Introduction
ClickHouse Connect is a core database driver providing interoperability with a wide range of Python applications.
- The main interface is the
Clientobject in the packageclickhouse_connect.driver. That core package also includes assorted helper classes and utility functions used for communicating with the ClickHouse server and "context" implementations for advanced management of insert and select queries. - The
clickhouse_connect.datatypespackage provides a base implementation and subclasses for all non-experimental ClickHouse datatypes. Its primary functionality is serialization and deserialization of ClickHouse data into the ClickHouse "Native" binary columnar format, used to achieve the most efficient transport between ClickHouse and client applications. - The Cython/C classes in the
clickhouse_connect.cdriverpackage optimize some of the most common serializations and deserializations for significantly improved performance over pure Python. - There is a SQLAlchemy dialect in the package
clickhouse_connect.cc_sqlalchemywhich is built off of thedatatypesanddbipackages. This implementation supports SQLAlchemy Core functionality includingSELECTqueries withJOINs (INNER,LEFT OUTER,FULL OUTER,CROSS),WHEREclauses,ORDER BY,LIMIT/OFFSET,DISTINCToperations, lightweightDELETEstatements withWHEREconditions, table reflection, and basic DDL operations (CREATE TABLE,CREATE/DROP DATABASE). While it doesn't support advanced ORM features or advanced DDL features, it provides robust query capabilities suitable for most analytical workloads against ClickHouse's OLAP-oriented database. - The core driver and ClickHouse Connect SQLAlchemy implementation are the preferred method for connecting ClickHouse to Apache Superset. Use the
ClickHouse Connectdatabase connection, orclickhousedbSQLAlchemy dialect connection string.
This documentation is current as of the clickhouse-connect release 0.9.2.
The official ClickHouse Connect Python driver uses the HTTP protocol for communication with the ClickHouse server. This enables HTTP load balancer support and works well in enterprise environments with firewalls and proxies, but has slightly lower compression and performance compared to the native TCP-based protocol, and lacks support for some advanced features like query cancellation. For some use cases, you may consider using one of the Community Python drivers that use the native TCP-based protocol.
Requirements and compatibility
| Python | Platform¹ | ClickHouse | SQLAlchemy² | Apache Superset | Pandas | Polars | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.x, <3.9 | ❌ | Linux (x86) | ✅ | <25.x³ | 🟡 | <1.4.40 | ❌ | <1.4 | ❌ | ≥1.5 | ✅ | 1.x | ✅ |
| 3.9.x | ✅ | Linux (Aarch64) | ✅ | 25.x³ | 🟡 | ≥1.4.40 | ✅ | 1.4.x | ✅ | 2.x | ✅ | ||
| 3.10.x | ✅ | macOS (x86) | ✅ | 25.3.x (LTS) | ✅ | ≥2.x | ✅ | 1.5.x | ✅ | ||||
| 3.11.x | ✅ | macOS (ARM) | ✅ | 25.6.x (Stable) | ✅ | 2.0.x | ✅ | ||||||
| 3.12.x | ✅ | Windows | ✅ | 25.7.x (Stable) | ✅ | 2.1.x | ✅ | ||||||
| 3.13.x | ✅ | 25.8.x (LTS) | ✅ | 3.0.x | ✅ | ||||||||
| 25.9.x (Stable) | ✅ |
¹ClickHouse Connect has been explicitly tested against the listed platforms. In addition, untested binary wheels (with C optimization) are built for all architectures supported by the excellent cibuildwheel project. Finally, because ClickHouse Connect can also run as pure Python, the source installation should work on any recent Python installation.
²SQLAlchemy support is limited to Core functionality (queries, basic DDL). ORM features aren't supported. See SQLAlchemy Integration Support docs for details.
³ClickHouse Connect generally works well with versions outside the officially supported range.
Installation
Install ClickHouse Connect from PyPI via pip:
pip install clickhouse-connect
ClickHouse Connect can also be installed from source:
git clonethe GitHub repository.- (Optional) run
pip install cythonto build and enable the C/Cython optimizations cdto the project root directory and runpip install .
Support policy
Please update to the latest version of ClickHouse Connect before reporting any issues. Issues should be filed in the GitHub project. Future releases of ClickHouse Connect are intended be compatible with actively supported ClickHouse versions at the time of release. Actively supported versions of ClickHouse server can be found here. If you're unsure what version of ClickHouse server to use, read this discussion here. Our CI test matrix tests against the latest two LTS releases and the latest three stable releases. However, due to the HTTP protocol and minimal breaking changes between ClickHouse releases, ClickHouse Connect generally works well with server versions outside the officially supported range, though compatibility with certain advanced data types may vary.
Basic usage
Gather your connection details
To connect to ClickHouse with HTTP(S) you need this information:
| Parameter(s) | Description |
|---|---|
HOST and PORT | Typically, the port is 8443 when using TLS or 8123 when not using TLS. |
DATABASE NAME | Out of the box, there is a database named default, use the name of the database that you want to connect to. |
USERNAME and PASSWORD | Out of the box, the username is default. Use the username appropriate for your use case. |
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select a service and click Connect:
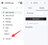
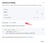
Choose HTTPS. Connection details are displayed in an example curl command.
If you're using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
Establish a connection
There are two examples shown for connecting to ClickHouse:
- Connecting to a ClickHouse server on localhost.
- Connecting to a ClickHouse Cloud service.
Use a ClickHouse Connect client instance to connect to a ClickHouse server on localhost:
Use a ClickHouse Connect client instance to connect to a ClickHouse Cloud service:
Use the connection details gathered earlier. ClickHouse Cloud services require TLS, so use port 8443.
Interact with your database
To run a ClickHouse SQL command, use the client command method:
To insert batch data, use the client insert method with a two-dimensional array of rows and values:
To retrieve data using ClickHouse SQL, use the client query method:
