INSERT 戦略の選び方
効率的なデータのインジェストは、高性能な ClickHouse デプロイメントの基盤となります。適切なデータ挿入戦略を選択することで、スループット、コスト、および信頼性は大きく左右されます。本セクションでは、ワークロードに最適な判断を行うためのベストプラクティス、トレードオフ、および設定オプションについて説明します。
以下の内容は、クライアント経由で ClickHouse にデータをプッシュしていることを前提としています。組み込みのテーブル関数 s3 や gcs などを使用して ClickHouse にデータをプルしている場合は、「S3 への挿入および読み取りパフォーマンスの最適化」ガイドを参照することを推奨します。
デフォルトでは同期インサート
デフォルトでは、ClickHouse へのインサートは同期的に行われます。各インサートクエリは、メタデータおよびインデックスを含むストレージパーツを即座にディスク上に作成します。
そうでない場合は、下記の非同期インサートを参照してください。
以下では、ClickHouse の MergeTree におけるインサートの仕組みを簡単に確認します。
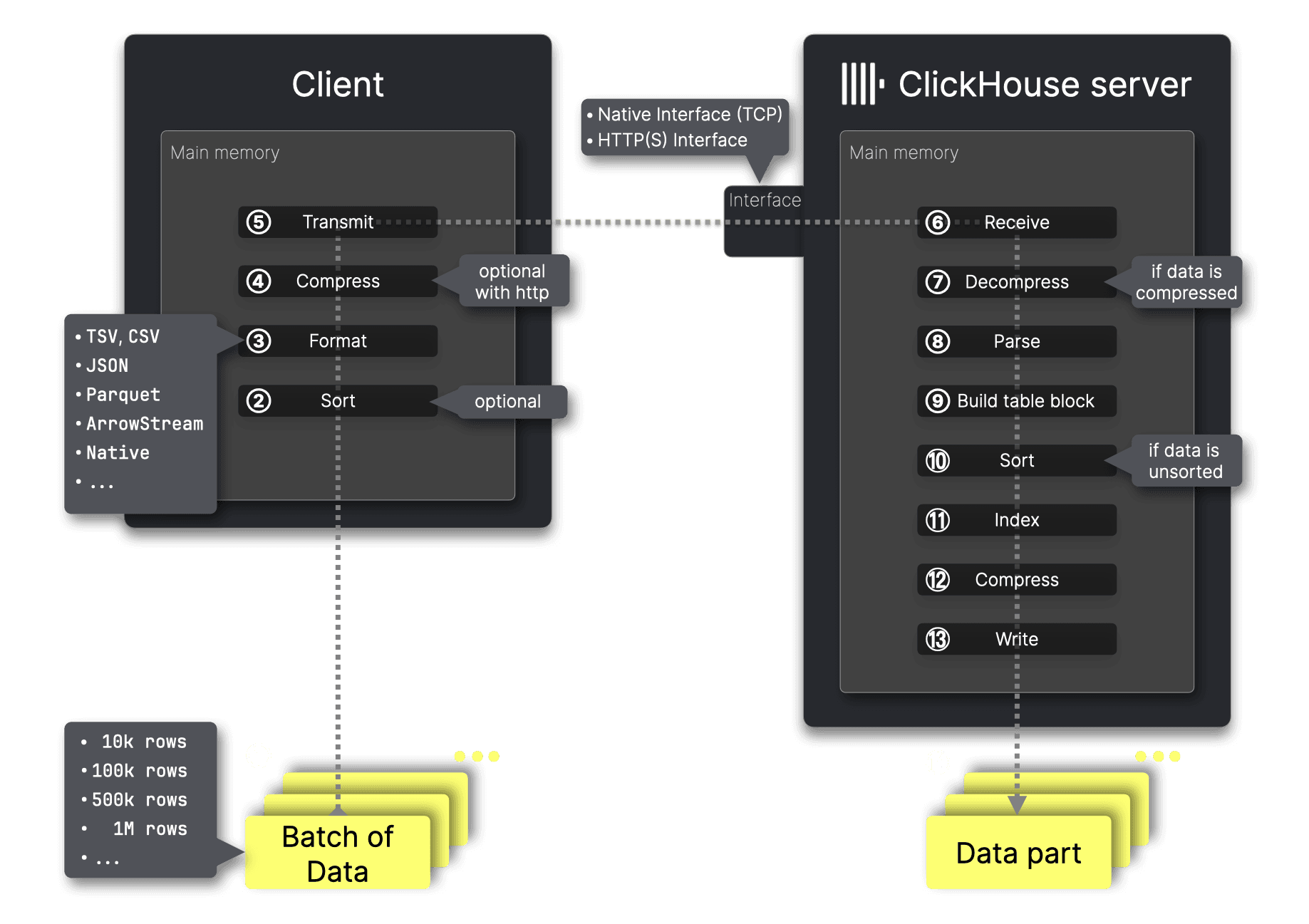
クライアント側のステップ
最適なパフォーマンスのためには、データを①バッチ化する必要があり、バッチサイズが最初の検討事項になります。
ClickHouse はインサートされたデータを、テーブルの主キー列で並べ替えた状態でディスクに格納します。2つ目の検討事項は、サーバーに送信する前にデータを②事前ソートするかどうかです。バッチが主キー列で事前にソートされた状態で届いた場合、ClickHouse はインジェストを高速化するために ⑩ のソートステップを省略できます。
インジェストするデータにあらかじめ決まったフォーマットがない場合、重要な検討事項はフォーマットの選択です。ClickHouse は70 以上のフォーマットでのデータインサートをサポートしています。ただし、ClickHouse のコマンドラインクライアントや各種プログラミング言語のクライアントを使用する際には、この選択はしばしば自動的に処理されます。必要であれば、この自動選択を明示的に上書きすることもできます。
次の主要な検討事項は、ClickHouse サーバーへの送信前にデータを④圧縮するかどうかです。圧縮により転送サイズが減り、ネットワーク効率が向上するため、とくに大規模なデータセットではデータ転送が高速化され、帯域幅使用量も削減されます。
データは⑤ ClickHouse のネットワークインターフェイス、すなわち native または HTTP インターフェイスのいずれかに送信されます (これらはこの記事の後半で比較します) 。
サーバー側のステップ
⑥ データを受信したあと、ClickHouse は圧縮が使用されていた場合に ⑦ それを解凍し、その後 ⑧ 元の送信フォーマットからパースします。
そのフォーマット済みデータの値と対象テーブルの DDL ステートメントを用いて、ClickHouse は MergeTree 形式のインメモリブロックを ⑨ 構築し、事前にソートされていない場合は主キー列で行を ⑩ ソートし、⑪ 疎な主キーインデックスを作成し、⑫ 列単位の圧縮を適用し、最後にデータをディスクに ⑬ 書き込み、新しい ⑭ データパーツを作成します。
同期インサート時はデータをバッチ化する
上記のメカニズムからわかるように、挿入サイズに関係なく一定のオーバーヘッドが発生するため、バッチサイズは取り込みスループットを最適化するうえで最も重要な要素になります。挿入をバッチ化することで、総挿入時間に占めるオーバーヘッドの割合が減少し、処理効率が向上します。
データは少なくとも 1,000 行単位、理想的には 10,000~100,000 行のバッチで挿入することを推奨します。回数を減らして 1 回あたりの挿入を大きくすることで、書き込まれるパーツ数が減少し、マージ処理の負荷が抑えられ、システム全体のリソース使用量も低下します。
同期挿入戦略を有効に機能させるには、このクライアント側でのバッチ化が必須です。
クライアント側でデータをバッチ化できない場合、ClickHouse はバッチ化をサーバー側に移す非同期挿入をサポートしています(非同期挿入を参照)。
挿入のサイズに関わらず、挿入クエリの数は 1 秒あたり 1 件程度に抑えることを推奨します。この推奨の理由は、作成されたパーツがバックグラウンドでより大きなパーツへマージされる(読み取りクエリ向けにデータを最適化する)ためであり、1 秒あたりに送信される挿入クエリが多すぎると、バックグラウンドでのマージ処理が新規パーツ数に追いつけなくなる可能性があるためです。ただし、非同期挿入を使用する場合は、1 秒あたりの挿入クエリ数をより高くしても問題ありません(非同期挿入を参照)。
冪等なリトライを確保する
同期インサートは冪等でもあります。MergeTree エンジンを使用する場合、ClickHouse はデフォルトでインサートの重複排除を行います。これにより、次のようなあいまいな障害ケースから保護されます。
- インサートは成功したが、ネットワークの中断によりクライアントが応答を受信できなかった。
- インサートがサーバー側で失敗し、タイムアウトした。
いずれの場合も、バッチの内容と順序が同一である限り、インサートをリトライしても安全です。このため、クライアントはデータを変更したり並べ替えたりせず、一貫した方法でリトライすることが極めて重要です。
適切なインサート先を選択する
シャード構成のクラスタでは、次の 2 つの選択肢があります。
- MergeTree または ReplicatedMergeTree テーブルに直接インサートする。これは、クライアントがシャード間でロードバランシングを行える場合に最も効率的なオプションです。
internal_replication = trueの場合、ClickHouse はレプリケーションを透過的に処理します。 - Distributed テーブルにインサートする。これにより、クライアントは任意のノードにデータを送信し、ClickHouse に正しいシャードへの転送を任せることができます。これはよりシンプルですが、追加の転送ステップがあるため、パフォーマンスはわずかに低下します。
internal_replication = trueはこの場合でも推奨されます。
ClickHouse Cloud では、すべてのノードが同じ単一の分片に対して読み書きを行います。インサートはノード間で自動的にバランスされるため、公開されているエンドポイントに対してインサートを送信するだけでかまいません。
適切なフォーマットを選択する
ClickHouse における効率的なデータのインジェストには、適切な入力フォーマットの選択が重要です。70 以上のフォーマットがサポートされているため、最も高性能なオプションを選ぶことで、INSERT の速度、CPU およびメモリ使用量、そしてシステム全体の効率に大きな影響を与えられます。
データエンジニアリングやファイルベースのインポートでは柔軟性が有用ですが、アプリケーションではパフォーマンス重視のフォーマットを優先すべきです。
- Native フォーマット(推奨):最も効率的。カラム指向で、サーバー側で必要なパースが最小限。Go および Python クライアントでデフォルトで使用されます。
- RowBinary:効率的な行指向フォーマット。クライアント側でカラム指向への変換が難しい場合に最適。Java クライアントで使用されます。
- JSONEachRow:扱いやすい一方で、パースコストが高いフォーマット。低ボリュームなユースケースや、迅速な連携用途に適しています。
圧縮を使用する
圧縮は、ネットワークオーバーヘッドを削減し、INSERT を高速化し、ClickHouse におけるストレージコストを抑えるうえで重要な役割を果たします。効果的に利用することで、データフォーマットやスキーマを変更することなく、インジェスト性能を向上できます。
INSERT データを圧縮すると、ネットワーク越しに送信されるペイロードサイズが小さくなり、帯域幅の使用量を最小限に抑えつつ、送信を高速化できます。
INSERT において圧縮は、すでに ClickHouse の内部カラムナストレージモデルに整合している Native フォーマットと組み合わせた場合に特に効果的です。この構成では、サーバーはデータを効率的に伸長し、最小限の変換で直接保存できます。
速度重視には LZ4、圧縮率重視には ZSTD を使用する
ClickHouse はデータ送信時に複数の圧縮コーデックをサポートしています。代表的な 2 つの選択肢は次のとおりです。
- LZ4:高速かつ軽量。CPU オーバーヘッドを最小限に抑えつつ、データサイズを大きく削減できるため、高スループットな INSERT に理想的であり、ほとんどの ClickHouse クライアントでデフォルトとして使用されています。
- ZSTD:より高い圧縮率を提供しますが、CPU 負荷が増加します。リージョン間やクラウドプロバイダ間など、ネットワーク転送コストが高いシナリオで有用ですが、クライアント側の計算量とサーバー側の伸長時間がわずかに増加します。
ベストプラクティス:帯域幅が制約されている、またはデータの外向き転送コストが発生する場合を除き、LZ4 を使用してください。そのような場合には ZSTD の利用を検討します。
FastFormats ベンチマーク のテストでは、LZ4 圧縮された Native の INSERT によりデータサイズが 50% 以上削減され、5.6 GiB のデータセットに対してインジェスト時間が 150 秒から 131 秒に短縮されました。ZSTD に切り替えると、同じデータセットは 1.69 GiB まで圧縮されましたが、サーバー側の処理時間はわずかに増加しました。
圧縮によりリソース使用量が削減される
圧縮はネットワークトラフィックを削減するだけでなく、サーバー側の CPU およびメモリ効率も向上させます。圧縮データであれば、ClickHouse が受信するバイト数が少なくなり、大きな入力をパースする時間も短縮されます。この利点は、オブザーバビリティのように多数のクライアントから同時にインジェストを行うシナリオで特に重要です。
圧縮が CPU とメモリに与える影響は、LZ4 の場合は小さく、ZSTD の場合は中程度です。負荷がかかった状態でも、データ量が削減されることでサーバー側の効率は向上します。
圧縮をバッチ処理および効率的な入力フォーマット(Native など)と組み合わせることで、インジェスト性能を最大化できます。
ネイティブインターフェイス(例:clickhouse-client)を使用する場合、LZ4 圧縮はデフォルトで有効になっています。必要に応じて設定により ZSTD に切り替えることもできます。
HTTP インターフェイス を使用する場合は、Content-Encoding ヘッダーを使用して圧縮を適用します(例:Content-Encoding: lz4)。送信前にペイロード全体を圧縮しておく必要があります。
低コストであれば事前ソートを行う
挿入前にデータを主キーで事前ソートしておくと、特に大きなバッチの場合に ClickHouse でのインジェスト効率を向上できます。
事前ソートされたデータが到着すると、ClickHouse はパーツ作成時の内部ソート処理の一部をスキップまたは単純化でき、CPU 使用量を削減しつつ INSERT 処理を高速化できます。事前ソートは圧縮効率も高めます。同種の値がまとまることで、LZ4 や ZSTD のようなコーデックがより良い圧縮率を達成できるためです。これは、大きなバッチ INSERT と圧縮を組み合わせた場合に特に有効で、処理オーバーヘッドと転送データ量の両方を削減します。
とはいえ、事前ソートは必須ではなくオプションの最適化に過ぎません。 ClickHouse は並列処理を用いてデータを非常に効率的にソートでき、多くのケースではサーバー側でソートした方が、クライアント側で事前ソートするよりも高速、あるいは扱いやすい場合があります。
事前ソートは、データがすでにほぼソート済みである場合や、クライアント側リソース(CPU、メモリ)に十分な余裕があり有効活用できていない場合にのみ推奨します。 オブザーバビリティのように、レイテンシに厳しい、あるいは高スループットなユースケースで、データが順不同で到着したり多数のエージェントから到着したりする場合には、事前ソートは行わず、ClickHouse による組み込みの高パフォーマンスに任せる方がよいことが多くあります。
非同期 INSERT
ClickHouse における非同期 INSERT は、クライアント側でバッチ処理ができない場合の強力な代替手段です。これは特にオブザーバビリティ系ワークロードで有用であり、数百〜数千のエージェントがログ・メトリクス・トレースなどのデータを、小さいリアルタイムペイロードで継続的に送信するケースでよく発生します。このような環境でクライアント側にデータをバッファリングすると複雑性が増し、十分なサイズのバッチを送信するための集中キューが必要になります。
同期モードで小さなバッチを多数送信することは推奨されません。多くのパーツが作成されてしまい、クエリパフォーマンスの低下や "too many part" エラーの原因となります。
非同期 INSERT は、受信データをインメモリバッファに書き込み、その後設定可能なしきい値に基づいてストレージにフラッシュすることで、バッチ処理の責任をクライアントからサーバー側へ移します。このアプローチによりパーツ作成のオーバーヘッドが大幅に削減され、CPU 使用率が低下し、高い並行性の下でもインジェスト効率を維持できます。
コアとなる挙動は async_insert 設定で制御されます。
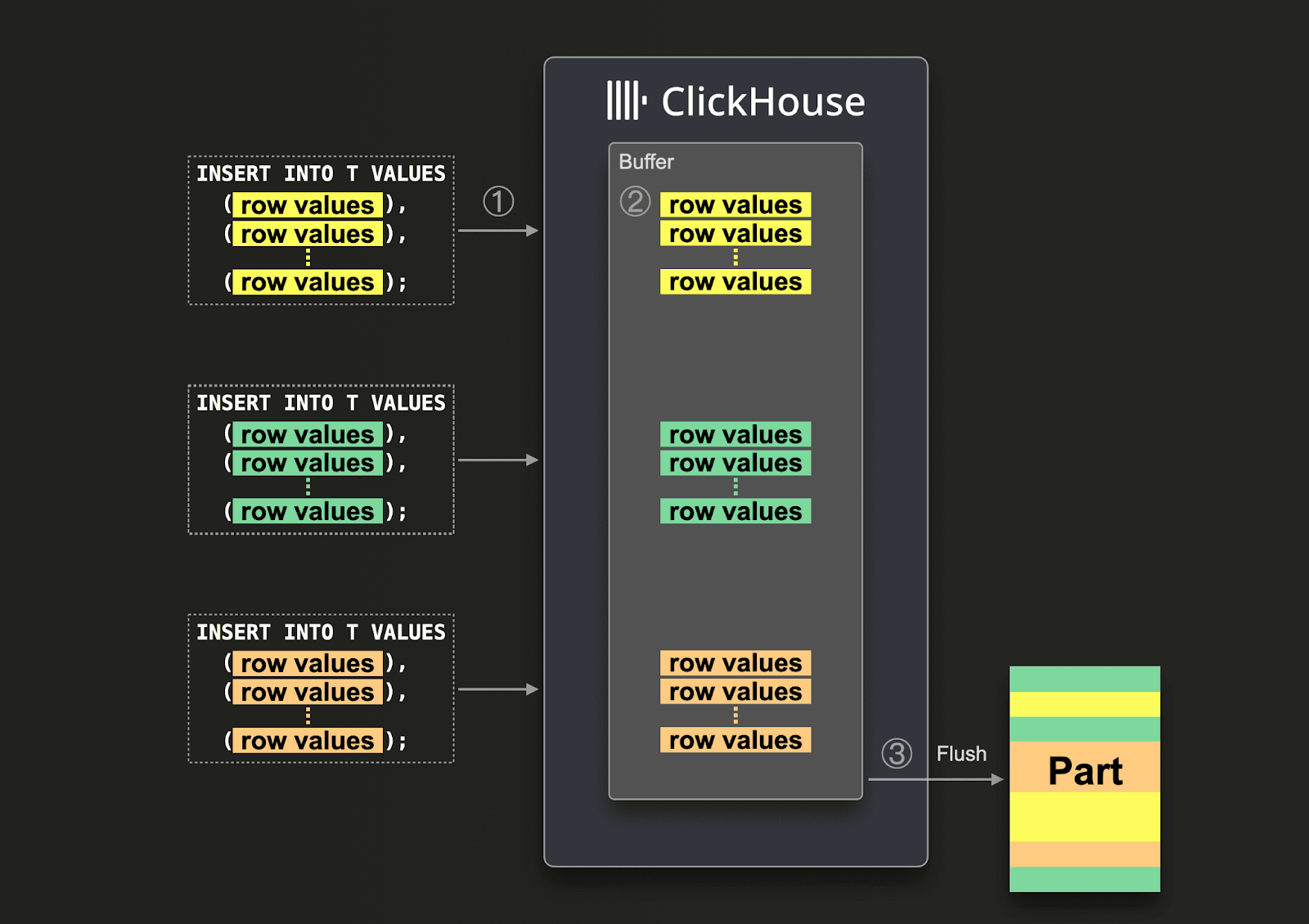
非同期 INSERT は、HTTP とネイティブ TCP の両方のインターフェイスでサポートされています。
有効化 (async_insert = 1) されると、INSERT はバッファリングされ、次のいずれかのフラッシュ条件を満たしたときにのみディスクへ書き込まれます。
- バッファが指定されたデータサイズに達した場合 (
async_insert_max_data_size、デフォルトは 100 MiB) 。 - 時間しきい値が経過した場合 (
async_insert_busy_timeout_ms、デフォルトは 200 ms、Cloud では 1000 ms) 。 - INSERT クエリ数が最大値に達した場合 (
async_insert_max_query_number、デフォルトは 450) 。
最初に到達したしきい値によってフラッシュがトリガーされます。
このバッチ処理はクライアントからは見えず、ClickHouse が複数のソースからの INSERT トラフィックを効率的にマージするのに役立ちます。ただし、フラッシュが発生するまではデータをクエリすることはできません。重要な点として、INSERT の形状 (クエリパターン) と設定の組み合わせごとに複数のバッファが存在し、クラスターではノードごとにバッファが維持されます。これにより、マルチテナント環境全体でのきめ細かな制御が可能になります。INSERT のメカニズム自体は、同期 INSERT で説明されているものと同一です。
戻り値モードの選択
非同期 INSERT の挙動は、wait_for_async_insert 設定によってさらに細かく制御されます。
1 (デフォルト) に設定すると、ClickHouse はデータがディスクへ正常にフラッシュされた後にのみ INSERT を確認 (ACK) します。これにより強い永続性保証が得られ、エラーハンドリングも単純になります。フラッシュ中に何か問題が発生した場合は、そのエラーがクライアントに返されます。このモードは、特に INSERT 失敗を確実に追跡する必要があるほとんどの本番シナリオで推奨されます。
ベンチマーク によれば、このモードは並行度に対して高いスケーラビリティを示しており、200 クライアントでも 500 クライアントでも、アダプティブ INSERT と安定したパーツ作成挙動のおかげで良好に動作します。
wait_for_async_insert = 0 に設定すると、「fire-and-forget」モードが有効になります。この場合、サーバーはデータがバッファに格納された時点で INSERT を確認し、ストレージに到達するのを待ちません。
これは超低レイテンシな INSERT と最大限のスループットを提供し、高速かつ重要度の低いデータに理想的です。しかし、その代償として、データが永続化される保証はなく、エラーはフラッシュ時にしか表面化せず、失敗した INSERT のためのデッドレターキューもありません。失敗の追跡には、事後的にサーバーログと system テーブルを調査する必要があります。このモードは、ワークロードがデータ損失を許容できる場合にのみ使用してください。
ベンチマークではさらに、バッファフラッシュの頻度が低い場合 (例: 30 秒ごと) に、パーツの大幅な削減と CPU 使用率の低下が示されていますが、見えない形で失敗が発生するリスクは依然として残ります。
非同期 INSERT を使用する場合、async_insert=1,wait_for_async_insert=1 を使用することを強く推奨します。wait_for_async_insert=0 の使用は非常にリスクが高く、INSERT クライアントがエラーを認識できない可能性があるうえに、ClickHouse サーバー側が書き込みを減速させてバックプレッシャーをかけ、サービスの信頼性を確保する必要がある状況でも、クライアントが高速な書き込みを継続してしまい、潜在的な過負荷を引き起こす可能性があります。
適応型非同期 INSERT
バージョン 24.2 以降、ClickHouse ではデフォルトで適応型フラッシュタイムアウト (async_insert_use_adaptive_busy_timeout) が使用されます。固定のフラッシュ間隔ではなく、流入するデータレートに応じて、タイムアウトが最小値 (async_insert_busy_timeout_min_ms、デフォルトは 50 ms) から最大値 (async_insert_busy_timeout_max_ms、デフォルトは 200 ms、Cloud では 1000 ms) まで動的に調整されます。
