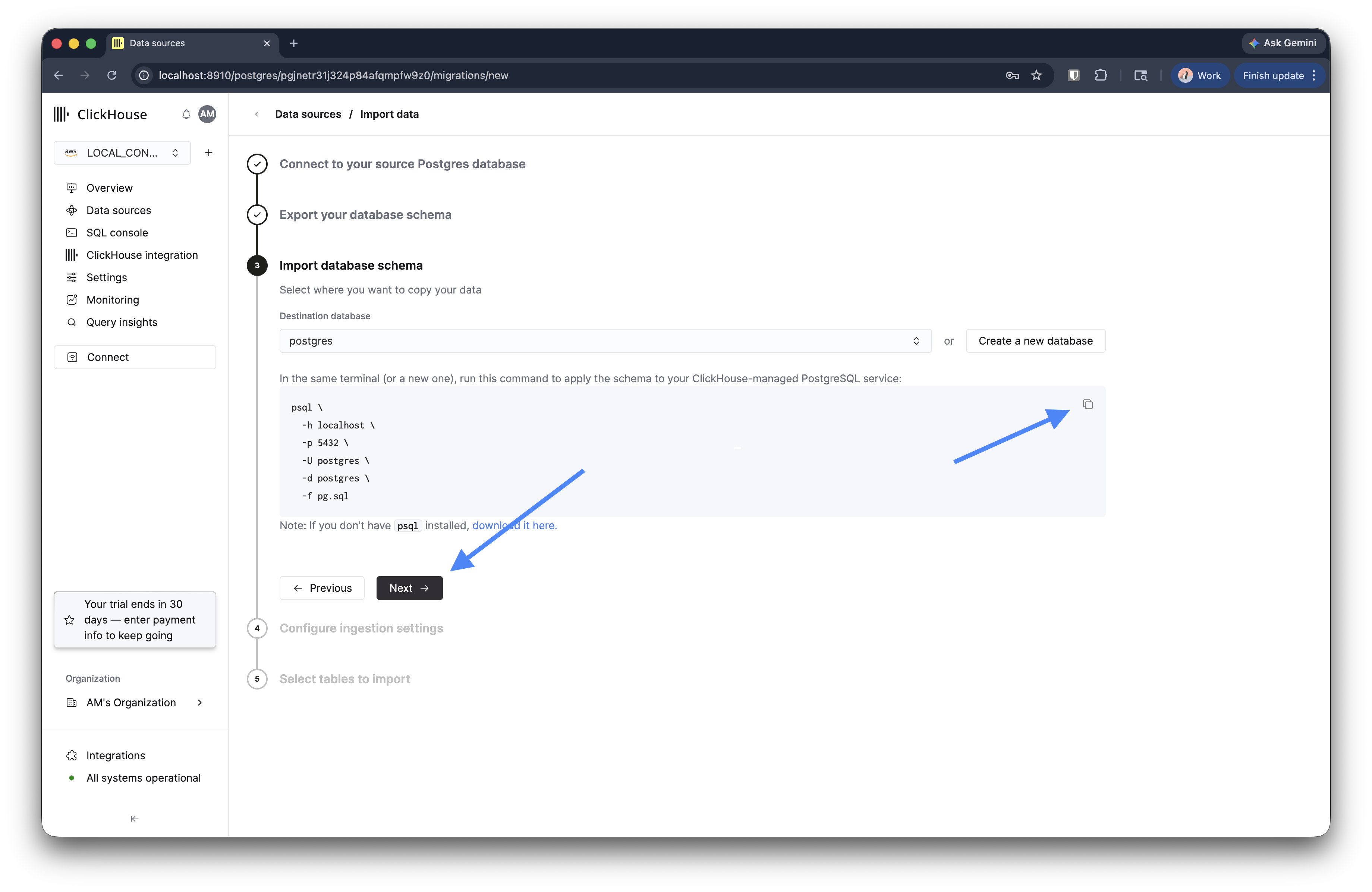

schema を適用したら、外部キー制約がインジェストを妨げないよう、対象のロールで session_replication_role を replica に設定します。

次へ をクリックします。
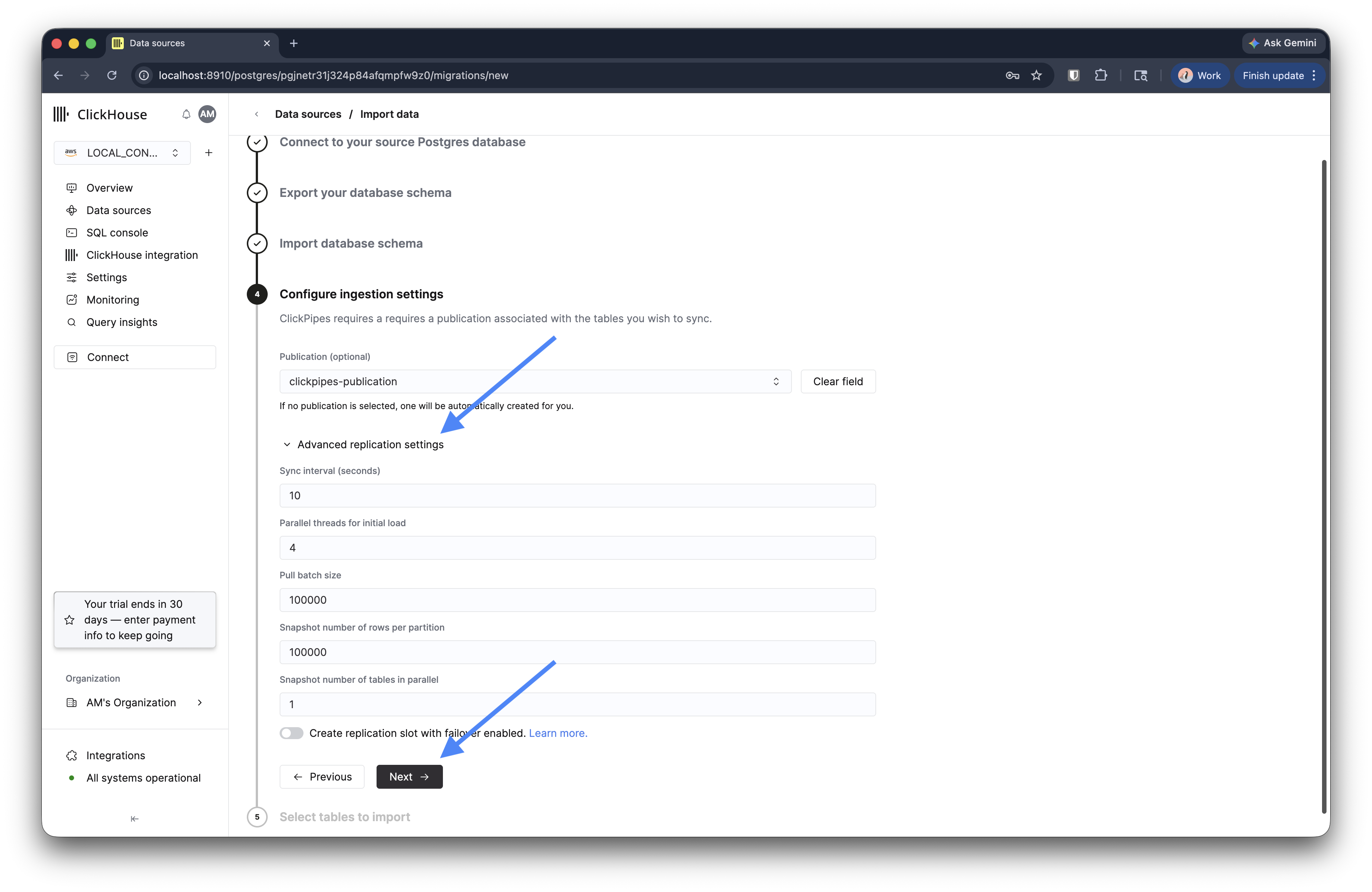
ステップ4: インジェスト設定を構成する
論理レプリケーションで使用するパブリケーションを指定します。空欄のままにすると、パブリケーションは自動的に作成されます。
スループットを調整するには、詳細なレプリケーション設定を展開します。
| 設定 | デフォルト | 説明 |
