DataStore: SQL 最適化を備えた pandas 互換 API
DataStore は、chDB の pandas 互換 API であり、なじみのある pandas DataFrame インターフェイスに SQL クエリ最適化の強力な機能を組み合わせたものです。pandas スタイルのコードを書いて、ClickHouse レベルのパフォーマンスを得ることができます。
主な機能
- pandas 互換性: 209 個の pandas DataFrame メソッド、56 個の
.strメソッド、42 個以上の.dtメソッド - SQL 最適化: 操作は自動的に最適化された SQL クエリにコンパイルされます
- 遅延評価: 結果が必要になるまで処理を遅延評価します
- 630 以上の API メソッド: データ操作のための包括的な API 群
- ClickHouse 拡張機能: pandas にはない追加アクセサ(
.arr、.json、.url、.ip、.geo)
アーキテクチャ
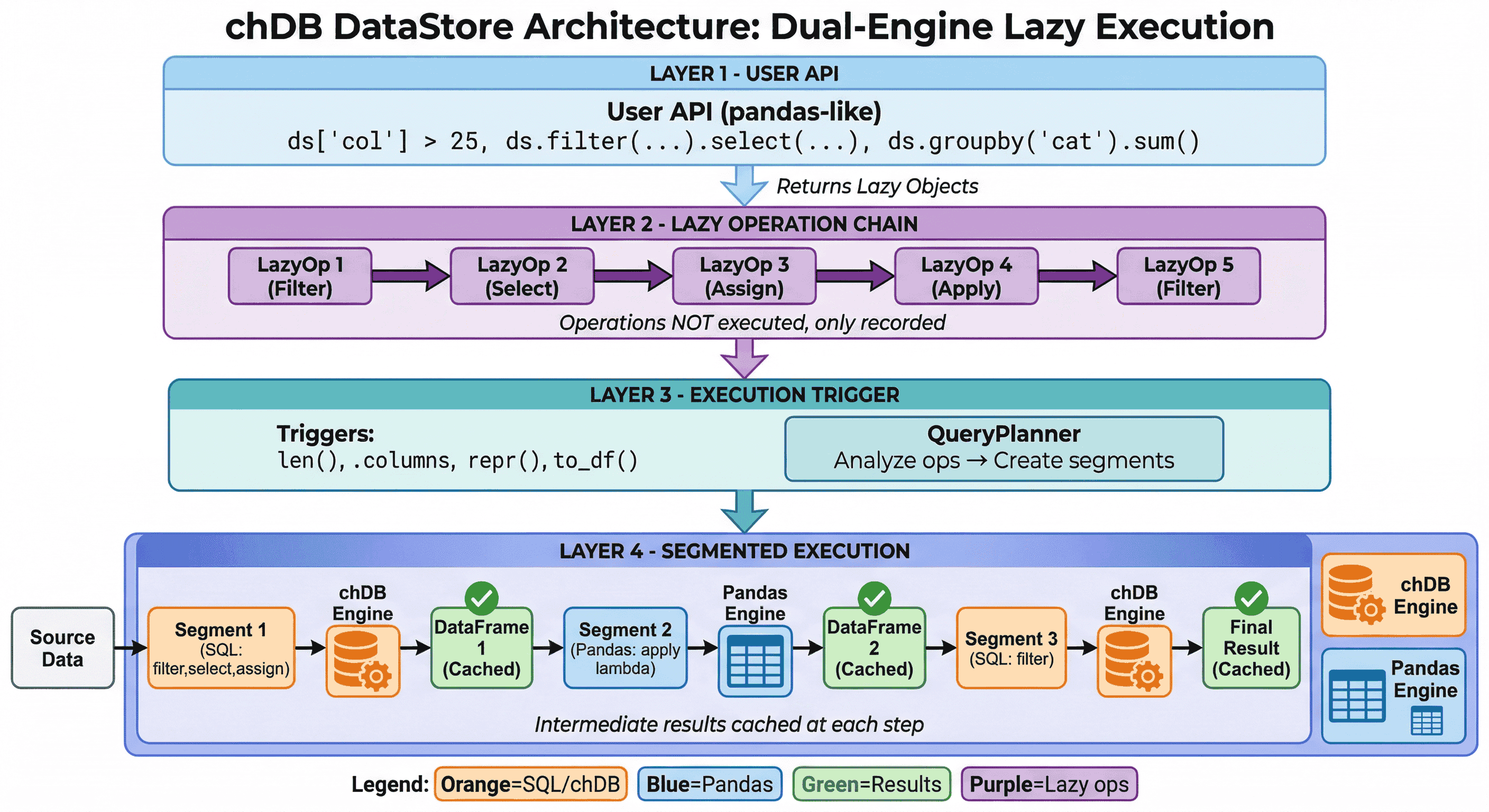
DataStore は、遅延評価 (lazy evaluation) と デュアルエンジン実行 (dual-engine execution) を採用しています。
- 遅延処理チェーン: 処理は即時には実行されず、まず記録されるだけです
- スマートなエンジン選択: QueryPlanner が各セグメントを最適なエンジン (SQL 用の chDB、複雑な処理用の Pandas) にルーティングします
- 中間キャッシュ: 各ステップの結果をキャッシュし、反復的な探索を高速化します
詳細は Execution Model を参照してください。
Pandas からの1行移行
既存の pandas コードは一切変更せずにそのまま動作しますが、実行は ClickHouse エンジン上で行われます。
パフォーマンス比較
DataStore は、特に集計や複雑なパイプライン処理において、pandas と比べて大幅なパフォーマンス向上を実現します。
| Operation | Pandas | DataStore | Speedup |
|---|---|---|---|
| GroupBy count | 347ms | 17ms | 19.93x |
| Complex pipeline | 2,047ms | 380ms | 5.39x |
| Filter+Sort+Head | 1,537ms | 350ms | 4.40x |
| GroupBy agg | 406ms | 141ms | 2.88x |
1,000 万行のデータに対するベンチマーク。詳細は benchmark script および Performance Guide を参照してください。
DataStore を使用するタイミング
次のような場合は DataStore を使用します:
- 大規模なデータセット(数百万行)を扱うとき
- 集計や groupby 操作を実行するとき
- ファイル、データベース、またはクラウドストレージからデータをクエリするとき
- 複雑なデータパイプラインを構築するとき
- pandas API と同等の操作性で、より高いパフォーマンスが必要なとき
次のような場合は生の SQL API を使用します:
- SQL を直接記述したいとき
- クエリの実行をきめ細かく制御する必要があるとき
- pandas API からは利用できない ClickHouse 固有の機能を扱うとき
機能比較
| 機能 | Pandas | Polars | DuckDB | DataStore |
|---|---|---|---|---|
| Pandas API 互換性 | - | 部分的 | なし | 完全 |
| 遅延評価 | なし | あり | あり | あり |
| SQL クエリサポート | なし | あり | あり | あり |
| ClickHouse 関数 | なし | なし | なし | あり |
| 文字列/DateTime アクセサ | あり | あり | なし | あり + 追加機能 |
| Array/JSON/URL/IP/Geo | なし | 部分的 | なし | あり |
| ファイルへの直接クエリ実行 | なし | あり | あり | あり |
| Cloud ストレージサポート | なし | 限定的 | あり | あり |
API 統計
| カテゴリ | 件数 | カバレッジ |
|---|---|---|
| DataFrame メソッド | 209 | pandas の 100% |
| Series.str アクセサ | 56 | pandas の 100% |
| Series.dt アクセサ | 42+ | 100%+(ClickHouse 拡張分を含む) |
| Series.arr アクセサ | 37 | ClickHouse 固有 |
| Series.json アクセサ | 13 | ClickHouse 固有 |
| Series.url アクセサ | 15 | ClickHouse 固有 |
| Series.ip アクセサ | 9 | ClickHouse 固有 |
| Series.geo アクセサ | 14 | ClickHouse 固有 |
| API メソッド総数 | 630+ | - |
ドキュメントのナビゲーション
はじめに
- クイックスタート - インストールと基本的な使い方
- Pandas からの移行 - 手順を追った移行ガイド
API リファレンス
- Factory Methods - さまざまなソースからの DataStore の作成
- Query Building - SQL スタイルのクエリ構築
- Pandas Compatibility - 209 個の pandas 互換メソッド
- Accessors - 文字列、DateTime、Array、JSON、URL、IP、Geo アクセサー
- Aggregation - 集約関数とウィンドウ関数
- I/O Operations - データの読み取りと書き込み
高度なトピック
- Execution Model - 遅延評価とキャッシュ
- Class Reference - 完全な API リファレンス
設定とデバッグ
- 設定 - すべての設定オプション
- パフォーマンスモード - 最大スループットを実現する SQL ファーストのモード
- デバッグ - EXPLAIN、プロファイリング、ログ出力
Pandas ユーザーガイド
- Pandas Cookbook - 一般的なパターン
- Key Differences - pandas との主な違い
- Performance Guide - 最適化のためのガイド
- SQL for Pandas Users - pandas の操作がどのような SQL に対応しているかを理解する
簡単な例
次のステップ
- DataStore は初めてですか? まずは クイックスタートガイド から始めてください
- pandas から移行しますか? 移行ガイド をお読みください
- さらに詳しく知りたいですか? API リファレンス をご覧ください