データが頻繁に到着する場合、タイムアウトは最小値寄りに保たれるため、より早くフラッシュされ、エンドツーエンドのレイテンシを低減できます。データがスパースな場合は、より大きなバッチを蓄積するため、最大値に近づく方向に伸びます。これは特にデフォルトモード (wait_for_async_insert=1) で有効です。固定で大きなタイムアウトを設定すると、フラッシュ可能な状態になっていても、クライアントはその間隔が終わるまでブロックされてしまうためです。
エラーハンドリング
schema の検証とデータの解析は、insert を受信した時点ではなく、バッファのフラッシュ時に行われます。insert クエリ内のいずれかの行に解析エラーまたは型エラーがある場合、そのクエリのデータは一切フラッシュされません。つまり、クエリ全体のペイロードが拒否されます。デフォルトモード (wait_for_async_insert=1) では、エラーがクライアントに返されます。fire-and-forget モードでは、エラーはサーバーログと system.asynchronous_inserts テーブルに書き込まれます。
フラッシュのたびに、バッファ内の異なるパーティションキー値ごとに少なくとも 1 つのパーツが作成されます。パーティションキーのないテーブルでも、バッファされたデータが max_insert_block_size (デフォルトは約 100 万行) を超える場合、1 回のフラッシュで複数のパーツが生成されることがあります。
非同期 insert を使用していても、パーティションキーのカーディナリティが高い場合は、"too many parts" エラーが発生することがあります。
重複排除と信頼性
デフォルトでは、ClickHouse は同期 INSERT に対して自動重複排除を行い、失敗時のリトライを安全にします。しかし、これは非同期 INSERT では明示的に有効化しない限り無効になっています (依存するマテリアライズドビューがある場合は有効化すべきではありません — issue を参照) 。
実際には、重複排除が有効で同一の INSERT がリトライされた場合 (タイムアウトやネットワーク切断などが原因) 、ClickHouse は重複を安全に無視できます。これにより冪等性が維持され、データの二重書き込みを回避できます。
非同期 INSERT の有効化
非同期 INSERT は、特定のユーザー、または特定のクエリに対して有効にできます。
-
ユーザーレベルで非同期 INSERT を有効にします。この例ではユーザー
defaultを使用しています。別のユーザーを作成している場合は、そのユーザー名に置き換えてください: -
INSERT クエリのSETTINGS句を使用して、非同期 INSERT の設定を指定できます: -
ClickHouse のプログラミング言語クライアントを使用する場合、接続パラメータとして非同期 INSERT の設定を指定することもできます。
例として、ClickHouse Cloud に接続するために ClickHouse Java JDBC ドライバーを使用する場合、JDBC 接続文字列内で次のように指定できます:
非同期 INSERT は INSERT INTO ... SELECT クエリには適用されません。INSERT に SELECT 句が含まれている場合、async_insert 設定に関係なく、そのクエリは常に同期的に実行されます。
シャットダウン時にバッファをフラッシュする
保留中の非同期 INSERT バッファをすべてフラッシュするには、たとえばグレースフルシャットダウン時やメンテナンス前に、次を実行します。
これにより、サーバーが停止する前に、バッファリングされたデータはすべてストレージに書き込まれます。
バッファテーブルとの比較
非同期 INSERT は、Buffer tables に代わる現在の標準的な方式です。主な違いは次のとおりです。
- DDL の変更は不要です。 非同期 INSERT は透過的で、追加のテーブルを作成する必要はなく、設定を有効にするだけです。
- クエリ形状ごとのバッファリング。 非同期 INSERT は、一意のクエリ形状と設定の組み合わせごとに個別のバッファを維持するため、きめ細かなフラッシュポリシーを適用できます。バッファテーブルは、対象テーブルごとに 1 つのバッファを使用します。
- 耐久性。 デフォルトモード (
wait_for_async_insert=1) では、クライアントが確認応答を受け取る前に、データがディスクに書き込まれたことが確認されます。バッファテーブルは fire-and-forget 型で動作するため、クラッシュ時にはバッファされたデータが失われます。 - クラスターでの動作。 クラスターでは、非同期 INSERT のバッファはノードごとに維持されます。バッファテーブルは、各ノードで明示的に作成する必要があります。
インターフェースを選択する — HTTP かネイティブか
ネイティブ
ClickHouse はデータのインジェスト用に 2 つの主要なインターフェース、ネイティブインターフェース と HTTP インターフェース を提供しており、それぞれにパフォーマンスと柔軟性のトレードオフがあります。clickhouse-client や Go、C++ などの一部の言語クライアントで使用されるネイティブインターフェースは、パフォーマンスを重視して設計されています。常に ClickHouse の高効率な Native 形式でデータを送信し、LZ4 または ZSTD によるブロック単位の圧縮をサポートし、パースやフォーマット変換などの処理をクライアント側にオフロードすることでサーバー側の処理を最小限に抑えます。
さらに、MATERIALIZED および DEFAULT 列値をクライアント側で計算できるため、サーバーはこれらのステップを完全に省略できます。これにより、効率性が重要となる高スループットなインジェストシナリオにおいて、ネイティブインターフェースは理想的な選択となります。
HTTP
多くの従来型データベースとは異なり、ClickHouse は HTTP インターフェースもサポートしています。こちらは対照的に、互換性と柔軟性を優先します。 サポートされている任意の形式 — JSON、CSV、Parquet など — でデータを送信でき、Python、Java、JavaScript、Rust を含むほとんどの ClickHouse クライアントで広くサポートされています。
トラフィックをロードバランサー経由で容易に切り替え・振り分けできるため、これは ClickHouse のネイティブプロトコルより望ましい場合がよくあります。ネイティブプロトコルの方がオーバーヘッドがわずかに少ないため、INSERT パフォーマンスには小さな差が出ると想定されます。
しかし、HTTP インターフェースにはネイティブプロトコルのような深い統合はなく、マテリアライズド値の計算や Native 形式への自動変換といったクライアント側の最適化は行えません。HTTP による挿入でも標準的な HTTP ヘッダー(例: Content-Encoding: lz4)を使って圧縮できますが、圧縮は個々のデータブロックではなくペイロード全体に対して適用されます。このインターフェースは、プロトコルの単純さ、ロードバランシング、幅広い形式との互換性が、生のパフォーマンスよりも重要となる環境で選好されることが多くあります。
これらのインターフェースのより詳細な説明については、こちらを参照してください。