|---|---|---|
| 同期間隔 (秒) | 10 | レプリケーションスロットをポーリングする頻度 |
| 初期ロードの並列スレッド数 | 4 | Bulk Copy フェーズで使用するスレッド数 |
| プルバッチサイズ | 100,000 | レプリケーションの各バッチで取得する行数 |
| スナップショットのパーティションあたりの行数 | 100000 | 大規模テーブルのスナップショットにおけるパーティションサイズ |
| 並列スナップショット取得テーブル数 | 1 | 同時にスナップショットを取得するテーブル数 |
次へをクリックします。
Step 5: テーブルを選択
複製するテーブルを選択します。テーブルは schema ごとにまとめられています。個別にテーブルを選択するか、schema を展開してその中のテーブルをすべて選択します。
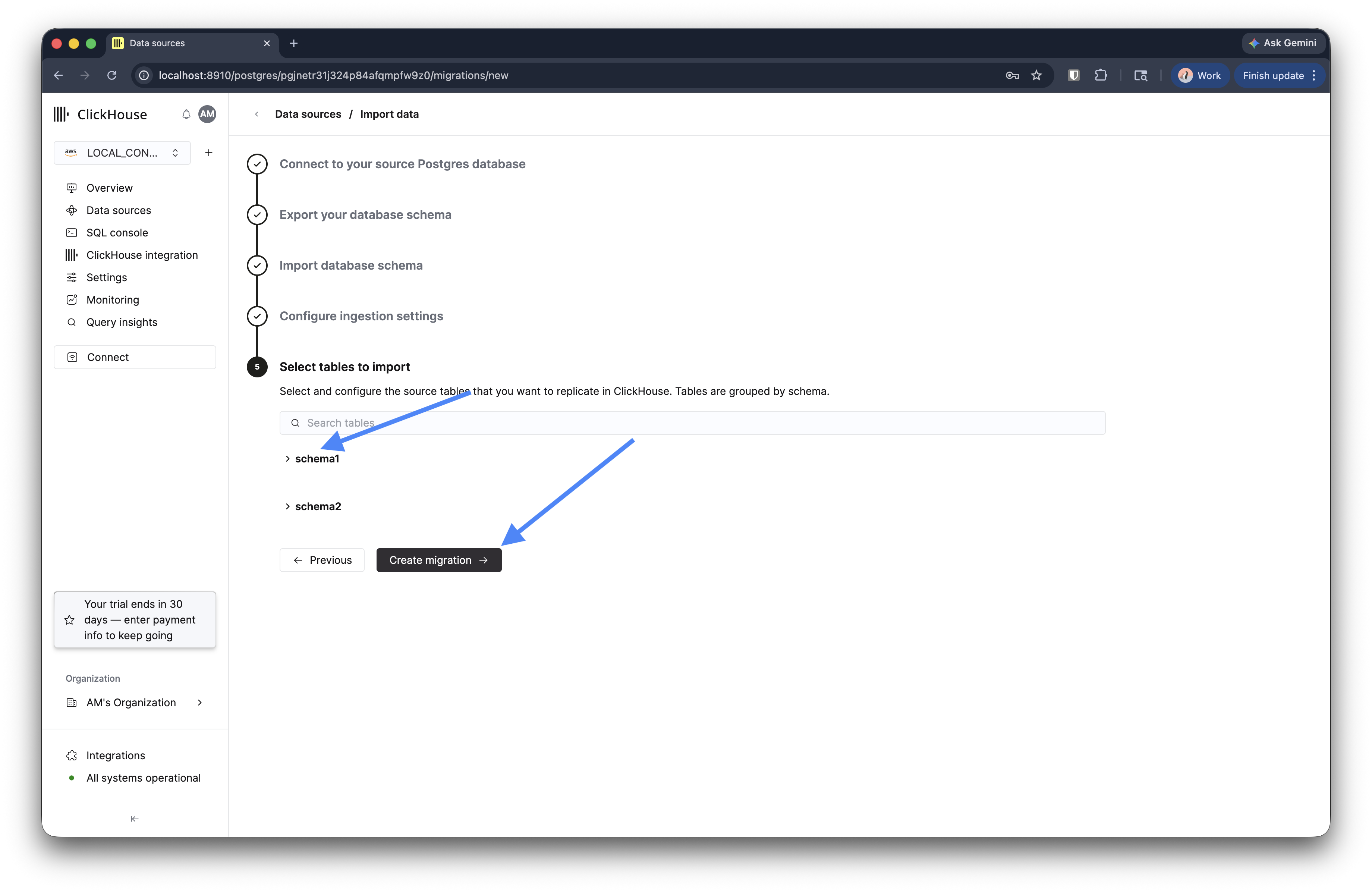
移行を作成 をクリックします。
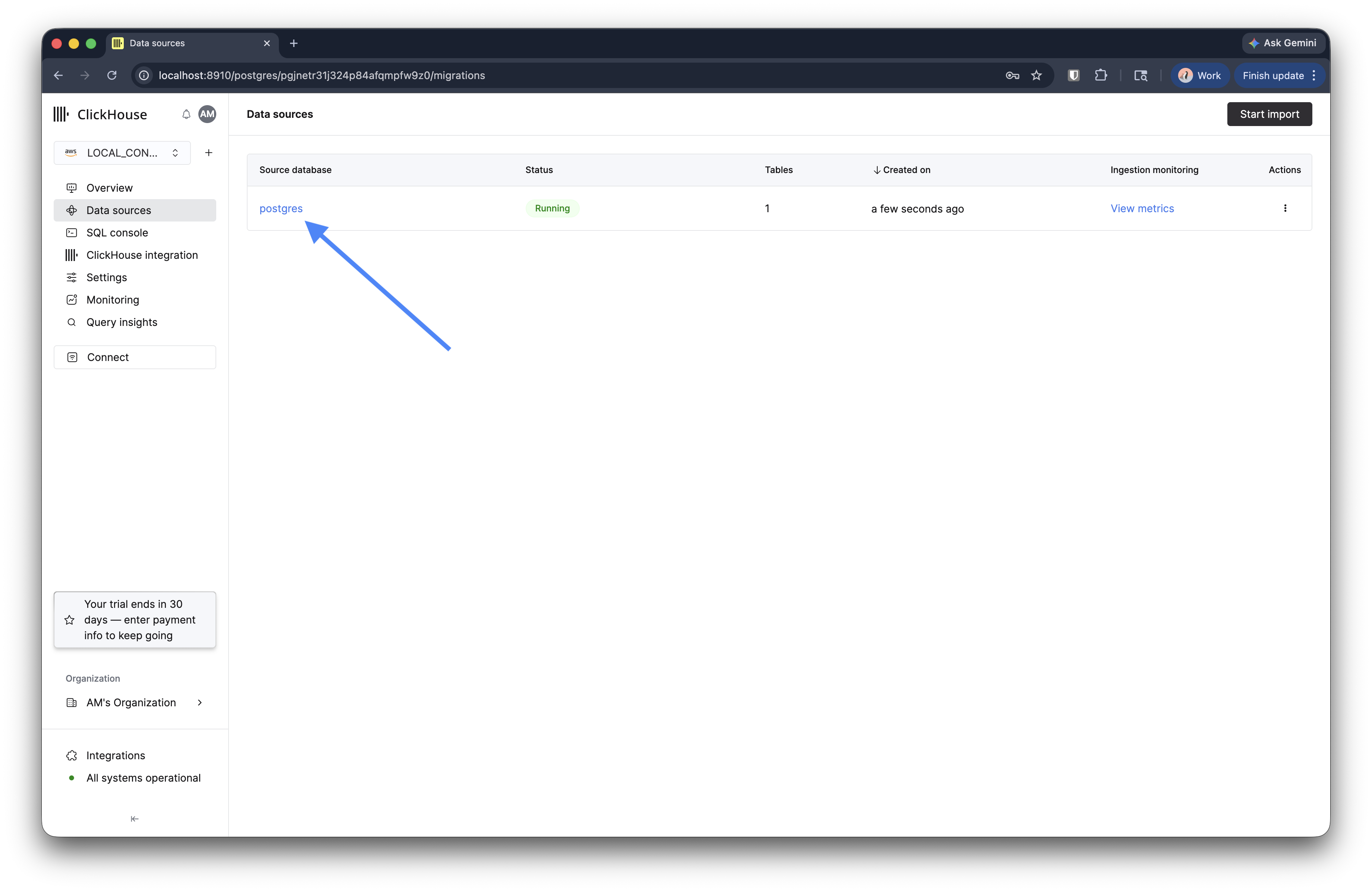
移行を監視する
移行を作成すると、Data sources に Running ステータスで表示されます。
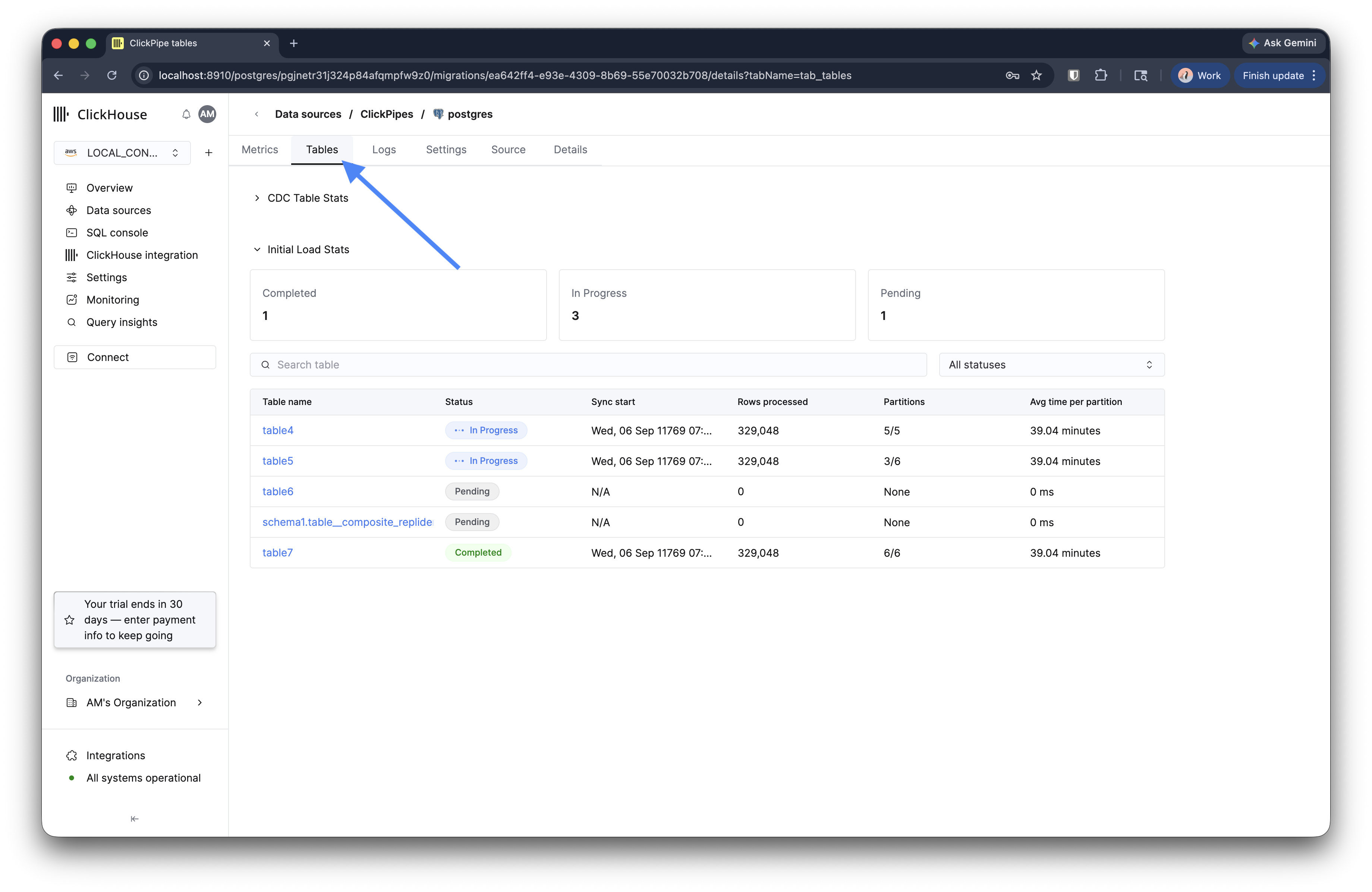
移行をクリックして詳細ビューを開きます。Tables タブには、処理済みの行、パーティション、パーティションあたりの平均時間など、各テーブルの初期ロードの進行状況が表示されます。CDC が開始されると、Metrics タブにレプリケーションの遅延とスループットが表示されます。
移行後の作業
初期ロードが完了し、CDC を使用している場合はレプリケーション遅延がほぼゼロになったら:
行数を検証します。 トラフィックを切り替える前に、重要なテーブルの行数をソースとターゲットの両方で抜き取り確認します:
ソース側への書き込みを停止します。 アプリケーションからの書き込みを一時停止します。切り替え時に読み取り専用モードを適用するには:
レプリケーションが追いついていることを確認します。 ソースとターゲットの最新行を比較します。
制約を再度有効化し、レプリケーションロールを復元します。 インポート中に後回しにした索引、制約、トリガーを適用した後、ターゲットロールをリセットします。
シーケンスをリセットします。 各テーブルの現在の最大値に合わせてシーケンスを調整します。
アプリケーショントラフィックを切り替えます。 読み取り先と書き込み先を Managed Postgres サービスに切り替え、エラー、制約違反、レプリケーションの健全性を監視します。
クリーンアップします。 切り替えを完了し、新しいサービスが正常であることを確認したら、Data sources から移行を削除します。CDC を使用した場合は、リソースを解放するためにソース側のレプリケーションスロットを削除します:
